
Chapter 10
One-Dimensional Brownian Motion and Related Processes
Brownian motion is a keystone in the foundation of mathematical finance. Brownian motion is a continuous-time stochastic process but it can be constructed as a limiting case of symmetric random walks. Recall that a similar approach was used to obtain the log-normal price model as a limiting case of binomial models. Since the probability distribution of Brownian motion is normal, it is reasonable to begin with reviewing some of the important basic facts about the multivariate normal distribution.
10.1 Multivariate Normal Distributions
10.1.1 Multivariate Normal Distribution
The n-variate normal distribution is determined by an n × 1 mean vector μ and an n × n positive definite covariance matrix C = C⊤:
Note: throughout we use superscript ⊤ to denote the transpose. We denote the n-variate normal distribution with mean vector μ and covariance matrix C by Normn(μ, C). Assuming the nondegenerate case with a positive definite covariance matrix, the joint probability density function (PDF) is an n-variate real-valued function
This PDF is that of random vector X = [X1,X2,...,Xn]⊤ ~ Normn(μ, C), i.e., X has n-variate normal distribution with mean μ = E[X] and covariance C = E[XX⊤] − μμ⊤. As components, μi = E[Xi] and Cij = Cov(Xi,Xj) = E[XiXj] − μiμj, i, j = 1, 2 ...,n. It is a well-known fact that normal random variables are independent iff they are uncorrelated with zero covariances Cij = 0 for all i ≠ j. Therefore, if the covariance is a diagonal matrix, , where , then the components of X are (mutually) independent normally distributed random variables. In this case, the joint PDF is a product of one-dimensional marginal densities:
Here we used the notation for the PDF of the standard normal. Another well-known fact is that a sum of normal random variables is again normally distributed:
where Var (X1 + X2)= σ12 + 2 Cov(X1,X2)+ σ22. This property extends to the multivariate case as follows. Let a and B be an m × 1 constant vector and an m × n constant matrix, respectively, with 1 ≤ m ≤ n. Suppose that X ~ Normn(μ, C); then the m-variate random vector a + BX is normally distributed with mean vector a + B μ. Its covariance matrix is given by E[B(X − μ)(B(X − μ))⊤]= B E[(X − μ)(X − μ)⊤] B⊤ = BCB⊤. Hence, provided that det(BCB⊤) ≠ 0, we have:
This property allows us to express an arbitrary multivariate normal vector in terms of independent standard normal variables. Since the covariance matrix C is positive definite, it admits the Cholesky factorization: C = LL⊤ with a lower-triangular n × n matrix L. Let Z11,Z2,...,Zn be i.i.d. standard normals. The vector Z = [Z1,Z2,...,Zn]⊤ is then an n-variate normal with mean vector zero and having the identity covariance matrix I. Applying (10.3) to Z ~ Normn(0, I) gives μ + LZ ~ Normn(μ, C), i.e., in this case the vector μ + LZ has mean μ + L0 = μ and covariance matrix LIL⊤ = LL⊤ = C.
10.1.2 Conditional Normal Distributions
Suppose that X = [X1,X2,...,Xn]⊤ ~ Normn(μ, C), n ≥ 2. Let us split (partition) the vector X into two parts:
for some m with 1 < m < n. Correspondingly, we split the vector μ and matrix C to represent them in a block form:
where μ1 ∊ ℝm and μ2 ∊ ℝn−m are the respective mean vectors of X1 and X2; C11 = E[X1X1⊤] is m × m, C12 = E[X1X2⊤] is m × (n − m), C21 = C12⊤ is (n − m) × m, and C22 = E[X2X2⊤] is (n − m) × (n − m). Then, the conditional distribution of X1 given the value of X2 = x2 is normal:
For example, consider a two-dimensional (bivariate) normal random vector
In conformity with (10.4), X1 conditional on X2 (and vice versa) is normally distributed. In this case, m = n − m = 1 so the block matrices are simply numbers: C11 = σ12, C12 = C21 = ρσ1σ2, C22 = σ22, and x2 − μ2 = x2 − μ2. In particular,
10.2 Standard Brownian Motion
10.2.1 One-Dimensional Symmetric Random Walk
Consider the binomial sample space Ω ≡ Ω∞:
