
A QlikView script is made up of a sequence of statements. These statements are typically used to either manipulate the data, or to conditionally control the way in which the script is executed. For example, we may want to combine two tables together, or skip over a part of a script if a condition is not met.
It is important to note that QlikView script is executed in a sequential order. This means that script is executed top to bottom, and left to right.
In Chapter 3, Seeing is Believing, we started building a small QlikView document to analyze airline operations data. We loaded a fact table and some dimension tables. All this data was loaded from QVD files, without any need for modifications. Of course, this is a scenario that you are not likely to encounter in the real world. In this example we will look at a scenario that is a little more plausible, l focusing on the Aircraft Type dimension. Instead of a single, tidy Aircraft dimension, there are multiple source files:
Aircraft_Base_File.csv: This file contains information on airplanes that were in the database up to and including 2009Aircraft_2010_Update.csv: This is an update file containing airplanes that were added to the database since 2010Aircraft_Group.csv: This file contains attributes used to group airplanes; the type of engine and the number of engines
Take a minute to look through the CSV files. Notice that the column AC_GROUP in the Aircraft_Base_File.csv file references the column Aircraft Group ID in the Aircraft_Group.csv file. The format of the Aircraft_2010_Update.csv file is almost identical to the Aircraft_Base_file.csv file, but instead of an AC_GROUP column it has an AC_GROUPNAME column. This column contains a concatenated string with the engine type and number of engines.
Once you are done reviewing these source files, let's look at the steps involved in building the aircraft dimension script.
Load the Aircraft information into QlikView by following these steps:
- Open the Airline Operations.qvw document we saved in the previous chapter and press Ctrl + E to open the script editor.
- On the Data tab of the tool pane, make sure the Relative Paths checkbox is enabled.
- Go the Aircrafts tab and delete all script from the tab.
- Click the Table Files button in the tool pane and navigate to the
Data FilesCSVsfolder. - Select the file
Aircraft_Base_File.csv. - Rename the fields by clicking on the column headers and replacing the text as follows:
Original name
New name
AC_TYPEID%Aircraft Type IDAC_GROUP%Aircraft Group TypeSSD_NAMEAircraft NameMANUFACTURERAircraft ManufacturerLONG_NAMEAircraft Name FullSHORT_NAMEAircraft Name AbbreviatedBEGIN_DATEAircraft Begin DateEND_DATEAircraft End Date - Complete the Table File Wizard window by clicking on Finish.
- Replace the Directory; text with
[Aircraft Types]:, this will assign that name to the table.The resulting code should look as follows:
[Aircraft Types]: LOAD AC_TYPEID as [%Aircraft Type ID], AC_GROUP as [%Aircraft Group Type], SSD_NAME as [Aircraft Name], MANUFACTURER as [Aircraft Manufacturer], LONG_NAME as [Aircraft Name Full], SHORT_NAME as [Aircraft Name Abbreviated], BEGIN_DATE as [Aircraft Begin Date], END_DATE as [Aircraft End Date] FROM [..Data FilesCSVsAircraft_Base_File.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq);
Note how the source filename and path are specified in a relative manner, that is, the location of the source file relative to the QlikView document. This happens because we enabled the Relative Paths checkbox. Had we disabled the checkbox, the full path and file name would have been used. For example, using relative paths is convenient when your document will be moved around from a development to a production environment.
Take a minute to review the rest of the script and see if your script matches.
The next step is to enrich the Aircraft type data by adding the data from the Aircraft_Group.csv file to it. To do this, follow these steps:
- Place the cursor below the last line of the Aircraft Types load statement.
- Click on the Table Files button in the tool pane and navigate to the
Data FilesCSVsfolder. - Select the file
Aircraft_Group.csv. - Notice that the headers in this file are not automatically detected by QlikView.
- Change the value of the Labels dropdown box to Embedded Labels.
- Notice that the key column Aircraft Group ID does not match the name we've given to the corresponding column in the
Aircraft Typestable. Correct this by changing the name of the column to%Aircraft Group Type. - Complete the Table File Wizard window by clicking on Finish.
