
Chapter 2
Available Methodologies and Their Accuracy
Web analytics can be incredibly powerful and insightful. An astonishing amount of information is available when compared to any other forms of traditional marketing. The danger, however, is taking web analytics reports at face value, and this raises the issue of accuracy.
The key to successfully utilizing the volume of information collected is to get comfortable with your data—what it can tell you, what it can’t, and the limitations therein. This requires an understanding of the data-collection methodologies. Essentially, there are two common techniques: page tags and server logfiles. Google Analytics uses a page tag technique.
In Chapter 2, you will learn:
- How web visitor data is collected
- The relative advantages of page tags and logfiles
- The role of cookies in web analytics
- The accuracy limitations of web traffic information
- How to think about web analytics in relation to user privacy concerns
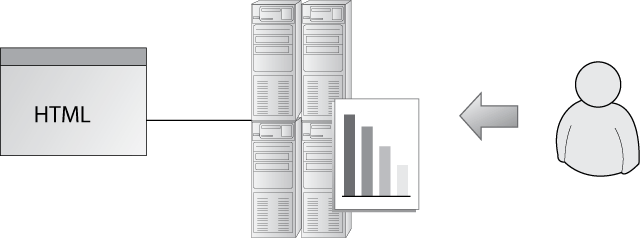
Page tags collect data via the visitor’s web browser and send information to remote data-collection servers. The analytics user views reports from the remote server (see Figure 2-1). This information is usually captured by JavaScript code (known as tags or beacons) placed on each page of your site. Some vendors also add multiple custom tags to collect additional data. This technique is known as client-side data collection and is used mostly by outsourced, Software as a Service (SaaS) vendor solutions.
Figure 2-1: Schematic page tag methodology: Page tags broadcast information to remote data-collection servers, thus enabling the analytics customer to view reports.

Note: Google Analytics is a Software as a Service (SaaS) page tag service.
Logfiles contain data collected by your web server and are independent of a visitor’s browser: A web server logs its activity to a text file that is usually local. That is, on the same network or even the same machine as your web server. The analytics user views reports from the local server, as shown in Figure 2-2. This technique, known as server-side data collection, captures all requests made to your web server, including pages, images, and PDFs, and is most frequently used by stand-alone licensed software vendors.
Figure 2-2: Schematic logfile methodology: The web server logs its activity to a text file locally, thereby enabling the analytics customer to view the reports on the local server.
In the past, the easy availability of web server logfiles made this technique the one most frequently adopted for understanding the behavior of visitors to your site. In fact, most Internet service providers (ISPs) supply a freeware log analyzer with their web-hosting accounts (Analog, Webalizer, and AWStats are some examples). Although this is probably the most common way people first come in contact with web analytics, such freeware tools are too basic when it comes to measuring visitor behavior and are not considered further in this book.
In recent years, page tags have become more popular and are now the de facto standard method for collecting visitor data. Not only is the implementation of page tags easier from a technical point of view, but data-management requirements are significantly reduced because the data is collected and processed by external SaaS servers (your vendor), saving website owners the expense and maintenance of running licensed software to capture, store, and archive information.
Note that both techniques, when considered in isolation, have their limitations. Table 2-1 summarizes the differences. A common myth is that page tags are technically superior to other methods, but as Table 2-1 shows, that depends on what you are looking at. By combining both techniques, however, the advantages of one counter the disadvantages of the other. This is known as a hybrid method and some vendors can provide this.
Note: Google Analytics can be configured as a hybrid data collector—see “Backup: Keeping a Local Copy of Your Data,” in Chapter 6, “Getting Started: Initial Setup.”
Table 2-1: Page tag versus logfile data collection
| Methodology | Advantages | Disadvantages |
| Page tags |
• Breaks through proxy and caching servers—provides more accurate session tracking. • Tracks client-side events—e.g., JavaScript, Flash, Web 2.0 (Ajax). • Captures client-side e-commerce data. Server-side access can be problematic. • Collects and processes visitor data in nearly real time. • Allows the vendor to perform program updates for you. • Allows the vendor to perform data storage and archiving for you. |
• Web pages require modification. You have to make changes to your website pages (add tags) in order to collect data. • Setup errors lead to data loss. If you make a mistake with your tags, data is lost and you cannot go back and reanalyze. • Firewalls can mangle or restrict tags. • Cannot track bandwidth or completed downloads. Tags are set when the page or file is requested, not when the download is complete. • Cannot track search engine spiders. Robots ignore page tags. |
|
Logfile analysis software |
• Automatic data collection. Does not require any changes to your web pages. • Historical data can be reprocessed easily. • No firewall issues to worry about. • Can track bandwidth and completed downloads, and can differentiate between completed and partial downloads. • Tracks search engine spiders and robots by default. • Tracks legacy mobile visitors by default. |
• Proxy and caching inaccuracies. If a page is cached, no record is logged on your web server. • No event tracking—e.g., no JavaScript, Flash, Web 2.0 tracking (Ajax). • Requires your own team to perform program updates. • Requires your own team to perform data storage and archiving. • Robots inflate visit counts and this can be significant. |
Other Data-Collection Methods
Although logfile analysis and page tagging are by far the most widely used methods for collecting web visitor data, they are not the only methods. Network data-collection devices (packet sniffers) gather web traffic data from routers into black-box appliances. Another technique is to use a web server application programming interface (API) or loadable module (also known as a plug-in, though this is not strictly correct terminology). These are programs that extend the capabilities of the web server—for example, enhancing or extending the fields that are logged. Typically, the collected data is then streamed to a reporting server in real time.
As you can see, the advantages of one data-collection method cancel out the disadvantages of the other. However, freeware tools aside, the SaaS page tagging technique is by far the most widely adopted method because of its ease of implementation and low IT overhead and support cost.
Page tag solutions track visitors by using cookies. Cookies are small text files that a web server transmits to a web browser so that it can keep track of the user’s activity on a specific website. The visitor’s browser stores the cookie information on the local hard drive as name/value pairs. Persistent cookies are those that are still available when the browser is closed and later reopened. Session cookies last only for the duration of a visitor’s session (visit) on your site.
For web analytics, the main purpose of cookies is to identify users for later use—most often with an anonymous visitor ID. Among many things, cookies can be used to determine how many first-time or repeat visitors a site has received, how many times a visitor returns each period, and how much time passes between visits. Web analytics aside, web servers can also use cookie information to present personalized web pages. A returning customer might see a different page than the one a first-time visitor would view, such as a “welcome back” message to give them a more individual experience or an auto-login for a returning subscriber.
The following are some cookie facts:
- Cookies are small text files (no larger than 4 KB), stored locally, that are associated with visited website domains.
- Cookie information can be viewed by users of your computer, either within the browser settings themselves or using a text editor application.