generated by a Bernoulli experiment using any number of repeated up or down moves. We assume a probability measure ℙ such that the up and down moves are equally probable. That is, each outcome ω = ω1ω2 ... ∊ Ω∞ is a sequence of U’s and D’s where for all i ≥ 1. We note that, in contrast to the binomial model where we had a finite number of moves N ≥ 1 with Ω = ΩN, the number of moves is now infinite and the sample space Ω∞ is uncountable. Nevertheless, the discrete-valued random variables that were previously defined on ΩN (e.g., Un, Dn, Bn, etc.) are still defined in the same way on Ω∞. The sample space now also admits uncountable partitions. Obviously, we still have all the countable partitions in the same manner as we discussed for ΩN. For example, the event that the first move is up is the atom AU = {ω1 = U} = {Uω2ω3 ... | ωi ∊{D, U}, for all i ≥ 2}and its complement is AD = {ω1 = D} = {Dω2ω3 ... | ωi ∊{D, U}, for all i ≥ 2} where Ω∞ = AU ∪ AD. In particular, the atoms that correspond to fixing (resolving) the first n ≥ 1 moves are given similarly,
The union of these 2n atoms is a partition of Ω∞, for every choice of n ≥ 1. We denote by ℱ∞ the σ-algebra generated by all the above atoms corresponding to any number of moves n ≥ 1. Recall that for every N ≥ 1, {ℱn}1≤n≤N is the natural filtration generated by the moves up to time N. We saw that the natural filtration can be equivalently generated by any of the above sets of random variables that contain the information on all the moves, i.e., ℱ0 = {∅, Ω}, ℱN = σ(ω1,...,ωN)= σ(M1,...,MN)= σ({Uk :1 ≤ n ≤ N}), etc. For every N, {ℱn}1≤n≤N is the natural filtration for the binomial model up to time N, where ℱn ⊂ ℱn+1 for all n ≥ 0. In the limiting case of N →∞ we have , or equivalently: . Hence, ℱ∞ contains all the possible events in the binomial model with infinite moves for which we can compute probabilities of occurrence. For every given N ≥ 1, (ΩN, ℱN, ℙ) is a probability space on which we can define any random variable that may depend on up to N numbers of moves (i.e., random variables that are ℱn-measurable for 1 ≤ n ≤ N). Passing to the limiting case, the triplet (Ω∞, ℱ∞, ℙ) is then a probability space for any random variable that depends on any number of moves (i.e., random variables that are ℱn-measurable for all n ≥ 1), i.e., (Ω∞, ℱ∞, ℙ, {ℱn}n≥1) is a filtered probability space.
Recall that the symmetric random walk {Mn}n≥0 is defined by M0 = 0 and
for n, k ≥ 1. Let us summarize the properties of the symmetric random walk.
- It is a martingale w.r.t. {ℱn}n≥0 and has zero mean, E[Mn] ≡ 0 for all times n ≥ 0.
It is a square-integrable process, i.e., E[Mn2] < ∞, such that Var(Mn)= n and Cov(Mn,Mk)= n ∧ k, for n, k ≥ 0.
Proof. Calculate the variance and covariance of this process as follows:
We note that the above result is also easily proven by using the independence of Mn − Mk and Mk, for n ≥ k.
- It is a process with independent and stationary increments such that E[Mn − Mk]=0 and Var(Mn − Mk) = |n − k|, for n, k ≥ 0.
Proof. The independence and stationarity of increments are easily proved (as shown in a previous example). The expected value and variance are
The next step toward Brownian motion (BM) is the construction of a scaled symmetric random walk. We denote this process by W(n) and it will be derived from a symmetric random walk. Fix n ∊ ℕ. For t ≥ 0, define provided that nt is an integer. Suppose that nt is noninteger. Find s such that ns is an integer and ns < nt > ns +1 holds. Since ns is the largest integer less than or equal to nt, it is equal to . We hence define to obtain the following general formula of the scaled symmetric random walk:
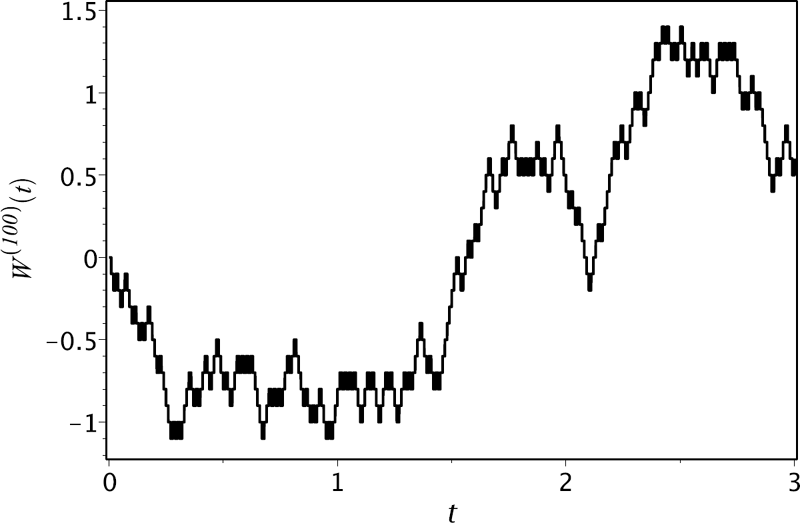
As is seen from (10.6), W(n) is a continuous-time stochastic process with piecewise-constant right-continuous sample paths. At every time index , the process has a jump of size . Figure 10.1 depicts a sample path of this process for n = 100.