- Replace the Directory; text with
[Aircraft Groups]:to assign that name to the table. - Save the document by pressing the Save icon on the toolbar, Ctrl + S, or by selecting File | Save Entire Document.
The resulting code should look like this:
[Aircraft Groups]: LOAD [Aircraft Group ID] as [%Aircraft Group Type], [Aircraft Engine Type], [Aircraft Number Of Engines] FROM [..Data FilesCSVsAircraft_Group.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq);
Tip
Better "Save" than sorry
By default, when QlikView encounters errors during the reload of a document, it automatically closes the document and reloads the last saved version of the file. It can be a frustrating experience when you have just written a lot of script, only to see all of it lost because you forgot a semicolon somewhere.
One way to avoid this problem is by always first saving your script before reloading. This can be done by going to File | Save Entire Document from the menu, by pressing Ctrl + S, or by clicking on the Save icon in the toolbar.
Another more fail-safe way is to set QlikView to automatically save the file before each reload. To do this, close the script editor and open the User Preferences menu by selecting Settings | User Preferences from the menu, or by pressing Ctrl + Alt + U. In the menu, select the Save tab and tick the checkbox labeled Save Before Reload. It is also advisable to tick the checkbox Use Backup and set the field Keep Last Instances to 5. This last option ensures that the last 5 versions of the QlikView file are kept.
To run the script and see what the result is, follow these steps:
- Select File | Reload, press Ctrl + R, or click the Reload button on the toolbar to reload the script.
- When the script has finished loading you will see the Sheet Properties dialog, click on OK to close it.
You will notice that two of our list boxes have gone missing, Aircraft Group and Aircraft Type. This has happened because the fields that were used for these list boxes were removed from the data model.

Let's remove the two list boxes and replace them with a single Aircraft multibox, by following these steps:
- Right-click on the list box labeled (unavailable)[Aircraft Group] and select Remove. As this is a linked object, select Delete All to remove the object from all sheets.
- Repeat the previous step for the list box labeled (unavailable)[Aircraft Type].
- Create a new multibox and add the Aircraft Name, Aircraft Engine Type, and Aircraft Number of Engines fields.
- Style the multibox to look like the following image and position it below the Carrier Name list box.

- Add the multibox to the Analysis and Reports sheets as a linked object by holding Ctrl + Shift while dragging the multibox onto the respective tabs.
- Verify that the data is associated by selecting the Name field from the Aircraft multibox and checking if the Engine Type and Number of Engines drop-down lists are being updated.
Now that we have loaded these two tables, let's load the final file, Aircraft_2010_Update.csv, into QlikView. Remember that this file is very similar to the Aircraft_Base_File.csv file. The only difference is that there is no ID for an Aircraft Group, just the actual Aircraft Group Name. We will load the file by following these steps:
- Place the cursor below the last line of the current script.
- Click on the Table Files button in the tool pane and navigate to the
Data FilesCSVsfolder. - Select the file
Aircraft_2010_Update.csv. - With the exception of
AC_GROUPNAME, rename the fields in the following manner.Original name
New name
AC_TYPEID%Aircraft Type IDSSD_NAMEAircraft NameMANUFACTURERAircraft ManufacturerLONG_NAMEAircraft Name FullSHORT_NAMEAircraft Name AbbreviatedBEGIN_DATEAircraft Begin DateEND_DATEAircraft End Date - Complete the Table File Wizard window by clicking on Finish.
- Replace the Directory; text with
[Aircraft Types 2010]:to assign that name to the table. - If you did not turn on automatic saving, save the document by selecting File | Save Entire Document from the menu or by pressing Ctrl + S.
The resulting script should look like this:
[Aircraft Types 2010]: LOAD AC_TYPEID as [%Aircraft Type ID], AC_GROUPNAME, SSD_NAME as [Aircraft Name], MANUFACTURER as [Aircraft Manufacturer], LONG_NAME as [Aircraft Name Full], SHORT_NAME as [Aircraft Name Abbreviated], BEGIN_DATE as [Aircraft Begin Date], END_DATE as [Aircraft End Date] FROM [..Data FilesCSVsAircraft_2010_Update.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq); - Reload the document by selecting File | Reload from the menu, or by pressing Ctrl + R.