- There are two types of cookies: first party and third party.
- A first-party cookie is one created by the website domain. A visitor requests it directly by typing the URL into their browser or by following a link.
- A third-party cookie is one that operates in the background and is usually associated with advertisements or embedded content that is delivered by a third-party domain not directly requested by the visitor.
- For first-party cookies, only the website domain setting the cookie information can retrieve the data. This is a security feature built into all web browsers.
- For third-party cookies, the website domain setting the cookie can also list other domains allowed to view this information. The user is not involved in the transfer of third-party cookie information and is usually not even aware that this is happening.
- Cookies are not malicious and can’t harm your computer. They can be deleted by the user at any time.
- A maximum of 50 cookies are allowed per domain for the latest versions of Internet Explorer and Firefox. Other browsers may vary (Opera 10 currently has a limit of 30; Safari and Google Chrome have no limit on the number of cookies per domain).
Note: From a visitors’ privacy viewpoint, using first-party cookies is best practice. Google Analytics uses first-party cookies only.
Understanding Web Analytics Data Accuracy
When it comes to benchmarking the performance of your website, web analytics is critical. However, this information is accurate only if you avoid common errors associated with collecting the data—especially comparing numbers from different sources. Unfortunately, too many businesses take web analytics reports at face value. After all, it isn’t difficult to get the numbers. The harsh truth is that web analytics data can never be 100 percent accurate, and even measuring the error bars can be difficult.
So what’s the point?
Despite the pitfalls, error bars remain relatively constant on a weekly, or even a monthly, basis. Even comparing year-by-year behavior can be safe as long as there are no dramatic changes in technology or end-user behavior. As long as you use the same yardstick, visitor number trends will be accurate. For example, web analytics data may reveal patterns like the following:
- Thirty percent of site traffic came from search engines.
- Fifteen percent of site revenue was generated by product page x.html.
- We increased subscription conversions from our email campaigns by 20 percent last week.
- Bounce rate decreased 10 percent for our category pages during March.
With these types of metrics, marketers and webmasters can determine the direct impact of specific marketing campaigns. The level of detail is critical. For example, you can determine if an increase in pay-per-click advertising spending—for a set of keywords on a single search engine—increased the return on investment during that time period. As long as you can minimize inaccuracies, web analytics tools are effective for measuring visitor traffic to your online business.
Conflicting Data Points Are Common
A UK survey of 800 organizations revealed that almost two-thirds (63 percent) of respondents say they experience conflicting information from different sources of online measurement data (Online Measurement and Strategy Report 2009, Econsultancy.com, June 2009).
Next, I’ll discuss in detail why such inaccuracies arise, so you can put this information into perspective. The aim is for you to arrive at an acceptable level of accuracy with respect to your analytics data. Recall from Table 2-1 that there are two main methods for collecting web visitor data—logfiles and page tags—and both have limitations.
Issues Affecting Visitor Data Accuracy for Logfiles
Logfile tracking is usually set up by default on web servers. Perhaps because of this, system administrators rarely consider any further implications when it comes to tracking.
Dynamically Assigned IP Addresses
Generally, a logfile solution tracks visitor sessions by attributing all hits from the same IP address and web browser signature to one person. This becomes a problem when ISPs assign different IP addresses throughout the session. A US-based comScore study showed that a typical home PC averages 10.5 different IP addresses per month.
www.comscore.com/Press_Events/Presentations_Whitepapers/2007/Cookie_Deletion_Whitepaper
Those visits will be counted as 10 unique visitors by a logfile analyzer. This issue is becoming more severe because it is now much easier for . As a result, visitor numbers are often vastly overcounted. This limitation is overcome with the use of cookies.
Client-Side Cached Pages
Client-side caching means a previously visited page is stored on a visitor’s computer. In this case, visiting the same page again results in that page being served locally from the visitor’s computer, and therefore the visit is not recorded at the web server.
Server-side caching can come from any web accelerator technology that caches a copy of a website and serves it from their servers to speed up delivery. This means that all subsequent site requests come from the cache and not from the site itself, leading to a loss in tracking. Today, most of the Web is in some way cached to improve performance. For example, see Wikipedia’s cache description at http://en.wikipedia.org/wiki/Cache.
Counting Robots
Robots, also known as spiders or web crawlers, are most often used by search engines to fetch and index pages. However, other robots exist that check server performance—uptime, download speed, and so on—as well as those used for page scraping, including price comparison, email harvesting, competitive research, and so on. These affect web analytics because a logfile solution will also show all data for robot activity on your website, even though robots are not real visitors.
When you are counting visitor numbers, robots can make up a significant proportion of your pageview traffic. Unfortunately, these are difficult to filter out completely because thousands of homegrown and unnamed robots exist. For this reason, a logfile analyzer solution is likely to overcount visitor numbers, and in most cases this overcounting can be dramatic.
Issues Affecting Visitor Data from Page Tags
Deploying a page tag on every single page is a process that can be automated in many cases. However, for larger sites, 100 percent correct deployment is rarely achieved. Perhaps it is because the page tag is hidden from the human eye or there is so much other data available that those errors often go unnoticed for long periods. Having a full deployment is crucial to the accuracy and validity of data collected by this method.
Setup Errors Causing Missed Tags
The most frequent error by far observed for page tagging solutions comes from their setup. Unlike web servers, which are configured to log everything delivered by default, a page tag solution requires the webmaster to add the tracking code to each page. Even with an automated content management system, pages can and do get missed.
In fact, evidence from analysts at MAXAMINE (www.maxamine.com)—now part of Accenture Marketing Sciences—who used their automatic page auditing tool has shown that with some sites claiming that all pages are tagged, as many as 20 percent of pages are actually missing the page tag—something the webmaster was completely unaware of. In one case, a corporate business-to-business site was found to have 70 percent of its pages missing tags. Missing tags equals no data for those pageviews.
JavaScript Errors Halting Page Loading
Page tags work well, provided that JavaScript is enabled on the visitor’s browser. Fortunately, only a small proportion of Internet users have disabled JavaScript on their browsers, as shown in Figure 2-3. However, the inconsistent use of JavaScript code on web pages can cause a bigger problem: Any errors in other JavaScript on the page will immediately halt the browser scripting engine at that point, so a page tag may not execute.
Figure 2-3: Percentage of Internet users with JavaScript-disabled browsers

Source: Visits to the Yahoo! home page during November 2009 (http://developer.yahoo.com/blogs/ydn/posts/2010/10/how-many-users-have-javascript-disabled/—Nicholas Zakas)
Firewalls Blocking Page Tags
Corporate and personal firewalls can prevent page tag solutions from sending data to collecting servers. In addition, firewalls can be set up to reject or delete cookies automatically. Once again, the effect on visitor data can be significant. Some web analytics vendors can revert to using the visitor’s IP address for tracking in these instances, but mixing methods is not recommended. As discussed previously in “Issues Affecting Visitor Data Accuracy for Logfiles” (comScore report), using visitor IP addresses is far less accurate than simply not counting such visitors. It is therefore better to be consistent with the processing of data.