Clearly, the time-t realization W(n)(t) depends on the first up or down moves ω1,...,ωk, with . Note that since the process W(n) is constant on the time interval, we have . Thus, W(n)(t) is measurable w.r.t. . Hence, the filtration defined by is in fact the natural filtration for the process {W(n)(t)}t≥0. The process is hence adapted to . Since the scaled symmetric random walk is obtained by re-scaling (and constant interpolation) of the symmetric random walk, it inherits the properties of the original process. For all t, s ≥ 0 such that ns and nt are integers, we have
- E [W(n)(t) |ℱ(n)(s)] = W(n)(s) (martingale property) for 0 ≤ s ≤ t, and zero time-t expectation E[W(n)(t)] = 0;
Var(W(n)(t)) = t and Cov(W(n)(t),W(n)(s)) = t ∧ s.
- Let be such that ntj is an integer for all 0 ≤ j ≤ n, then the increments are independent and stationary with mean zero and variance for 1 ≤ j ≤ n.
The proof of these properties is left as an exercise for the reader (see Exercise 10.5).
An important characteristic of a stochastic process is the so-called quadratic variation. This quantity is a random variable that characterizes the variability of a stochastic process. For t ≥ 0, the quadratic variation of the scaled random walk W(n) on [0,t], denoted by [W(n),W(n)](t), is calculated as follows on any given path ω ∊ Ω. We go from time 0 to time t along the path, calculating the increments over each time step of size . All these increments are then squared and summed up. For t ≥ 0, such that is an integer,
The above quadratic variation was calculated to be time t for any path or outcome ω. For every path of the scaled random walk, the quadratic variation [W(n),W(n)](t) is hence a constant and equal to t, i.e., [W(n),W(n)](t)= t is a constant random variable. Recall that the variance of W(n)(t) also has the same value.
The probability distribution of Mm is that of a shifted and scaled binomial random variable: Mm = 2Um − m with Um ~ . Therefore, the mass probabilities of the scaled random walk are also binomial ones:
For example, W(100)(0.1) (with n = 100,t = 0.1, nt = 10) takes its value on the set
The probability mass function is plotted in Figure 10.2.

Let us find the limiting distribution of W(n)(t), as n →∞, for fixed t > 0. Since W(n)(t) is equal to a scaled sum of i.i.d. random variables Xk, k ≥ 1, with E[X1] = 0 and Var(X1) = 1, the Central Limit Theorem can be applied to yield
where Z ~ Norm(0, 1). In the above derivation, we use the property , so . Thus,
To demonstrate the convergence of the probability distribution of W(n)(t) to the normal distribution, we plot and compare a histogram for W(n)(t) and a normal density curve for Norm(0,t) in Figure 10.3. The histogram is constructed for W(100)(0.1) by replacing each mass probability in Figure 10.2 by a bar with width 0.2 (since the distance between mass points equals 0.2) and height chosen so that the area of the bar is equal to the respective mass probability. For example, , hence we draw a histogram bar centered at 0.2 with width 0.2 and height . As a result, the total area of the histogram is one (as well as the area under the normal curve). Note the close agreement between the histogram and the normal density in Figure 10.3.

Comparison of the histogram constructed for W(100)(0:1) and the density curve for Norm(0; 0:1).