- Once the script is finished, click on OK to close the Sheet Properties [Dashboard] dialog.
- Add the fields
AC_GROUPNAMEandAircraft Begin Dateto the Aircraft multibox.
When we interact with the Aircraft multibox, we notice that something strange is going on. There are three fields with overlapping information. AC_GROUPNAME contains information that is also shown in the Engine Type and Number of Engines drop-down lists. When we interact with the data, we will notice that any aircraft that has an Aircraft Begin Date field before 2010 is associated with the Engine Type and Number of Engines fields, while later models are associated with the AC_GROUPNAME field.
When we open the table viewer we notice that the data model contains a synthetic key table named $Syn1. We were introduced to synthetic keys in Chapter 5, Data Modeling. In the next section we will see a practical example of how to resolve this issue.

Remember how QlikView's associative logic works? It automatically associates fields that have the same name. And those associations between tables can only be based on a single field. Well, the Aircraft Types and Aircraft Types 2010 tables that we loaded contain seven fields that match between these tables. To resolve this issue QlikView created a synthetic key by creating a key for each unique combination of the seven fields.
We will solve the problem by merging all these tables into a single Aircraft Types dimension table. The following schematic shows the general approach we will be taking.

We will begin by joining the Aircraft Groups table to the Aircraft Types table. We will then concatenate (or union, for SQL connoisseurs) the Aircraft Types 2010 table to the result we got by joining the Aircraft Groups table to the Aircraft Types table. To achieve this, we follow these steps:
- Go back to the script editor by pressing Ctrl + E or by selecting File | Edit Script from the menu.
- Go to the
LOADstatement for the fileAircraft_Group.csvand replace the text[Aircraft Groups]:with the textLEFT JOIN ([Aircraft Types]). - Next, go to the
LOADstatement for the fileAircraft_2010_Update.csvand replace the text[Aircraft Types 2010]:with the textCONCATENATE([Aircraft Types]). - Replace the line reading
AC_GROUPNAME,withSubField(AC_GROUPNAME, ', ', 1) as [Aircraft Engine Type],and press Return to create a new line. - On this new line enter
SubField(AC_GROUPNAME, ', ', 2) as [Aircraft Number Of Engines],. - Beneath the
LOADstatement for the fileAircraft_Group.csvadd the following code:DROP FIELD [%Aircraft Group Type] FROM [Aircraft Types];.The finished code should look like this:
[Aircraft Types]: LOAD AC_TYPEID as [%Aircraft Type ID], AC_GROUP as [%Aircraft Group Type], SSD_NAME as [Aircraft Name], MANUFACTURER as [Aircraft Manufacturer], LONG_NAME as [Aircraft Name Full], SHORT_NAME as [Aircraft Name Abbreviated], BEGIN_DATE as [Aircraft Begin Date], END_DATE as [Aircraft End Date] FROM [..Data FilesCSVsAircraft_Base_File.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq); LEFT JOIN ([Aircraft Types]) LOAD [Aircraft Group ID] as [%Aircraft Group Type], [Aircraft Engine Type], [Aircraft Number Of Engines] FROM [..Data FilesCSVsAircraft_Group.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq); DROP FIELD [%Aircraft Group Type] FROM [Aircraft Types]; CONCATENATE([Aircraft Types]) LOAD AC_TYPEID as [%Aircraft Type ID], SubField(AC_GROUPNAME, ', ', 1) as [Aircraft Engine Type], SubField(AC_GROUPNAME, ', ', 2) as [Aircraft Number Of Engines], SSD_NAME as [Aircraft Name], MANUFACTURER as [Aircraft Manufacturer], LONG_NAME as [Aircraft Name Full], SHORT_NAME as [Aircraft Name Abbreviated], BEGIN_DATE as [Aircraft Begin Date], END_DATE as [Aircraft End Date] FROM [..Data FilesCSVsAircraft_2010_Update.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq);
The following changes were made:
- By adding the
LEFT JOIN ([Aircraft Types])statement, we tell QlikView not to load the data from theAircraft_Group.csvfile to a separate table. Instead, it will be joined to the table specified between the parentheses. A join is made over the common fields between both tables, in this case[%Aircraft Group Type]. - By adding the
CONCATENATE ([Aircraft Types])statement, we tell Qlikview not to load the data from theAircraft_2010_Update.csvfile to a separate table. Instead, the rows are appended to the table specified between the parentheses. Fields that are not shared between tables, for example, the field[%Aircraft Group Type], get null values for the rows that are missing this field. - The
AC_GROUPNAMEcolumn contains both the Engine Type and Number of Engines fields, separated by a comma. TheSubField(AC_GROUPNAME, ',', 1) as [Engine Type],expression uses theSubFieldfunction to split theAC_GROUPNAMEstring into subfields based on the','delimiter. The first subfield returns the Aircraft Engine Type table, the second subfield returns the Aircraft Number of Engines table. - As we no longer require the
[%Aircraft Group Type]key field, theDROP FIELD [%Aircraft Group Type] FROM [Aircraft Types];statement is used to remove it from the Aircraft Types table.