Page Tag Implementation Study
The following data is from over 10,000 websites whose page tags were validated. The page tags checked are from a variety of web analytics vendors. (Thanks to Stephen Kirby of MAXAMINE for this information.)
Summary
The more frequently a website’s content changes, the more prone the site is to missing page tags. In the following image, website content was updated on January 14; by mistake, the updated pages did not include page tags.
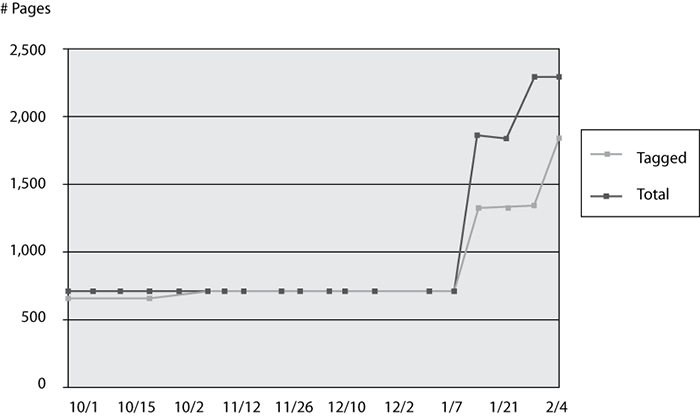
Page Tag Implementation Study (Continued)
Large websites very rarely achieve 100 percent tagging accuracy, as shown in the following chart.

Tracking Legacy Mobile Visitors
A mobile web audience study by comScore back in January 2007 showed that in the United States, 30 million (or 19 percent) of Internet users accessed the Internet from a mobile device.
www.comscore.com/press/release.asp?press=1432
At that time, the vast majority of mobile phones did not understand JavaScript or cookies, and hence only logfile tools were able to track visitors who browsed using their mobile phones. By December 2010, this had grown to 109 million users accessing the Internet from a mobile device (comScore: The 2010 Mobile Year in Review), thanks mainly to the phenomenal success of smartphones such as the iPhone.
A key driver for Internet access from mobile visitors is the processing power that smartphones have brought to the device market—creating a user experience that is very similar to (though obviously smaller than) desktop usage. A consequence of this is mobile browser software that is comparable to that found on regular laptops and PCs, that is, where both JavaScript and cookies are used. Hence, visitors to your website from smartphone mobile devices can be tracked with page tag web analytics in the same way as other visitors.
If tracking legacy (feature-phone) mobile visitors is important to you, see “Tracking Mobile Visitors” in Chapter 6, “Getting Started: Initial Setup.”
Issues Affecting Visitor Data When Using Cookies
Using cookies is a simple, well-established way of tracking visitors. However, their simplicity and transparency (any user can remove them) present issues in and of themselves. The debate of using cookies or not remains a hot topic of conversation in web analytics circles.
Visitors Rejecting or Deleting Cookies
Cookie information is vital for web analytics because it identifies visitors and their referring source and provides subsequent pageview data. The current best practice is for vendors to process first-party cookies only. This is because visitors often view third-party cookies as infringing on their privacy, opaquely transferring their information to third parties without explicit consent. Therefore, many antispyware programs and firewalls exist to block third-party cookies automatically. It is also easy to do this within the browser itself. By contrast, anecdotal evidence shows that first-party cookies are accepted by more than 95 percent of visitors.
Visitors are also becoming savvier and often delete cookies. Recent research published by comScore shows that for Latin America during February 2011, France during August 2010, and Australia during April 2010, the percent of Internet users who clear their first-party cookies in a month is 33, 28, and 28 percent respectively. This follows independent surveys conducted by Belden Associates (2004), JupiterResearch (2005), Nielsen (2005), and comScore (2007) that concluded that cookies are deleted by at least 30 percent of Internet users in a month.
Users Owning and Sharing Multiple Computers
User behavior has a dramatic effect on the accuracy of information gathered through cookies. Consider the following scenarios:
Same user, multiple computers Today, people access the Internet in any number of ways—from work, home, mobile, tablets, or public places such as Internet cafes. One person working from three different machines still results in three cookie settings, and all current web analytics solutions will count each of these user sessions as unique.
Different users, same computer People share their computers all the time, particularly with their families, which means that cookies are shared too (unless you log off or switch off your computer each time it is used by a different person). In some instances, cookies are deleted deliberately. For example, reputable Internet cafes are set up to do this automatically at the end of each session, so even if a visitor uses that cafe regularly and works from the same machine, the web analytics solution will consider that visitor a different and new visitor every time.
Correcting Data for Cookie Deletion and Rejection
Calculating a correction factor to account for your visitors either deleting or rejecting your web analytics cookies is quite straightforward. All you need is a website that requires a user login. That way you can count the number of unique login IDs and divide it by the number of unique users your web analytics tool reports. The result is a correction factor that can be applied to subsequent data (number of unique visitors, number of new visitors, or number of returning visitors).
Having a website that requires a user login is, thankfully in my view, quite rare because people wish to access information freely and as easily as possible. So, although the correction-factor calculation is straightforward, you most probably don’t have any login data to process. Fortunately, a small number of websites can calculate a correction factor to shed light on this issue. These include online banks and popular brands such as Amazon, FedEx, and social network sites, where there is a real user benefit to both having an account and (most important) using it when visiting the site.
A specific example is Sun Microsystems Forums (http://forums.sun.com), a global community of developers with nearly 1 million contributors. A 2009 study by Paul Strupp and Garrett Clark, published at http://blogs.sun.com/pstrupp/, reveals some interesting data.
When using third-party cookies:
- The correction factor is 78 percent for monthly unique users.
- Twenty percent of users delete (more correctly defined as lose) their measurement cookie at least once per month.
- Five percent of users block the third-party measurement cookie.
When using first-party cookies:
- The correction factor improves to 83 percent.
- Percentage of users who delete their measurement cookie at least once per month decreases to 14 percent.
- Percentage of users who block the first-party measurement cookie drops to less than 1 percent.
Note that this is a tech-savvy audience—those who can delete or block an individual cookie without a second thought.
An interesting observation from the study that Paul himself highlights is the relatively small value of the correction factor. That is, when using a first-party cookie, a more precise unique visitor count is 0.83 multiplied by the reported value. Putting this into context, as part of the analysis, 30 percent of users who used more than one computer in a month to visit the forum were removed from the data prior to analysis. This indicates that multiple-device access happens more frequently than cookie deletion.