The limit of scaled random walks {W(n)(t)}t≥0 taken simultaneously, as n →∞, for all t ∊ [0,T], T> 0, gives us a new continuous-time stochastic process called Brownian motion. It is denoted by {W(t)}t≥0. Brownian motion can be viewed as a scaled random walk with infinitesimally small steps so that the process moves equally likely upward or downward by in each infinitesimal time interval dt. To govern the behaviour of Brownian motion, the number of (up or down) moves becomes infinite in any time interval. Equivalently, if each move is like a coin toss, then the coin needs to be tossed “infinitely fast.” Thus, W(t), for all t > 0, can be viewed as a function of an uncountably infinite sequence of elementary moves (or coin tosses). Different outcomes (sequences of ω’s) produce different sample paths. Any particular outcome produces a particular path . Although sample paths of W(n) are piecewise-constant functions of t that are discontinuous at t = k/n, k ≥ 1, the size of jumps at the points of discontinuity goes to zero, as n → ∞. Moreover, the length of intervals where W(n) is constant goes to zero as n → ∞, as well. In the limiting case, the Brownian paths become continuous everywhere and nonconstant on any interval no matter how small.
Let us summarize the differences between a scaled random walk and Brownian motion , in the following table.
W (n)(t) |
W (t) |
|
|---|---|---|
RANGE: |
discrete and bounded |
continuous on (−∞, ∞) |
DISTRIBUTION: |
approximately normal |
normal |
SAMPLE PATHS: |
piecewise-constant |
continuous and nonconstant on any time interval |
10.2.2 Formal Definition and Basic Properties of Brownian Motion
A real-valued continuous-time stochastic process {W(t)}t≥0 defined on a probability space (Ω, ℱ, ℙ) is called a standard Brownian motion if it satisfies the following.
- (Almost every path starts at the origin.) W (0) = 0 with probability one.
- (Independence of nonoverlapping increments) For all n ∊ ℕ and every choice of time partition 0 ≤ t0 <t1 < ... <tn, the increments are jointly independent.
(Normality of any increment) For all 0 ≤ s < t, the increment W (t)−W (s) is normally distributed with mean 0 and variance t − s:
- (Continuity of paths) For almost all ω ∊ Ω (i.e., with probability one), the sample path W (t, ω) is a continuous function of time t.

Brownian motion (which we also abbreviate as BM) is named after the botanist Robert Brown who was the first to observe and describe the motion of a pollen particle suspended in fluid as an irregular random motion. In 1900, Louis Bachelier used Brownian motion as a model for movements of stock prices in his mathematical theory of speculations. In 1905, Albert Einstein obtained differential equations for the distribution function of Brownian motion. He argued that the random movement observed by Robert Brown is due to bombardment of the particle by molecules of the fluid. However, it was Norbert Wiener who constructed the mathematical foundation of BM as a stochastic process in 1931. Sometimes, this process is also called the Wiener process and this fact explains the notation used to denote Brownian motion by the letter W.
Although the processes W(n) and W have different probability distributions and sample paths, some of the properties of a scaled random walk are inherited by Brownian motion. For example, by making use of the independence of increments for adjacent (or nonoverlapping) time intervals W (t)−W (s) and W (s)−W (0) = W (s) and the fact that E[W (t)] = E[W (s)] = 0, the covariance of W (s) and W (t), 0 ≤ s ≤ t, is given by
In general, we have
Another feature that BM and symmetric random walks have in common is the martingale property. The natural filtration for Brownian motion is the σ-algebra generated by the Brownian motion observed up to time t ≥ 0:
BM is hence automatically adapted to the filtration , i.e., W(t) is obviously ℱtW -measurable for every t ≥ 0. In what follows we will assume any appropriate filtration for BM (of which is one such filtration) such that all of the defining properties of Brownian motion hold. For all 0 ≤ u ≤ s < t, W (t) − W (s) is independent of W (u) and hence it follows that the increment W (t) − W (s) is independent of the σ-algebra ℱsW generated by all Brownian paths up to time s. So, for any appropriate filtration for BM, we must have that W (t) − W (s) is independent of ℱs. In what follows, we shall also use the shorthand notation for the conditional expectation of a random variable X w.r.t. a given σ-algebra ℱt, i.e., we shall often interchangeably write E[X |ℱt] ≡ Et[X] (for shorthand) wherever it is convenient.