To see the effect of our changes, let's reload the script by selecting File | Reload from the menu, or by pressing Ctrl + R.
After reloading has finished, open the Table Viewer window by selecting File | Table Viewer from the menu, or by pressing Ctrl + T.

As we can see, all the source tables have been merged into a single Aircraft Types dimension table.
Now that we have seen an example of how QlikView script statements and functions can be used to load and combine data, let's look at some of the most common script statements for manipulating tables.
As we saw in earlier chapters, the LOAD statement is the main statement used to load data into QlikView.
The script we created in this chapter showed us two statements that can be used to combine data from different tables: JOIN and CONCATENATE. We will now look at these statements and others in some more detail.
The JOIN statement is a prefix to the LOAD statement. It is used to join the table that is being loaded to a previously loaded table. The two tables are joined using a
natural join, this means that the columns in both tables are compared and the join is made over those columns that have the same column names. This means that if multiple columns are shared between tables, the match will be made over the distinct combinations of those columns.
By default, QlikView performs an outer join. This means that the rows for both tables are included in the resulting table. When rows do not have a corresponding row in the other table, the missing columns are assigned null values.
Let us consider the following two tables:
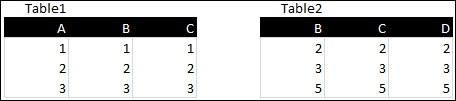
These two tables share two columns, B and C. Then we use the following code to perform a regular join:
Table1: LOAD * INLINE [ A, B, C 1, 1, 1 2, 2, 2 3, 3, 3 ]; JOIN LOAD * INLINE [ B, C, D 2, 2, 2 3, 3, 3 5, 5, 5 ];
The result is the following table:

As you can see, the overlapping columns, B and C, have been merged into single columns, and the fields A and D have been added from both tables. It is important to note that, as the second table is being joined to the first the name of the table stays Table1. It is also important to note that the rows that could not be joined, the first and the last, get null values for the missing values.
Tip
Make it explicit
When using just the bare JOIN statement, the join will be made to the table loaded directly before the JOIN statement. If the table to join to was loaded somewhere earlier in the script, that table can be joined to by supplying its name in parentheses. In our example this would be achieved by replacing JOIN with JOIN (Table1). From the perspective of keeping our code easy to understand, it is preferable to always supply the name of the table to join to. While the load statement for the table to join to may be directly above now, this may change in the future. When that happens, the join is suddenly targeting another table.
The JOIN statement can be prefixed with the statements INNER, OUTER, LEFT, and RIGHT, which performs an inner, outer, left, or right join respectively. This has the following results:
INNER JOIN: Only rows that can be matched between both tables will be kept in the result.OUTER JOIN: All rows will be kept in the result, rows that do not have a corresponding value in the other table will get null values for the fields that are unique to that table. When no prefix is specified, this is the default join type that will be used.LEFT JOIN: All rows from the first table and those rows from the second table that have a corresponding key in the first table, will be included in the result. When no match is found, null values will be shown for the columns that are unique to the second table.RIGHT JOIN: All rows from the second table and those rows from the first table which have a corresponding key in the second table, will be included in the result. When no match is found, null values will be shown for the columns that are unique to the first table.