It is tempting to think that this data can be used to correct your own unique visitor counts. However, the correction factor is a complicated function of cookie deletion, multiple computer use, and visitor return frequency. These factors will almost certainly be different for your specific website. Nonetheless, it is a useful rule-of-thumb guide.
Latency Leaving Room for Inaccuracy
The time it takes for a visitor to be converted into a customer (latency) can have a significant effect on accuracy. For example, most low-value items are either instant purchases or are purchased within seven days of the initial website visit. With such a short time period between visitor arrival and purchase, your web analytics solution has the best possible chance of capturing all the visitor pageview and behavior information and therefore reporting more accurate results.
Higher-value items usually mean a longer consideration time before the visitor commits to becoming a customer. For example, in the travel and finance industries, the consideration time between the initial visit and the purchase can be as long as 90 days. During this time, there’s an increased risk of the user deleting cookies, reinstalling the browser, upgrading the operating system, buying a new computer, or dealing with a system crash. Any of these occurrences will result in users being seen as new visitors when they finally make their purchase. Offsite factors such as seasonality, adverse publicity, offline promotions, or published blog articles or comments can also affect latency.
Offline Visits Skewing Data Collection
Some problems are unrelated to the method used to measure visitor behavior but still pose a threat to data accuracy. High-value purchases such as cars, loans, and mortgages are often first researched online and then purchased offline. Connecting offline purchases with online visitor behavior is a long-standing enigma for web analytics tools. Currently, the best-practice way to overcome this limitation is to use online voucher schemes that visitors can print and take with them to claim a free gift, upgrade, or discount at your store. If you would prefer to receive your orders online, consider providing similar incentives, such as web-only pricing, free delivery if ordered online, and the like.
Another issue to consider is how your offline marketing is tracked. Without taking this into account, visitors who result from your offline campaign efforts will be incorrectly assigned or grouped with other referral sources and will therefore skew your data. How to measure offline marketing is discussed in detail in Chapter 11, “Real-World Tasks.”
Comparing Data from Different Vendors
As shown earlier, it is virtually impossible to compare the results of one data-collection method with another. The association simply isn’t valid. However, given two comparable data-collection methods—both page tags—can you achieve consistency? Unfortunately, even comparing vendors that employ page tags has its difficulties.
Factors that lead to differing vendor metrics are described in the following sections.
First-Party versus Third-Party Cookies
There is little correlation between the two because of the higher blocking rates of third-party cookies by users, firewalls, and antispyware software. For example, the latest versions of Microsoft Internet Explorer block third-party cookies by default if a site doesn’t have a compact privacy policy (see http://www.w3.org/P3P).
Page Tags: Placement Considerations
JavaScript, as with other web code, loads in series within a web browser; that is, coming one after another with the other page content, such as text, style sheets, and images. Because of this, page tag vendors recommend that their page tags be placed just above the </body> tag of your HTML page (at the bottom of the page) to ensure that the visual content of the page loads first. This means that any delays from the vendor’s servers will not interfere with your page loading. The potential problem here is that repeat visitors, those more familiar with your website navigation, may navigate quickly, clicking onto another page before the page tag has loaded to collect data. The more content you have on your pages, the slower they will load and the more likely visitors will click away before the tracking code has executed.
The alternative is to place page tags at the tops of your pages so they load before any page content. However, the risk is that the vendor may have a delay, outage, or blip that stops your pages from loading. Neither situation is ideal, though clearly, delaying content to your visitors is the worse scenario. Hence, placement at the bottom of pages has become the de facto standard.
Tag placement was investigated in a 2009 white paper by TagMan.com. Their study of latency effects revealed that approximately 10 percent of reported traffic is lost for every extra second a page takes to load. So heavy page content results in an undercounting of traffic. Moving the Google Analytics page tag from the bottom of a page to the top increased the reported traffic by 20 percent.
In addition, nonrelated JavaScript placed at the top of the page can interfere with JavaScript page tags that have been placed lower. Most vendor page tags work independently of other JavaScript and can sit comfortably alongside other vendor page tags. However, JavaScript errors on the same page will cause the browser scripting engine to stop at that point and prevent any JavaScript below it, including your page tag, from executing.
Note: Google Analytics uses asynchronous JavaScript page tags. This avoids the issues of tag placement and is discussed later in this chapter, in the section “Improving the Accuracy of Web Analytics Data.”
Did You Tag Everything?
Many analytics tools require links to files—such as PDFs, Word documents, or executable downloads—or outbound links to other websites to be modified in order to be tracked. This may be a manual process whereby the link to the file needs to be modified. The modification represents an event or action when it is clicked, which sometimes is referred to as a virtual pageview. Comparing different vendors requires this action to be carried out several times with their specific codes (usually with JavaScript). Take into consideration that whenever pages have to be coded, syntax errors are a possibility. If page updates occur frequently, consider regular website audits to validate your page tags.
Pageviews: A Visit or a Visitor?
Pageviews are quick and easy to track, and because they require only a call from the page to the tracking server, they are very similar among vendors. The challenge is differentiating a visit from a visitor; because every vendor uses a different algorithm, no two algorithms result in the same value.
Cookie Time-Outs
The allowed duration of time-outs—how long a web page is left inactive by a visitor—varies among vendors. Most page tag vendors use a visitor-session cookie time-out of 30 minutes. This means that continuing to browse the same website after 30 minutes of inactivity is considered to be a new visit. However, some vendors offer the option to change this setting. Doing so will alter any data alignment and therefore affect the analysis of reported visitors. Other cookies, such as the ones that store referrer details, will have different time-out values. For example, Google Analytics referrer cookies last six months. Differences in these time-outs between different web analytics vendors will obviously be reflected in the reported visitor numbers.
Page Tag Code Hijacking
Depending on your vendor, your page tag code could be hijacked, copied, and executed on a different or unrelated website. This contamination results in a false pageview within your reports. By using filters, you can ensure that only data from your domains are reported. To do this, see Chapter 8, “Best Practices Configuration Guide.”
Data Sampling
This is the practice of selecting a subset of data from your website traffic. Sampling is widely used in statistical analysis because analyzing a subset of data gives very similar results to analyzing all of the data yet can provide significant speed benefits when processing large volumes of information. Different vendors may use different sampling techniques and criteria, resulting in data misalignment. Data sampling considerations for Google Analytics are discussed in “Understanding Data Sampling” in Chapter 5, “Reports Explained.”
PDF Files: A Special Consideration
For page tag solutions, it is not the completed PDF download that is reported but the fact that a visitor has clicked a PDF file link. This is an important distinction because information on whether or not the visitor completes the download—for example a 50-page PDF file—is not available. Therefore, a click on a PDF link is reported as a single event or pageview.
