
Appendix A: Regular Expression Overview
Regular expressions, also referred to as regex, are a way for computer languages to match strings of text, such as specific characters, words, or patterns of characters. A simple everyday example of regular expressions is using wildcards for matching filenames on your computer. For example, *.pdf matches all filenames that end in .pdf. However, regex can be much more powerful (and complex) than this.
Within Google Analytics, regular expressions are primarily used when creating profile filters (Chapter 8), advanced segments (Chapter 8), and table filters (Chapter 4).
Note: This appendix is intended as a general introduction to the fundamentals of building regular expressions within Google Analytics. In most cases this will fit your needs. However, if you need more details, there are numerous resources on the Web. For example, type “regular expression +tutorial” into Google’s search bar for a list of tutorials on the topic.
Understanding the Fundamentals
A solid understanding of regex syntax is required, and the syntax remains similar across the different flavors of regex engines (POSIX, PCRE). In addition, a number of tools are available to help you troubleshoot building your regular expressions (see Appendix B).
Google Analytics uses a partial implementation of the Perl Compatible Regular Expressions (PCRE) library. I use the word partial because a full implementation is more powerful and flexible than a Software as a Service vendor would want it to be! If its use is unrestricted, it can be used maliciously to hack or break a website. Hence, not every feature of PCRE is included, though you would be hard-pressed to find what isn’t.
Warning: Google Analytics uses only a partial implementation of PCRE, and hence advanced features may not be available. Unfortunately, the exact feature set of the regex engine is undocumented, so further guidance is difficult! However, we do know that “look ahead” and “negative look ahead” features are not available. That is, google.(?=com) or google.(?!com) will not work. The workaround for this particular regex when using table filters or advanced segments is to select Excluding or Does Not Match Regular Expression from the configuration drop-down menu and use google.com for the match.
An important point to grasp when using regular expressions is that there are two types of characters: literals and metacharacters. Most characters are treated as literals. That is, if you wanted to match a URL for advanced, you would type the characters as a, followed by d, followed by v, and so forth. The exceptions to this are metacharacters. These are characters of special meaning to the regex engine and therefore interpreted differently. The most common metacharacters are listed in Table A-1. Ensure that you understand these before proceeding.
Table A-1: Common regular expression metacharacters
| Metacharacter | Description |
| . | Matches any single character. |
| [ ] | Matches a single character that is contained within the square brackets. Referred to as a class. |
| [^ ] | Matches a single character that is not contained within the square brackets. Referred to as a class. |
| ^ | Matches the beginning of the string. This is referred to as an anchor. |
| $ | Matches the end of the string. This is referred to as an anchor. |
| * | Matches zero or more of the previous item. |
| ? | Matches zero or one of the previous item. |
| + | Matches one or more of the previous item. |
| | | The OR operator. Matches either the expression before or the expression after the operator. |
| The escape character. Allows you to use one of the metacharacters for your match. | |
| ( ) | Groups characters into substrings. |
Using only literals, you can construct simple regular expressions. However, combining literals with metacharacters provides for a more fine-grained approach to pattern matching. The best way to understand how regular expressions work is by example, and I use relevant Google Analytics matches to illustrate this.
Note: The regex engine of Google Analytics is not case sensitive.
First, partial matches are allowed. For example, say you wanted to view only referrals from the website www.google.com. Using a regular expression, you could use the partial keyword goog in the table filter of your Traffic Sources Sources All Traffic report. This will match all entries that have the letters goog in them, as shown in Figure A-1.
Although simple to implement, literals can be very powerful—as long as you can identify a unique pattern match that includes the string of interest. Taking the previous example, to be more specific, use the OR metacharacter, as in this example:
google.(com|co.uk|ca)
Figure A-1: Table filter using a partial match
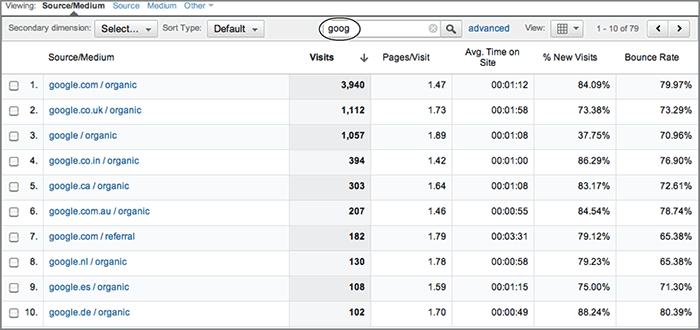
This matches the literal google, followed by a period (this must be escaped because it is also a metacharacter), followed by com OR co.uk (period also escaped) OR ca. Because our expression now contains metacharacters, we must use the Advanced Filter area of the report table to include this—as shown in Figure A-2.