Applied to our example tables, the results would be:

The KEEP statement works in the same way that the JOIN statement does, with a small difference. Instead of joining the result in a single table, the KEEP statement keeps both original tables and filters (keeps) rows in one table based on matching rows in another table. The same logic for INNER, OUTER, LEFT, and RIGHT KEEP applies here as did with the JOIN statement.
Let us consider the same two tables from the JOIN example:

If we apply a LEFT KEEP statement to these two tables, like shown in the following code:
Table1: LOAD * INLINE [ A, B, C 1, 1, 1 2, 2, 2 3, 3, 3 ]; Table2: LEFT KEEP (Table1) LOAD * INLINE [ B, C, D 2, 2, 2 3, 3, 3 5, 5, 5 ];
The result we get is the following two tables. As you can see, the last row from the original Table2 has been filtered out as it does not correspond to any of the rows in Table1:

The CONCATENATE statement is also a prefix to the LOAD statement, but instead of matching and merging rows between tables, this statement appends the rows of one table to another table.
Let us again consider the same two tables from the previous example:

We use the following code to concatenate the two tables:
Table1: LOAD * INLINE [ A, B, C 1, 1, 1 2, 2, 2 3, 3, 3 ]; CONCATENATE (Table1) LOAD * INLINE [ B, C, D 2, 2, 2 3, 3, 3 5, 5, 5 ];
The result is the following table:

Notice how the rows from the second table were appended to the first table, and that non-matching fields have all been given null values.
When two tables share the exact same columns, QlikView will automatically concatenate them. For example, when looking at the following code we could assume that the result would be two tables, Table1 and Table2.
Table1: LOAD * INLINE [ A, B, C 1, 1, 1 2, 2, 2 3, 3, 3 ]; Table2: LOAD * INLINE [ A, B, C 4, 4, 4 5, 5, 5 6, 6, 6 ];
However, in reality, as both tables share the exact same columns, QlikView will implicitly concatenate Table2 onto Table1. The result of this script is a single table.
We can prevent this from happening by prefixing the LOAD statement for Table2 with the NOCONCATENATE statement. This statement instructs QlikView to create a new table, even if a table with the same columns already exists.
The MAPPING statement provides an alternative to the JOIN statement in a very specific scenario: when you want to replace a single key value with a value from a lookup (mapping) table. To see how this works, let's enrich our Aircraft Types dimension table by adding the manufacturer's country. To do this, we open up the script editor and follow these steps:
- Place the cursor directly above the
LOADstatement for[Aircraft Types]. - Click the Table Files button in the tool pane and navigate to the
Data FilesCSVsfolder. - Select the file
Aircraft_Manufacturers.csv. - Set the Labels drop-down list to Embedded Labels.
- Complete the Table File Wizard by clicking on Finish.
- Replace the Directory; text with
Map_Manufacturer_Country:to assign that name to the table. - On the next line, prefix
MAPPINGto theLOADstatement. - Now add a line below the line
MANUFACTURER as [Aircraft Manufacturer],in the[Aircraft Types] LOADstatement. - On this line add the following script:
ApplyMap('Map_Manufacturer_Country', MANUFACTURER, 'Unknown') as [Aircraft Manufacturer Country],. - Add a line below the line
MANUFACTURER as [Aircraft Manufacturer],in theCONCATENATE([Aircraft Types]) LOADstatement. - On this line add the following script:
ApplyMap('Map_Manufacturer_Country', MANUFACTURER, 'Unknown') as [Aircraft Manufacturer Country],.
The modified script for the mapping table should look as follows:
Map_Manufacturer_Country:
MAPPING LOAD Company,
Country
FROM
[..Data FilesCSVsAircraft_Manufacturers.csv]
(txt, codepage is 1252, embedded labels, delimiter is ';', msq);By prefixing the LOAD statement with the MAPPING statement, we tell QlikView that we want to create a mapping table. This is a specific type of table that has the following properties:
- It can only have two columns, the first being the lookup value and the second being the mapping value to return.