Below we consider some examples of processes that are martingales w.r.t. any assumed filtration {ℱt}t≥0 for BM. One such process is Brownian motion. For any finite time t ≥ 0, the BM process is obviously integrable since . In fact, this expectation is computed exactly since , where Z ~ Norm(0,1), giving .
Brownian motion is a martingale w.r.t. {ℱt}t≥0.
Proof. BM is adapted to its natural filtration and hence assumed adapted to {ℱt}t≥0. Since we already showed that W (t) is integrable, we need only show that E[W (t) |ℱs] ≡ Es[W (t)] = W (s), for 0 ≤ s ≤ t. Now, W (s) is ℱs-measurable and W (t) − W (s) is independent of ℱs, hence
The next example shows that squaring BM and subtracting by time gives a martingale.
Example 10.1.
Prove that {W2(t) − t}t≥0 is a martingale w.r.t. any filtration {ℱt}t≥0 for BM.
Solution. Since W (t) is ℱt-measurable, then Xt := W2(t) − t is ℱt-measurable. Moreover, . It remains to show that Es[Xt] = Xs, for 0 ≤ s ≤ t. We now calculate the conditional time-s expectation of W2(t) for s ≤ t, by using the fact that W (s) and W2(s) are ℱs-measurable and that W (t) − W (s) and (W (t) − W (s))2 are independent of ℱs:
Therefore, Es [W2(t) − t] =(t − s)+ W2(s) − t = W2(s) − s.
We note that an alternative way to compute Es [W2(t) ≡ E W2(t) |ℱs is to use the fact that W (s) is ℱs -measurable and Y ≡ W (t) − W (s) is independent of ℱs. Hence, , where Proposition 6.7 gives . [Note that in Proposition 6.7 we have set .]
The following is an example of a so-called exponential martingale. This type of martingale will turn out to be very useful when pricing options. Recall is the moment generating function (MGF) of a normal random variable X ~ Norm(μ, σ2). Hence, the MGF of W (t) is given by since W (t) ~ Norm(0,t).
Prove that , for all α ∊ ℝ, is a martingale w.r.t. any filtration {ℱt}t≥0 for BM.
Solution. Since W (t) is ℱt-measurable, then is ℱt-measurable. The process is integrable since . We now show that Es[Xt]= Xs, for 0 ≤ s ≤ t. Indeed, since is ℱs-measurable and W (t) − W (s) ~ Norm(0, t − s) is independent of ℱs:
Therefore, .
10.2.3 Multivariate Distribution of Brownian Motion
The random variables W (t1),W(t2),...,W (tn) are jointly normally distributed for all time points 0 ≤ t1 <t2 < ... <tn. Therefore, their joint n-variate distribution is determined by the mean vector and covariance matrix. In accordance with (10.8) and (10.9), we have
for 1 ≤ i, j ≤ n. Therefore, W := [W (t1),W (t2), ..., W (tn)⊤, where each component random variable corresponds to the Brownian path at the respective time points, has the n-variate normal distribution with mean vector zero and covariance matrix
Thus, the joint PDF is given by (10.1) with μ = 0 and covaraince matrix C in (10.10):
Example 10.3.
Let 0 < t1 < t2 < t3. Find the probability distribution of
Solution. The vector W = [W (t1),W (t2),W (t3)]⊤ has the trivariate normal distribution:
Set b = [1, −2, 3]⊤ . Then, in accordance with (10.3), W (t1) − 2W (t2)+3W (t3) = b⊤ W is a scalar normal random variable with mean b⊤ 0 ≡ 0 and variance
Alternatively, by using the property that a linear combination of normal random variables is again a normal variate, we have that W (t1)−2W (t2)+3W (t3) is normally distributed with mean
and variance
Example 10.4.
Consider a standard BM. Calculate the following probabilities:
- (a) ℙ(W (t) ≤ 0) for t> 0;
- (b) ℙ(W(1) ≤ 0,W(2) ≤ 0).
Solution.
- (a) Since for all , we have
- (b) Using the independence of the increments , where Z1 and Z2 are independent standard normal random variables with joint PDF , we obtain
Not surprisingly, this example verifies that W (1) and W (2) are dependent random variables since the joint probability
10.2.4 The Markov Property and the Transition PDF
Our goal is the derivation of the transition probability distribution of Brownian motion. In particular, given a filtration {ℱt}t≥0 for BM, we want to derive a formula for calculating conditional probabilities of the form
Our approach is based on two properties of Brownian motion, namely, time and space homogeneity and the Markov property.