Note: The situation is different for logfile solutions. When you view a PDF file within your web browser, Adobe Reader can download the file one page at a time as opposed to a full download. This results in a slightly different entry in your web server logfile, showing an HTTP status code 206 (partial file download). Logfile solutions can treat each of the 206 status code entries as individual pageviews. When all the pages of a PDF file are downloaded, a completed download is registered in your logfile with a final HTTP status code of 200 (download completed). Therefore, a logfile solution can report a completed 50-page PDF file as one download and 50 pageviews. A number of factors will determine this, however
E-commerce: Negative Transactions
All e-commerce organizations have to deal with product returns at some point, whether because of damaged or faulty goods, order mistakes, or other reasons. Accounting for these returns is often forgotten within web analytics reports. For some vendors, it requires the manual entry of an equivalent negative purchase transaction. Others require the reprocessing of e-commerce data files. Whichever method is required, aligning web visitor data with internal systems is never bulletproof. For example, the removal or crediting of a transaction usually takes place well after the original purchase and therefore in a different reporting period.
Filters and Settings: Potential Obstacles
Data can vary when a filter is set up in one vendor’s solution but not in another. Some tools can’t set up the exact same filter as another tool, or they apply filters in a different way or at a different point during data processing.
Consider, for example, a page-level filter to exclude all error pages from your reports. Visit metrics such as time on site and page depth may or may not be adjusted for the filter depending on the vendor. This is because some vendors treat page-level metrics separately from visitor-level metrics.
Time Differences
A predicament for any vendor when it comes to calculating the time on site or time on page for a visitor’s session involves how to calculate for the last page viewed. For example, time spent on page A is calculated by taking the difference between the visitor’s time stamp for page A and the subsequent time stamp for page B and so on. But what if there is no page C; how can the time on page be calculated for page B if there is no following time stamp?
Different vendors handle this in different ways. Some ignore the final pageview in the calculation; others use an onUnload event to add a time stamp should the visitor close their browser or go to a different website. Both are valid methods, although not every vendor uses the onUnload method. The reason some vendors prefer to ignore the last page is that it is considered the most inaccurate from a time point of view—perhaps the visitor was interrupted to run an errand or left their browser in its current state while working on something else. Many users behave in this way; that is, they complete their browsing task and simply leave their browser open on the last page while working in another application. A small number of pageviews of this type will disproportionately skew the time-on-site and time-on-page calculations; hence, most vendors avoid this issue.
Note: Google Analytics ignores the last pageview of a visitor’s session when calculating the time-on-site and time-on-page metrics.
Process Frequency
The frequency of processing is best illustrated by example: Google Analytics does its number crunching to produce reports hourly. However, because it takes time to collate all the logfiles from all of the data-collecting servers around the world, reports can be three to four hours behind the current time. In most cases, it is usually a smooth process, but sometimes things go wrong. For example, if a logfile transfer is interrupted, then only a partial logfile is processed. Because of this, Google Analytics collects and reprocesses all data for a 24-hour period at the day’s end. Other vendors may do the same, so it is important not to focus on discrepancies that arise on the current day.
Note: You should not panic if you observe “missing” data from your reports—for example, no data showing for today during the period 10 a.m. to 11 a.m. This information should be picked up during the data reprocessing that takes place at the end of the day (around midnight, Pacific Standard Time). If you have waited more than 24 hours and the data is still missing, contact the Google Analytics support team at www.google.com/support/googleanalytics/bin/request.py.
Goal Conversion versus Pageviews: Establishing Consistency
Using Figure 2-4 as an example, assume that five pages are part of your defined funnel (click-stream path), with the last step (page 5) being the goal conversion (purchase). During checkout, a visitor goes back up a page to check a delivery charge (step A) and then continues through to complete payment. The visitor is so happy with the simplicity of the entire process that she then purchases a second item using exactly the same path during the same visitor session (step B).
Figure 2-4: A visitor traversing a website, entering a five-page funnel and making two transactions

Depending on the vendor you use, this process can be counted in various ways, as follows:
- Twelve funnel page views, two conversions, two transactions
- Ten funnel page views (ignoring step A), two conversions, two transactions
- Five funnel page views, two conversions, two transactions
- Five funnel page views, one conversion (ignoring step B), two transactions
Most vendors, but not all, apply the last rationale to their reports. That is, the visitor has become a purchaser (one conversion), and this can happen only once in the session, so additional conversions (assuming the same goal) are ignored. For this to be valid, the same rationale must be applied to the funnel pages. In this way, the data becomes more visitor-centric. Google Analytics behaves in this way.
Note: In the example of Figure 2-4, the total number of pageviews equals 12 and would be reported as such in all pageview reports. It is the funnel and goal-conversion reports that will be different.
Why PPC Vendor Numbers Do Not Match Web Analytics Reports
If you are using pay-per-click (PPC) networks, you will typically have access to the click-through reports provided by each network. Quite often, these numbers don’t exactly align with those reported in your web analytics reports. This can happen for the reasons described in the following sections.
Missing Landing Page Tracking URLs
Tracking URLs are required in your PPC account setup in order to differentiate between a nonpaid search engine visitor click-through and a PPC click-through from the same referring domain—Google.com or Yahoo.com, for example. Tracking URLs are simple modifications to your landing page URLs within your PPC account and are of the form http://www.mysite.com?source=adwords. Tracking URLs forgotten during setup, or sometimes simply assigned incorrectly, can lead to such visits being incorrectly assigned to nonpaid visitors.
Slow Page Load Times
As previously discussed, the best-practice location for web analytics data-collection tags is at the bottom of your pages—just above the </body> HTML tag. If your PPC landing pages are slow to download for whatever reason (server delays, page bloat, and so on), it is likely that visitors will click away, navigating to another page on your site or even to a different website, before the data-collection tag has had chance to load. The chance of this happening increases the longer the page load time is. The general rule of thumb for what constitutes a long page load is only 2 seconds. See
www.akamai.com/html/about/press/releases/2009/press_091409.html
The impact of slow loading pages should not be underestimated. Apart from the poor user experience that has a direct impact on your bottom line, a slow-loading landing page can also damage your organic search engine rankings and your AdWords acquisition costs due to a poor AdWords Quality Score.
Note: Google Analytics uses asynchronous page tags. That means they can be placed at the top of your pages, providing greater accuracy without interfering with your page content loading. Further details are contained later in this chapter, in the section “Improving the Accuracy of Web Analytics Data.”
