
In Chapter 5, Data Modeling, we started working with data modeling in QlikView and reviewed some guidelines to follow when designing a data model. Now that we have also reviewed how data manipulation via a script can be performed in QlikView, we are ready to expand on both topics and review some best practices to accomplish better and cleaner data model designs. We'll talk about how to overcome common modeling challenges, such as multiple fact tables, and look at various techniques for assuring that our data models are consistent and do not contain unnecessary data. Additionally, we will look at some best practices for dealing with date and time information.
We will learn how to:
- Make sure data models are consistent
- Work with complex data models and multiple fact tables
- Reduce storage requirements for a dataset
- Deal with date and time information
Let's get started!
The first set of best practices that we present on data modeling are those related to data consistency. This is one of the most important things we need to take care of when building QlikView documents. Let's look at some best practices that we can use to assure our data is concise and consistent.
Sometimes, a dimension table can contain values that do not have any associated facts. To demonstrate this, let's take a second look at the data model we built in Chapter 4, Data Sources,and have been using ever sice:
- Open the
Airline Operations.qvwfile. - Launch the Table Viewer by selecting File | Table Viewer or by pressing Ctrl + T.
- Hover the mouse over the
%Aircraft Type IDfield in the Aircraft Types table, pay special attention to the Subset ratio value. - Next, hover the mouse over the
%Aircraft Type IDfield in the Main Data table, again paying special attention to the Subset ratio. What you will notice is that the Aircraft Types dimension table has a subset ratio of 100% for the field%Aircraft Type ID, while the Main Data table only has a 48% subset ratio, seen here: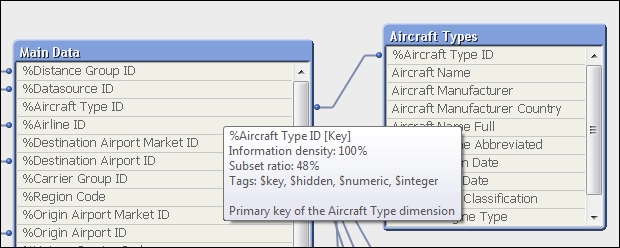
We learned earlier what this means: of all the distinct possible values for %Aircraft Type ID, 100% of those values appear in the Aircraft Types dimension table, while only 48% of the values appear in the Main Data table. In other words, only 48% of aircrafts have actually made any flights.
Before we look at how to remove these aircraft types from the model, let's first quickly investigate which aircraft types have not logged any flights:
- Close the Table Viewer window by clicking on OK.
- Add a new sheet to the document by clicking on the Add Sheet button from the Design toolbar.
- Once the new sheet is created, right-click on the workspace area and select Properties…. Then, from the Sheet Properties window, activate the General tab and change the Title field to Data Consistency.
- Now, navigate to the Fields tab and, from the Available Fields list on the left, highlight the Year field as well as the Aircraft Type field, and click on the Add > button. Then, click on OK and two new listboxes will be created.
- We will now create a Table Box, so right-click on the workspace area again, but this time select New Sheet Object | Table Box…, as seen here:

- From the New Table Box window, enter Flights in the Title box.
- Then highlight the following fields from the Available Fields list and click on the Add > button: %Aircraft Type ID, # Air Time, # Available Seats, # Departures Performed, and # Departures Scheduled.
Remember to press the Ctrl key to highlight multiple fields at once.
- Click on OK.
- Right-click on the Year listbox and click on Select All. Notice that, by association, this reduces the aircraft types list and keeps only those that have logged flights in 2009, 2010, and 2011 (the selected years).
- Now, right-click on the Aircraft Type listbox and click on Select Excluded from the pop-up menu. This will switch our selection to those aircrafts that have not logged flights.
By looking at the Flights table box, shown in the following screenshot, we can see that the selected aircrafts indeed have no flight data associated with them:

Of course, it can be very useful for a business analyst to see which dimensions do not have any fact data associated with them. For that reason, it may be worthwhile to keep this information in the model. Whenever these types of issues present themselves, it is important to check with the business users what their wishes are.
For our example, we will remove the aircraft types that do not have any associated flight data. To do that, follow these steps:
- Open the Script Editor window by selecting File | Edit Script in the menu bar, or by pressing Ctrl + E.
- Go to the Aircrafts tab.
- Locate the following
Loadstatement:[Aircraft Types]: LOAD AC_TYPEID as [%Aircraft Type ID], AC_GROUP as [%Aircraft Group Type], SSD_NAME as [Aircraft Name], MANUFACTURER as [Aircraft Manufacturer], ApplyMap('Map_Manufacturer_Country', MANUFACTURER, 'Unknown') as [Aircraft Manufacturer Country], LONG_NAME as [Aircraft Name Full], SHORT_NAME as [Aircraft Name Abbreviated], BEGIN_DATE as [Aircraft Begin Date], END_DATE as [Aircraft End Date], If(Year(BEGIN_DATE) < 1990, 'Classic', 'Current') as [Aircraft Age Classification] FROM [$(vFolderSourceData)CSVsAircraft_Base_File.csv] (txt, codepage is 1252, embedded labels, delimiter is ';', msq); - From the preceding script, remove the semicolon (
;) at the end and press Return to create a new line. - On the new line, type the following code:
Where Exists([%Aircraft Type ID], AC_TYPEID);
- Now, locate the LOAD statement in which the
Aircraft_2010_Update.csvtable file is being loaded, and add the following Where clause at the end in a similar manner (the final semicolon gets replaced):Where Exists([%Aircraft Type ID], AC_TYPEID);
- Save and Reload the script.
The non-matching aircrafts are no longer in the data model after the reload. The code that we added to the script uses a WHERE clause combined with the Exists() function. We are essentially filtering out any records in which the AC_TYPEID field from the dimension table does not have a corresponding value in the %Aircraft Type ID field already loaded in the Main Data table.
The Exists() function takes two parameters:
WHERE Exists([%Aircraft Type ID], AC_TYPEID);
The first parameter specifies the field on which we need to check to see if there are any occurrences of the values contained in the second field, the one specified in the second parameter.
In some cases, the two fields being compared have the same name in both the input dimension table and the fact table already loaded. If that's the case, we could use a simplified, one-parameter, syntax as follows:
Where Exists([%Aircraft Type ID]);
Depending on how the field names from the input table are defined, we should use the appropriate syntax from the two presented above. The main advantage of the second scenario (one-parameter syntax) is that, when loading from a QVD, it will still perform as an optimized load, while the first scenario will not.
An alternative to using the
Exists() function is the use of the KEEP prefix, which will be added before the LOAD keyword. As shown in the previous chapter, by using LEFT KEEP or RIGHT KEEP, we can limit the records being loaded to those that have a matching key in the already loaded fact table. A benefit of using this prefix is that the result set can be limited on multiple fields, while the Exists() function can only use a single field. However, script processing of the KEEP prefix can be a lot slower on larger data sets, so the Exists()function is the preferred method whenever possible.
Let's take another approach to dealing with this problem this time using the KEEP prefix.
The previous example depends on the fact table being loaded before the dimension tables. It often makes more sense to load dimension tables first and fact tables later. In that scenario, the solution shown before will not work because the actual fact table has not yet been loaded at the time we load the dimension table. There is no way for us to "load only dimension values for which facts have been loaded." Therefore, the Exists() function cannot be used.
The alternative approach consists of first loading the entire dimension table and then reducing the record set based on the corresponding values in the fact table after the facts have been loaded. Let's see how this works by following these steps:
- Open the Script Editor window again and go to the Aircraft tab.
- Comment out the lines we added previously by selecting the code
WHERE Exists([%Aircraft Type ID], AC_TYPEID);right-clicking on it, and selecting Comment. - Then, add a semicolon on the next line to ensure that the
LOADstatement is properly ended. - Next, we need to make sure that the Aircrafts tab is run before the Main Data tab. With the Aircrafts tab still active, press Ctrl + Q,T,P simultaneously twice to promote it, or select Tab | Promote from the menu bar until the Aircrafts tab is placed to the left of the Main Data tab.
- Next, activate the Main Data tab and, after the end of the corresponding
LOADstatement, enter the following code:Temp_Aircraft_Type_Dim: RIGHT KEEP ([Aircraft Types]) LOAD DISTINCT [%Aircraft Type ID] RESIDENT [Main Data]; DROP TABLE Temp_Aircraft_Type_Dim;
- Save and reload the script, and use the Table Viewer window to check the result.
The code we inserted creates a temporary table, Temp_Aircraft_Type_Dim, which contains all of the distinct %Aircraft Type ID values from the Main Data fact table. By using a RIGHT KEEP statement, the data in the original Aircraft Types table is reduced to only those rows that are associated with the Main Data table. After the Aircraft Types table has been truncated, we remove the temporary table.
We will now be able to see that when all values from the Year listbox are selected, no aircrafts are being excluded in the Aircraft Type listbox.
Most of the dimensions we loaded to the Airline Operations app in Chapter 3, Seeing is Believing and Chapter 4, Data Sources present the scenario described previously. That is, the subset ratio for most key fields in the Main Data table is lower than 100%.
The end users of our QlikView document, HighCloud Airlines, have decided that they don't need unused values in the dimension tables as it corresponds to either airlines that are no longer in operation or aircrafts that are no longer in use.
Take what you've learned in this section and reduce all of the dimension tables to contain only those values that appear in the fact table and save the updated document.
Note
The Origin and Destination Airports dimension tables perform a direct query to the source database. Therefore, the Exists() function cannot be used as described here. A QlikView function might not be interpreted as expected in a direct database query. Therefore, we need to use the Left Keep prefix approach in those two cases to achieve the expected result.
Once you've reduced the dimension tables and saved the document, take a look at the size of the QVW file and you'll see the impact of removing unnecessary data. In this case, the document size on disk will be reduced from around 55 MB to approximately 33 MB. This will also have a positive impact on RAM usage.
In the next section, we'll work with a side example, so you may now close the Airline Operations.qvw document.
Of course, when dimensions can exist without related facts, the inverse can also be true. Let's look at how we can deal with facts that do not have any associated dimension values.
As you may have noticed in the Table Viewer window, our current example data model is a bit too tidy. There aren't any dimensionless facts. However, to illustrate the new scenario, we've prepared a side example for which you will find the corresponding datafiles in the Airline OperationsSide examplesChapter 9 folder. Make sure you have the Flights.csv and Aircrafts.csv files in the specified folder. Then, follow these steps:
- Launch the QlikView program and create a new document. Save the document into the
Airline OperationsSide examplesChapter 9folder asDimensionless Facts.qvw. - Next, go to the Edit Script window by pressing Ctrl + E, and load both the
Flights.csvand theAircrafts.csvfiles with the methods you've learned until now. - Explicitly assign a name to each table in the
Loadstatement, using the corresponding filename. - When creating the
Loadstatement for each table, you'll notice that there are no shared fields between them, at least not explicitly. Therefore, we'll need to rename theAC_TYPEIDfield in theAircraftstable to%Aircraft Type IDso that an association is created between both tables through this field. To do this, use theaskeyword as follows:AC_TYPEID as [%Aircraft Type ID],
- You should now have the following code:
Aircrafts: LOAD AC_TYPEID as [%Aircraft Type ID], [Aircraft Group], Manufacturer, [Aircraft Name], [Aircraft Short Name] FROM Aircrafts.csv (txt, codepage is 1252, embedded labels, delimiter is ',', msq); Flights: LOAD Year, [Month (#)], [%Aircraft Type ID], [# Departures Scheduled], [# Departures Performed], [# Available Seats], [# Transported Passengers], [# Transported Freight] FROM Flights.csv (txt, utf8, embedded labels, delimiter is ',', msq); - Save the entire document and then execute the script by clicking on the Reload button from the toolbar.
After finishing the script execution, if we open the Table Viewer window (Ctrl + T), we can analyze the subset ratio for the %Aircraft Type ID field, seen here:

Notice that the subset ratio is 100% in the Flights table, but below 100 percent in the Aircrafts table. In other words, there are now flights with no corresponding dimension data.
Having facts without an associated dimension is undesirable. When we use the dimension in a dashboard, facts that are not associated all get grouped under a hyphen symbol. Since this is basically a null value, this group of facts can not be easily selected by the user.
To illustrate this, let's create a new bar chart with the Aircraft Group field as dimension, which is an aircraft attribute, and Sum ([# Departures Performed])/1000 as the expression. We will end up having something like the following:

On the other hand, we cannot just remove these dimensionless records from the fact table as it will skew the total amounts.
While the appropriate response is always discussed with and decided by the business users, a very common approach is to add dummy dimension values to the dimension table. To do this in our current example, let's follow these steps:
- Open the Script Editor window.
- At the end of the script, add the following code:
Temp_Aircraft_Type_ID: LOAD DISTINCT [%Aircraft Type ID] as Temp_Aircraft_Type_ID RESIDENT [Aircrafts]; CONCATENATE ([Aircrafts]) LOAD DISTINCT [%Aircraft Type ID], 'Unknown: ' & [%Aircraft Type ID] as [Aircraft Name], 'Unknown' as [Aircraft Group], 'UNKNOWN' as [Manufacturer], '???' as [Aircraft Short Name] RESIDENT Flights WHERE NOT Exists(Temp_Aircraft_Type_ID, [%Aircraft Type ID]); DROP TABLE Temp_Aircraft_Type_ID; // Clean up temporary table - Save and reload the document.
Here's what the added script does:
- It copies all of the
%Aircraft Type IDvalues from theAircraftsdimension table into a separate, temporary field calledTemp_Aircraft_Type_ID.- This separate field is necessary as we want to compare the
Aircraft Type IDvalues from theFlightstable against only theAircraft Type IDvalues that exist in theAircraftstable.
- This separate field is necessary as we want to compare the
- We append a dummy table segment to the
Aircraftstable by using theWHERE NOT Exists(Temp_Aircraft_Type_ID, [%Aircraft Type ID])clause. This helps us load the missing aircrafts from theFlightstable while also ruling out all aircrafts that are already stored in the originalAircraftstable, thus avoiding duplicates. - At the same time, for each of the missing ID's, a dummy record is created with (a variant of) the Unknown value for each corresponding attribute.
When checking the Table Viewer we'll see that the Subset Ratio value for %Aircraft Type ID is now 100% on both tables. This can be verified by looking at the previously created chart, which now groups all of the Unknown values, as seen here:

Additionally, when adding a new listbox with one of the various aircraft attributes, we can see that the Unknown values are being listed as well, as shown in the following screenshot:

Save and close the Dimensionless facts.qvw file to continue.