Let {W (t)}t≥0 be a standard Brownian motion and let x ∊ ℝ. The process W(x) defined by
is a Brownian motion. Standard BM W and W(x) have identical increments: W(x) (t + s) − W(x)(t) = W (t + s) − W (t), s> 0,t ≥ 0. Hence, W(x) is a continuous-time stochastic process with the same independent normal increments as W and continuous sample paths. The only difference w.r.t. standard BM is that this process starts at an arbitrary real value x: W(x)(0) = x. The property that x+W(t) is Brownian motion for all x is called the space homogeneity. Another property of BM is its time homogeneity, meaning that the process defined by , is Brownian motion for any fixed T ≥ 0. In other words, translation of a Brownian sample path along both space and time axes gives us again a Brownian path.
Brownian motion is a Markov process.
Proof. Fix any (Borel) function h: ℝ → ℝ and take {ℱt}t≥0 as a filtration for BM. We need to show that there exists a (Borel) function g: ℝ → ℝ such that
i.e., this means that E[h(W(t)) |ℱs] = E[h(W (t))|W(s)] for all 0 ≤ s ≤ t. Indeed, since W (s) is ℱs-measurable and Y := W (t) − W (s) is independent of ℱs, we can apply Proposition 6.7, giving
where . In fact, using the density of Z we have .
We remark that, for s = t, this result simply gives g(x)= h(x) and recovers the trivial case that Es[h(W (s))] = h(W (s)), i.e., W (s), and hence h(W (s)), is ℱs-measurable. For s < t, we can also re-express g(x) by using a linear change of integration variables , giving:
where . Below, we shall see that this function has a very special role and is the so-called transition PDF of BM. The above Markov property means that when taking an expectation of a function of BM at a future time t conditional on all the information (path history) of the BM up to an earlier time s < t, it is the same as only conditioning on knowledge of the BM at time s. In particular,
Based on this formula, we can then compute the expected value of h(W (t)) conditional on any value W (s)= x of BM at time s < t as
By this formula it is then clear that p(s, t; x, y) is in fact the conditional PDF of random variable W (t), given W (s), i.e.,
By the Markov property of W we have, for all 0 ≤ s ≤ t and Borel set A,
i.e., this probability is a function of W (s) and A. Hence, the evaluation of probabilities of the form (10.14) and other expectations of functions of BM reduces to calculation of integrals involving p(s, t; x, y). The transition PDF, and its associated transition probability function, plays a pivotal role in the theory of continuous-time Markov processes.
A transition probability function for a continuous-time Markov process {X(t)}t≥0 is a real-valued function P given by the conditional probability
Suppose that the function P is absolutely continuous (w.r.t. the Lebesgue measure) and there exists a real-valued nonnegative function p such that
This function p is called a transition PDF of the process X. By differentiating (10.15), we obtain
By definition, the transition probability function P and transition PDF p are, respectively, the conditional CDF and PDF of random variable X(t) given a value for X(s):
The CDF P(s, t; x, y) hence represents the probability that the value, X(t), of the process at time t is at most y given that it has known value X(s)= x at an earlier time s < t. In other words, in terms of a path-wise description, it represents the probability of the event . The transition PDF represents the density of such paths in an infinitesimal interval dy about the value y, i.e., we can formally write
An important class of processes occurring in many models of finance and other fields is one in which the transition CDF (and PDF) can be written as a function of the difference t − s of the time variables s and t. This property is stated formally below.