Clicks and Visits: Understanding the Difference
PPC vendors, such as Google AdWords, measure clicks. Most web analytics tools measure visitors who can accept a cookie. Those are not always going to be the same thing when you consider the effects on your web analytics data of cookie blocking, JavaScript errors, and visitors who simply navigate away from your landing page quickly—before the page tag collects its data. Because of this, web analytics tools tend to slightly underreport visits from PPC networks.
PPC Account Adjustments
Google AdWords and other PPC vendors automatically monitor invalid and fraudulent clicks and adjust PPC metrics retroactively. For example, a visitor may click your ad several times (inadvertently or on purpose) within a short space of time. Google AdWords investigates this influx and removes the additional click-throughs and charges from your account. For Google Analytics, AdWords data is imported when you request the report, and previous data may be updated to reflect the changes from the fraud-protection algorithms. Alternative web analytics tools may use a different AdWords import frequency. From a reporting point of view, the recommendation is to not place too much emphasis on AdWords visitor numbers for the current day and use longer time frames for detailed analysis. This holds true for all web analytics solutions and all PPC advertising networks.
For further information on how Google treats invalid clicks, see
http://adwords.google.com/support/bin/topic.py?topic=35
Note: Although most of the AdWords invalid-click updates take place within 24 hours, they can take longer. For this reason, even if all other factors are eliminated, AdWords click-throughs within your PPC account and those reported in your web analytics reports may never match exactly.
Keyword Matching: Bid Term versus Search Term
The bid terms you select within your PPC account and the search terms used by visitors that result in your PPC ad being displayed can often be different: think “broad match.” For example, you may have set up an ad group that targets the word shoes and solely relies on broad matching to match all search terms that contain the word shoes. This is your bid term. A visitor uses the search term blue shoes and clicks your ad. Web analytics vendors may report the search term, the bid term, or both. Google Analytics reports both.
Losing Data via Third-Party Redirects
Using third-party ad-tracking systems—such as Adform, Atlas Search, Blue Streak, DoubleClick, Efficient Frontier, and SEM Director—to track click-throughs to your website means your visitors are passed through redirection URLs. This results in the initial click being registered by your ad company, which then automatically redirects the visitor to your actual landing page. The purpose of this two-step hop is to allow the ad-tracking network to collect visitor statistics independently of your organization, typically for billing purposes. Because this process involves a short delay, it may prevent some visitors from landing on your page. The result can be a small loss of data and therefore failure to align data.
More important, and more common, redirection URLs may break the tracking parameters that are added onto the landing pages for your own web analytics solution. For example, using generic tracking parameters, your landing page URL may look like this:
http://www.mysite.com/?source=google&medium=ppc&campaign=Jan12
When added to a third-party tracking system for redirection, it could look like this:
http://www.redirect.com?http://www.mywebsite.com?source=google&medium=ppc↵ &campaign=Jan12
The problem occurs with the second question mark in the second link because you can’t have more than one in any valid URL. Some third-party ad-tracking systems will detect this error and remove the second question mark and the following tracking parameters, leading to a loss of campaign data.
Some third-party ad-tracking systems allow you to replace the second ? with a # so the URL can be processed correctly. Essentially, the test to see if this is working correctly is straightforward—following the redirect, check that your campaign parameters remain visible on your landing page URL. If not, this will need to be corrected. If you are unsure of what to do to fix the issue, you can avoid the problem completely by using encoded landing-page URLs within your third-party ad-tracking system, as described at the following site:
http://www.w3schools.com/tags/ref_urlencode.asp
Note: From my experience, the most common reasons for discrepancies between PPC vendor reports and web analytics tools arise from the first and last issues discussed in this section; that is, missing landing page tracking URLs and the loss of tracking parameters due to third-party redirects.
Why Counting Uniques Is Meaningless
The term uniques is often used in web analytics as an abbreviation for unique web visitors, that is, how many unique people visited your site. The problem is that counting unique visitors is fraught with problems that are so fundamental the term uniques is rendered meaningless.
As discussed earlier in this chapter, cookies get lost, blocked, and deleted—nearly one-third of tracking cookies can be missing after a period of four weeks. The longer the time period, the greater the chance of this happening, which makes comparing year-on-year uniques invalid, for example. In addition, browsers make it very easy these days for cookies to be removed—see the new “incognito” features of the latest Firefox, Chrome, and Internet Explorer browsers.
However, the biggest issue for counting uniques is how many devices people use to access the Web. For example, consider the following scenario:
1. You and your spouse are considering your next vacation. Your spouse first checks out possible locations on your joint PC at home and saves a list of website links.
2. The next evening you use the same PC to review these links. Unable to decide that night, you email the list to your office, and the next day you continue your vacation checks during your lunch hour at work and also review these again on your mobile while commuting home on the train.
3. Day 3 of your search resumes at your friend’s house, where you seek a second opinion. Finally, you go home and book online using your shared PC.
The above scenario is actually very common—particularly if the value of the purchase is significant, which implies a longer consideration period and the seeking of a second opinion from a spouse, friends, or work colleagues.
Simply put, there is not a web analytics solution in the world that can accurately track this scenario—that is, to tie the data together from multiple devices and where multiple people have been involved—nor is there likely to be one in the near future.
Combining these limitations leads to large error bars when it comes to tracking uniques. In fact, these errors are so large that the metric becomes meaningless and should be avoided, where possible, in favor of more accurate “visit” data. That said, if you must use unique visitors as a key metric, ensure that the emphasis is on the trend, not the absolute number.
Data Misinterpretation: Lies, Damned Lies, and Statistics
Data is not always straightforward to interpret. Take the following two examples, which are not accuracy issues:
- New visitors plus repeat visitors does not equal total visitors.
A common misconception is that the sum of new visitors and repeat visitors should equal the total number of visitors. Why isn’t this the case? Consider a visitor making his first visit on a given day and then returning on the same day. He is both a new and a repeat visitor for that day. Therefore, looking at a report for the given day, two visitor types will be shown, though the total number of visitors is one.
It is therefore better to think of visitors in terms of visit type—that is, the number of first-time visits plus the number of repeat visits equals the total number of visits.
- Summing the number of unique visitors per day for a week does not equal the total number of unique visitors for that week.
Consider the scenario in which you have 1,000 unique visitors to your website blog on a Monday. These are in fact the only unique visitors you receive for the entire week, so on Tuesday the same 1,000 visitors return to consume your next blog post. This pattern continues for Wednesday through Sunday.
If you were to look at the number of unique visitors for each day of the week in your reports, you would observe 1,000 unique visitors. However, you cannot say that you received 7,000 unique visitors for the entire week. For this example, the number of unique visitors for the week remains at 1,000.
Improving the Accuracy of Web Analytics Data
Clearly, web analytics is not 100 percent accurate, and the number of possible inaccuracies can appear overwhelming at first. However, as the preceding sections demonstrated, you can get comfortable with your implementation and focus on measuring trends rather than precise numbers. For example, web analytics can help you answer the following questions:
- Are visitor numbers increasing?