Figure A-2: Table filter using the OR metacharacter

Note: Google Analytics automatically escapes periods in the report table filter and advanced segments for you. Therefore, you can omit the escape charter () for these. However, when you are learning regex, I advise you to always escape these yourself as best practice. Profile filters and goal or funnel configurations do not have the automatic escape feature.
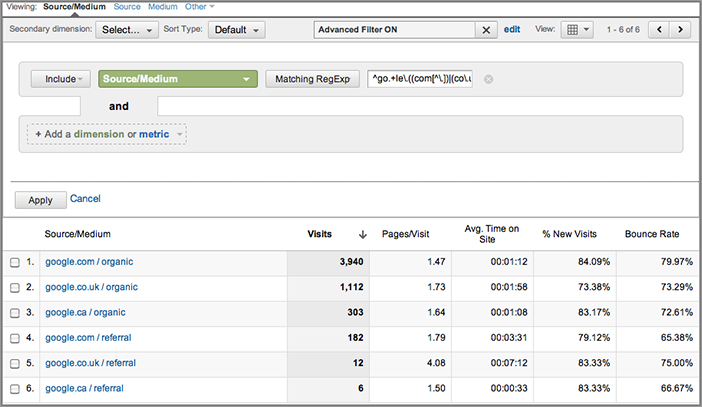
You will notice from Figure A-2 that subdomains of Google are present in the reports (rows 6 and 7). Suppose you wish to remove these from your matches. Modify the regex query as follows:
^google.(com|co.uk|ca)
This results in only referrers that start with the pattern google being matched. Another example to practice with includes the following syntax:
^go.+le.((com[^.])|(co.uk[^.])|(ca[^.]))
This extends the previous example to explicitly match only Google domains that end in .com, .co.uk, and .ca. This removes referrers such as google.com.au, google.com.br, and so forth, by excluding any further ".", as shown in Figure A-3. Note that I have also been a little lazy and used go.+le to illustrate how to use the + metacharacter. That is, it is used to match one or more of the previous character—in this case, any character.
Figure A-3: Table filter using multiple metacharacters
The following are examples to consider when matching URLs listed in your Content Pages reports:
?(id|pid)=[^&]*
This matches the filename followed by the first query parameter and its value if its name is equal to id or pid. If you have a report with URIs of the following form, this regex will match the two URIs highlighted:
/blog/post?pid=101 /blog/post?id=101&lang=en&cat=hacks /blog/post?lang=en&cat=hacks&id=102 /blog/about-this-blog
Typically, this regex format is used when defining a goal or funnel step. Note the use of the negative class to stop the regex match. That is, this regex will match all characters after id= or pid= that do not contain &. An asterisk is used (*) to also match zero occurrences of & so that even if there is no second query parameter present, as per the first URI, the regex will still match.
An example that is useful when filtering within keyword reports (search engines and internal site search) is to consider misspellings. Perhaps you need to find all matches for “colour” and “color.” The following regex will achieve this:
colo[u]*r
Here are some other misspelling examples (my name is sometimes spelled Brain!):
Voda(ph|f)one Ste(ph|v)en Br[ai][ai]n
Finally, although not directly relevant to Google Analytics, this is a common regex used in web development for processing forms:
^(.+)@([^();:,<>_]+.[a-zA-Z.]{2,6})
Use this to test your understanding. Broken into its constituent parts, this regex checks an email address to ascertain if it is a valid format—that is, [email protected] and not brian@@my_site:com, for example. From left to right, the English interpretation is as follows:
- Match one or more of any character before the @
- Match any character after the @ but do not include any of following characters: ( ) ; ; , < > _
- Followed by a period
- Followed by between two and six characters that must include an alphabetic character (A–Z as either upper- or lowercase) or a period
I have highlighted the middle section of this regex to help guide your eye, that is, the part between the @ and next period.
If you have followed these examples, you are well on your way to understanding regular expressions. If not, reread this section and use one of the regex tools listed in Appendix B. Further regex examples are shown throughout this book, though none are more complicated than those shown here.
Tips for Building Regular Expressions
- Make the regular expression as simple as possible. Complex expressions take longer to process or match than simple expressions.
- Avoid the use of .* if possible because this expression matches everything zero or more times and may slow processing of the expression. For instance, if you need to match all of the following
index.html, index.htm, index.php, index.aspx, index.py, index.cgi
use
index.(h|p|a|c)+.+
not
index.*
- Try to group patterns together when possible. For instance, if you wish to match a file suffix of .pdf, .doc, and .ppt, use
.(pdf|doc|ppt)
not
.pdf|.doc|.ppt
- Be sure to escape the regular expression wildcards or metacharacters if you wish to match those literal characters. Common ones are periods in filenames and parentheses in text.
- Use anchors whenever possible (^ and $, which match either the beginning or end of an expression) because they speed up processing.