- It is a temporary table. At the end of the script, QlikView automatically removes the table from the data model.
We then used the ApplyMap() function to look up the aircraft manufacturer's country while loading the Aircraft_Base_File.csv and Aircraft_2010_Update.csv files. The ApplyMap() function uses three parameters:
- The name of the mapping table to use, in our case this is the
Map_Manufacturer_Countrytable - The search value, a field value or expression from the source table, that is looked up in the mapping table. We used the
MANUFACTURERfield - An optional value that specifies what value to use when no match is found in the mapping table; here we used the value
Unknown. When no value is specified, the search value is returned.
Let's look at how this affects the data model:
- Save and reload the document.
- After reload is finished, remove the fields
AC_GROUPNAMEandAircraft Begin Datefrom the Aircraft multibox. - Add the
Aircraft ManufacturerandAircraft Manufacturer Countryfields to the Aircraft multibox. - Select the value Unknown from the
Aircraft Manufacturer Countrylist-box.
We will notice that there are four aircraft that have an unknown Aircraft Manufacturer Country field. When we look at the Aircraft Name
The COMMENT statement can be used to add comments to tables and fields. These comments will be shown when hovering the mouse cursor over table and field names in various dialogs and the Table Viewer window, and are a very useful aid for understanding the data.

Comments can be added to a table by using the following code:
COMMENT TABLE [Aircraft Types] WITH 'Dimension containing information on aircrafts, including engine types and configuration and manufacturer';
Fields can be commented in the same manner:
COMMENT FIELD [%Aircraft Type ID] WITH 'Primary key of the Aircraft Type dimension';
Of course, commenting each table and field individually in the script is quite a lot of work. Besides that, we often already have our table and field definitions stored outside of QlikView, why would we want to duplicate work? Fortunately, we do not have to. QlikView has the option to use mapping tables for the table and field comments.
Let's open the script editor and apply comments to our Aircraft Types dimension by following these steps:
- Place the cursor beneath the last line of the
Map_Manufacturer_Countrymapping table. - Click on the Table Files button in the tool pane and navigate to the
Data FilesExcelfolder. - Select the file
Comments.xls. - Check that the Tables drop-down box is set to
Tables$. - Complete the Table File Wizard dialog by clicking on Finish.
- Replace the
Directory;text withMap_Table_Comments:to assign that name to the table. - On the next line, prefix
MAPPINGto theLOADstatement. - Place the cursor beneath the last line of the
Map_Table_Commentsmapping table. - Click on the Table Files button in the tool pane and navigate to the
Data Filesfolder. - Select the file
Comments.xls. - Check that the Tables drop-down box is set to
Fields$. - Complete the Table File Wizard dialog by clicking on Finish.
- Replace the
Directory;text withMap_Field_Comments:to assign that name to the table. - On the next line, prefix
MAPPINGto theLOADstatement. - Place the cursor beneath the last line of the
Map_Field_Commentsmapping table. - Add the following two lines:
COMMENT TABLES USING Map_Table_Comments; COMMENT FIELDS USING Map_Field_Comments;
Our resulting script should look like this:
Map_Table_Comments:
MAPPING LOAD TableName,
Comment
FROM
[..Data FilesExcelComments.xls]
(biff, embedded labels, table is Tables$);
Map_Field_Comments:
MAPPING LOAD FieldName,
Comment
FROM
[..Data FilesExcelComments.xls]
(biff, embedded labels, table is Fields$);
COMMENT TABLES USING Map_Table_Comments;
COMMENT FIELDS USING Map_Field_Comments;We have now created two mapping tables and have instructed QlikView to use these tables to assign comments to the tables and fields, using the COMMENT TABLES and COMMENT FIELDS statements.
When we save and reload our document and open Table Viewer by pressing Ctrl + T, we should see the comments that we loaded when hovering over the fields of the Aircraft Types table.
Now that we have built our Aircraft Type dimension table, we can use it in our QlikView document. In an environment with multiple documents, it is very likely that we will want to re-use the same table in different apps. Fortunately, there is an easy way to export a QlikView table to an external QVD file; the STORE statement.