- By what rate are they increasing (or decreasing)?
- Have conversion rates gone up since beginning PPC advertising?
- How has the cart-abandon rate changed since the site redesign?
If the trend shows a 10.5 percent reduction, for example, this figure should be accurate regardless of the web analytics tool that was used. These examples are all high-level metrics, though the same accuracy can also be maintained as you drill down and look at, for example, which specific referrals (search engines, affiliates, social networks), campaigns (paid search, email, banners), keywords, geographies, or devices (Windows, Mac, mobile) are used.
Because you are going to be a Google Analytics user, you should be aware that Google has made significant advances in improving the accuracy of the page-tagging data-collection technique in recent years. Since 2010, the recommended implementation of the Google Analytics page tag is asynchronous. This is a clever way of loading JavaScript code in parallel with the loading of a page, as opposed to loading in series, which is the traditional approach. This overcomes both limitations of tag placement—the issue of missing visitor activity because the page tag did not have a chance to load when placed at the bottom of the page and any potential interference with your page content loading due to vendor issues when the page tag is placed at the top of your pages.
When the asynchronous method is used, the tracking code is loaded in the background, that is, in parallel, as soon as the page is requested. Any tracking requests made prior to the code loading fully are stored in a queue and executed when the code is available. The result is greater tracking accuracy (as the page tag is at the top of the page), without any possible interference with your page content that is normally associated with page tag placement.
When all the possibilities of inaccuracy that affect web analytics solutions are considered, it is apparent that it is ineffective to focus on absolute values or to merge numbers from different sources. If all web visitors were to have a login account in order to view your website, this issue could be overcome. In the real world, however, the vast majority of Internet users wish to remain anonymous, so this is not a viable solution.
As long as you use the same measurement for comparing data ranges, your results will be accurate. This is the universal truth of all web analytics.
Here are 11 recommendations for enhancing your web analytics accuracy:
1. Be sure to select a tool that uses page tagging and first-party cookies for data collection. Google Analytics is a page tag tool that sets only first-party cookies.
2. Use asynchronous page tagging with the code located in the head section of your pages. This is the default for Google Analytics.
3. Don’t confuse visitor identifiers. For example, if first-party cookies are deleted, do not resort to using IP address information. It is better simply to ignore that visitor’s activity. Google Analytics does this.
4. Remove or report separately all nonhuman activity from your data reports, such as robots and server-performance monitors. Google Analytics ignores robots that do not execute JavaScript (I have yet to come across any robot that does this).
5. Track everything. Don’t limit tracking to landing pages, or even just pages. Track your entire website’s activity, including file downloads, internal search terms, transactions, sales funnel click-throughs, clicks on so-called love buttons (Facebook Likes, Twitter Follows, and so forth), error pages, and outbound links. Apart from pageviews, Google Analytics will not track the others by default—you have to configure these for yourself. See Chapter 7, Chapter 8, and Chapter 9.
6. Regularly audit your website for page tag completeness (at least monthly for large websites). Sometimes site content changes result in tags being corrupted, deleted, or forgotten. Tools to help you do this are listed in Appendix B, “Useful Tools.”
7. Display a clear and easy-to-read privacy policy (required by law in the European Union). This establishes trust with your visitors because they better understand how they’re being tracked and are less likely to delete cookies. A best-practice example of a privacy statement for use with Google Analytics is shown in Chapter 3, “Google Analytics Features, Benefits, and Limitations.”
8. Avoid making judgments on data that is less than 24 hours old because it’s often the most inaccurate. When you log into Google Analytics, the current day is omitted from the data window by default, though it can be manually included.
9. Test redirection URLs to guarantee that they maintain tracking parameters. If your landing page URL does not maintain your tracking parameters, they have been lost and this will need to be corrected.
10. Ensure that all paid online campaigns use tracking URLs to differentiate from nonpaid sources. Google Analytics does this automatically for AdWords.
11. Use visit metrics in preference to unique visitor metrics because the latter are highly inaccurate. Most Google Analytics reports show visit data for precisely this reason.
These suggestions will help you appreciate the errors often made when collecting web analytics data. Understanding what these errors are, how they happen, and how to avoid them will enable you to benchmark the performance of your website better.
Privacy Considerations for the Web Analytics Industry
With the huge proliferation of Web use, people are now much more aware of privacy issues, concerns, and obligations. In my opinion, this is a step forward—the industry needs an informed debate about online privacy. Although privacy has been bubbling under the radar of the general public for many years, there was a huge uptick in discussion when the new European Union (EU) privacy law came into effect on May 26, 2011.
Before discussing the impact of this specific new law, it is worth looking at what privacy issues web users and website owners should be aware of. This will help the reader understand why this new law came about (and will no doubt eventually be emulated in laws in other parts of the world) and why it is a good thing for the web measurement industry as a whole.
Types of Private Information
There are two types of private information:
Non–personally identifiable information (non-PII) This is anonymous aggregate data that cannot be used to identify or deduce demographic information, such as your name or address. It is best illustrated by example. Suppose you wish to monitor vehicle traffic close to a school so that you can predict and improve the safety and efficiency of the surrounding road structure. You might stand on a street corner counting the number of vehicles, their type (car, van, truck, bus, and so on), time of day, and how long it takes for them to pass the school gates. This is an example of nonpersonal information—there is nothing in this aggregate data that identifies the individual driver or owner of each vehicle. Incidentally, you also cannot identify whether the same vehicle is repeatedly driving around the school in a circle, but that is an unlikely scenario that is not considered further.
As you can see, this is a great way to collect data to improve things for all people involved (pupils, residents, shop owners, and drivers) without any interference of privacy. This example is directly analogous to using the Web. By far, the vast majority of Web users who are surveyed claim they are happy for their nonpersonal information to be collected and used to improve a website’s effectiveness and ultimately their user experience.
Personally identifiable information (PII) Taking the previous non-PII example further, suppose the next day you started to collect vehicle license plate details, or stopped drivers to question them on their driving habits, or followed them home to determine whether they were local residents. These are all examples of collecting personal data—both asked-for data, such as their name, age, and address, and non-volunteered information that can be discovered, such as gender and license plate details.
Collecting personally identifiable information clearly has huge privacy implications and is regulated by law in most democratic countries. Collecting data in this way would mean that all drivers would need to be explicitly informed that data collection was occurring and offered the choice of not driving down the street. They could then make an informed decision as to whether they wish to take part in the study or not. Again, this is analogous to using the Web—asking the visitor to opt in to sharing their personal information.
The issue with regard to web privacy is that many users are confused as to what form of tracking, if any, is taking place when they visit a website. Very few people read privacy statements, and even when viewing them, the public is cynical. Often, these statements tend to be written in a legal language that is difficult to understand, they change without notice, and they primarily appear to be there to protect the website owner rather than the privacy of the visitor.
Regardless of the public’s confusion, apathy, or anger about website privacy, it is your responsibility as a website owner to inform visitors about what data-collection practices are occurring when a visitor views your website. In fact, within the European Union, law requires it. View the section “Common Privacy Questions” in Chapter 3 for a best-practice example of a clear privacy statement when using Google Analytics.
The EU Privacy Law
Put into effect in 2011, this law is applicable to all websites and businesses operating within any of the 27 member countries of the European Union. The rationale for the law was the failure of the web analytics industry to self-regulate privacy policy properly. The EU lawmakers targeted the surreptitious tracking of individuals that has been going on for many years:
- Sharing cookie information collected on one website with another website via third-party cookies
- Identifying anonymous visitors—either by using data from a third-party cookie where personal information was entered or back-filling previous visit data when a visitor later creates an account or makes a purchase
- Tracking visitors even though they have set their browser privacy settings to block tracking cookies (used by Flash Shared Objects)
I use the word cookies because this is the current technology used for tracking visitors. However, the law is technology agnostic and therefore applies regardless of what actual data-collection technology is employed. Essentially, if you are using third-party cookies, or Flash Shared Objects, or any other similar nontransparent tracking technology, this law is very much targeting you.
To continue doing so under this law, you have to request explicit consent from your visitors. The purpose is to ensure transparency with your visitors. The hope is that website owners will evaluate their tracking requirements, realize that such invasive tracking is bad for business, and stop the practice—or comply with the law by placing pop-up notifications, or similar, on their pages to gain visitor consent. Pop-up alerts are disruptive and are known to be bad for business (there is a whole industry built around blocking pop-up advertisements), so the resulting poor user experience should also drive website owners to reconsider.
As a Google Analytics user, you are not doing any of the above. However, at the time of writing, the EU privacy law says that unless strictly necessary, you cannot track visitors to your website without explicit permission from each of them.
UK Guidelines Document
The Independent Commissioner’s Office (ICO) is the UK independent authority to protect personal information—for all types of collected data, including online. It has published a PDF guideline document on the new EU privacy law available at
The guidelines are similar for all other EU member countries, though you should check with your specific country’s privacy office to understand how the law is to be applied in your country. The ICO is a Google Analytics user.
As a result of this, many people are interpreting the law as saying that web tracking is illegal because it is not “strictly necessary” when delivering a web page to the visitor—unless you ask your visitor’s consent to do so at the start of their visit. However, as I am sure will be shown, this is not the intent of the lawmakers.
For me it’s an obvious argument and one that is easy to justify: As a commercial part of your business, tracking the performance of your website is strictly necessary, in the same way that tracking other parts of your organization is strictly necessary—such as your sales performance, staff performance, marketing activities, operational processes, costs, and so forth. Measurement is a critical part of business in the 21st century; this even applies to governments and institutions that need to be accountable to taxpayers.
Tip: The EU privacy law is still very fluid while the 27 EU member countries figure out how to interpret and implement it. You can follow the discussion on the book blog site:
www.advanced-web-metrics.com/blog/category/privacy-accuracy/
The Impact of Requiring Explicit Consent
The main impact of this law is to stop the surreptitious collection of personal information by making it transparent to the visitor what is being tracked and allowing them to make an informed decision as to whether they wish to share such information with the website owner. Even without visitors saying no en masse, it forces website owners to prioritize visitor privacy. That’s a good thing for the Web as a whole and will hopefully spread beyond the borders of the EU.
The controversy expressed (and rightly feared) so far by website managers is that sites collecting benign non-PII data may also have to display an obtrusive and brand damaging pop-up message requesting tracking consent (to comply with “strictly necessary”). As an example of how damaging this can be to a business, consider Figure 2-5. This shows the before and after effects of requesting visitor consent even though the data collected was completely benign. The data loss is 90 percent for a best-practice implementation of Google Analytics!
Figure 2-5: Loss of data when visitors are asked for explicit consent to be tracked benignly

There can be many reasons for the sharp drop in collected data shown in Figure 2-5. The wording of the consent message to the visitor and its design and placement are obviously critical. There is also the fear of the unknown; that is, when they first visit a website, the visitor is not interested in reading or has no time to read boring privacy text to find out what its implications may be. Therefore, they simply opt for the safe “no” option. In this example, there is no benefit for the visitor motivating them to opt in. Perhaps a retail site would fare better with a sweetener of a better deal or better shopping experience. However, my instinct tells me the drop will still be significant.
The bottom line is that at present the term “strictly necessary” is ambiguous and needs to be clarified by lawmakers.
Note: Ironically, the data shown in Figure 2-5 comes from the ICO website (www.ico.gov.uk), the organization responsible for implementing the new EU privacy law in the UK. Data was obtained as a freedom of information request to the ICO. With thanks to Vicky Brock (@brockvicky).
Requirements for Google Analytics Users
The key is to respect your visitor’s privacy. That means no PII without explicit consent and all other data remaining anonymous and benign. Google Analytics fits this category and has deliberately done so since its launch. That does not mean you can ignore this law. For example, it is possible to configure Google Analytics to collect PII and therefore break the law—I have seen this happen inadvertently. Therefore, follow these four important guidelines:
- Audit and document your website tracking capabilities, such as cookie collection, and adjust your site accordingly. That can mean changing what information is collected, how it is collected, and how the practice is communicated to the visitor.
- Ensure that your privacy statement is up-to-date and accurate. Keep it simple, not full of legal jargon. An example privacy statement is shown in Chapter 3.
- If you wish to perform behavioral targeting or collect personal information, ask for explicit consent from your visitors first.
- Do not collect any PII data using Google Analytics. Even if you have tracking permission for this from your visitor, it is against the Google Analytics terms of service to collect such information using Google Analytics. That means no email addresses, usernames, or address details collected from, for example, submitted forms or logins.
In Chapter 2, you have learned the following:
The difference between page tags and logfiles
The perils of cookies You learned about the role of cookies in web analytics, what they contain, and why they exist, including the differences between first-party and third-party cookies.
Difficulties of interpreting traffic data We explored the accuracy limitations of web traffic information in terms of collecting web visitor data, interpreting it, and comparing numbers from different vendors.
How to improve the accuracy of your data I discussed how you can mitigate error bars and improve tracking accuracy so that you become comfortable and confident with your data.
Visitors’ privacy issues You learned how to think about web analytics in relation to end-user privacy concerns and your responsibilities as a website owner to respect your visitors’ privacy.