We can store the Aircraft Types table to a QVD file by adding the following piece of code at the end of our script:
STORE [Aircraft Types] INTO '..Data FilesQVDsAircraftTypesTransformed.qvd' (qvd);
This tells QlikView to store the table [Aircraft Types] into the sub-folder DataFilesQVDs with the filename AircraftTypesTransformed.qvd The .qvd suffix at the end of the statement tells QlikView to use the QVD format. The other option is (txt) to store the table in text format.
Renaming tables or fields in QlikView is done using the RENAME statement. The following code shows some examples of this statement:
RENAME TABLE [Aircraft Types] TO [Aircraft]; RENAME FIELD [%Aircraft Type ID] TO [Aircraft ID]; RENAME FIELD [Aircraft Begin Date] to [Begin], [Aircraft End Date] to [End];
As we can see in the third statement, we can also rename multiple fields within the same statement. We can also rename objects by using a mapping table, just like the one we used for the comments. The following code shows an example:
RENAME TABLES USING Map_Table_Names; RENAME FIELDS USING Map_Field_Names;
Of course, we must not forget to load a mapping table before using this approach.
Deleting tables or fields is done using the DROP statement. The following code shows some examples of dropping table and fields:
DROP TABLE [Aircraft Types]; DROP FIELD [%Aircraft Group Type]; DROP FIELD [%Aircraft Group Type] FROM [Aircraft Types];
The first line deletes the table [Aircraft Types]. The second line deletes the field [%Aircraft Group Type]. The third line also deletes the field [%Aircraft Group Type], but only from the [Aircraft Types] table. If any other tables contain the same field, those are left unaffected.
As we saw in the previous chapter, a variable is a symbolic name that can be used to store a value or expression. Besides the frontend, variables can also be used within QlikView scripts. For example, we may want to use a variable called vDateToday, which we will set to the present day's date in our script:
LET vDateToday = Today();
The Today function is a built-in function that returns the present day's date. Once the variable has been set, we can use its value everywhere in our statements.
QlikView has two statements that can be used to assign a value to a variable, SET and LET. The difference between these two is that the SET statement assigns the literal string to the variable, while the LET statement first evaluates the string before assigning it. This is best illustrated with an example:
|
Statement |
Value of vVariable |
|---|---|
|
|
|
|
|
|
As we have seen before, QlikView script is executed from left to right and from top to bottom. Sometimes, however, we may want to skip certain parts of the script or execute a piece of script a few times in succession. This is where control statements prove useful.
A control statement is a conditional statement whose results determines which path will be followed. Let's open the script editor and follow these steps to conditionally load Main Data based on a variable:
- Select the Main tab.
- At the bottom of the script, add the following expression:
SET vLoadMainData= 'N';
- Select the Main Data tab.
- Before the
Main Data LOADstatement, create a new line that contains the following statement:IF '$(vLoadMainData)' = 'Y' THEN
- At the bottom of the script, add the following statement:
END IF
Now when we reload the script, we will notice that the Main Data table will not be loaded. Only when we change the value of the variable vLoadMainData to Y and reload the script will the Main Data table be included. Also notice that we are using Dollar Sign Expansion in the same way we've used it in the frontend earlier.
The control statement that we used in our example is IF .. THEN .. END IF. This checks If a certain condition is met; if it is, a piece of script is executed. As QlikView needs to know how much of the script should be executed, the statement is ended with END IF.
Other control statements of interest are:
|
Control statement |
Explanation |
Example |
|---|---|---|
|
|
Execute statements |
[executed while
|
|
|
Use a counter to loop over statements. |
[executed for values
|
|
|
Loop over statements for each value in a comma separated list. |
[executed for
|
|
|
Follow a different path based on which condition is met, this is the control statement we used in our example. The |
[executed when
[executed when
[executed when
|
|
|
Execute a different group of statements ( |
[executed when
[executed when
[executed when
|
A special type of control statement is the SUB .. END SUB statement. This defines a subroutine, a piece of script that can be called from other parts of the script. We will look into this in more detail later in the Re-using scripts section of this chapter.