A stochastic process {X(t)}t≥0 is called time-homogeneous if, for all ,
If we deal with a time-homogeneous process X, then the probability distribution function for the transition X(s) = x → X(t) = y is a function of the time increment t − s. That is, the time variables t and s occur as the difference of the two. Thus, the transition PDF can be written as a function of three arguments: p(t; x, y). We think of the value x as the starting value of the process and y as the endpoint value of the process after a time lapse t > 0. The two versions of the transition PDF relate to each other as follows (since (s + t) − s = t):
Transition probabilities of a time-homogeneous process X are calculated by integrating the transition PDF p(t; x, y):
Brownian motion W is a Markov process, hence it is possible to define its transition probability function. Since we can write W (t) as a sum W (s)+(W (t) − W (s)), where the increment is independent of W (s), for s < t, the conditional distribution of W (t) given W (s) (i.e., conditional on a given value W (s) = x) is normal. This can be seen by a straightforward application of (10.5), where we identify , and hence
So the conditional CDF is given by , where is the standard normal CDF. This gives the transition probability function P, which can also be derived as follows:
where Z ~ Norm(0, 1). The transition PDF for BM is hence:
Note that this is entirely consistent with the expression we obtained above just after the proof of the Markov property of Brownian motion. As is seen from (10.18), the transition PDF of Brownian motion is a function of the spatial point difference x − y (thanks to the space-homogeneity property) and time difference t − s (thanks to the time-homogeneity property). The transition distribution of BM does not change with any shift in time and in space. This property is seen by letting p0(t; x) be the PDF of W (t), i.e.,
Then, the transition PDF p is given by
In the previous section, we obtained the joint PDF of the path skeleton, W (t1),...,W (tn), of Brownian motion evaluated at n arbitrary time points 0 = t0 < t1 < t2 < ... < tn. The resulting n-variate Gaussian distribution formula in (10.11) looks somewhat complicated since it involves the evaluation of the inverse of the covariance matrix C given in (10.10). However, by using the Markov property of Brownian motion, we can derive a simpler expression for the joint density. As is well known, a joint PDF of a random vector can be expressed as a product of marginal and conditional univariate densities. So, we have
Applying the Markov property gives us the following equivalences in distribution:
Thus, we obtain
where fW (t1)|W(t0)(x1 | x0) ≡ fW (t1)(x1) = p0(t1; x1) since W (t0) ≡ W (0) = x0 ≡ 0 for a standard Brownian motion. So now we have two formulas, (10.11) and (10.21), of the joint PDF fW of Brownian motion on n time points. However, one can show that they are equivalent (see Exercise 10.17). Equation (10.21) clearly shows that the joint PDF of a Brownian path along any discrete set of time points is the product of the transition PDF for BM for each time step.
10.2.5 Quadratic Variation and Nondifferentiability of Paths
Although sample paths of Brownian motion , are almost surely, i.e., with probability one, continuous functions of time index t, they do not look like regular functions that appear in a textbook on calculus. First, Brownian sample paths are fractals, meaning that any zoomed-in part of a Brownian path looks very much the same as the original trajectory. Second, Brownian sample paths are (almost surely) not monotone or linear in any finite interval (t, t + δt) and are not differentiable (w.r.t. t) at any point. A formal proof of the second statement is based on the concept of the variation of a function, but let us first provide some probabilistic arguments against the differentiability of W(t). Consider a finite difference
Clearly, for any κ > 0,
Therefore, the ratio is unbounded, as δ t → 0, with probability one. So the ratio in (10.22) cannot (almost surely) converge to some finite limit. Recall that for a differentiable function we have the convergence .
The nonnegative quantity , defined by
where the limit is taken over all possible partitions a = t0 < t1 < ... < tn = b of [a, b] shrinking as n → ∞ and , is called a p-variation (for p > 0) of a function , then f is said to be a function of bounded p-variation on [a, b].
Of particular interest are the first (p = 1) and quadratic (second) (p = 2) variations. Let us consider regular functions such as monotone and differentiable functions and let us find their variations.
- Bounded monotone functions have bounded first variations.
- Differentiable functions with a bounded derivative have bounded first variations.
- The quadratic variation of a differentiable function with a bounded derivative is zero.
Proof.
Consider a function f that is monotone on [a, b]. Assume that f is nondecreasing. Then, for any partition ,
since f(ti) ≥ f(ti−1). Therefore, the first variation of a nondecreasing (increasing) function f is equal to f(b)−f(a). For a nonincreasing (decreasing) function, . By combining these two cases, we obtain .
Now, consider a differentiable function f ∊ D(a, b) with a bounded derivative |f'(t)| ≤ M < ∞, for all t ∊ (a, b). By the mean value theorem, for u, v ∊ (a, b) with u < v, there exists t ∊ [u, v] such that . Therefore, for every partition of [a, b], we obtain
where . Therefore,
Moreover, assuming that |f'| is integrable on [a, b], we obtain that
- First, let us find the upper bound of the sum of squared increments:
Since , the upper bound converges to zero, hence the quadratic variation is zero.
Now, we turn our attention to Brownian motion. In the theorem that follows, we prove that the first variation of BM is infinite and the second variation is nonzero (almost surely). Therefore, almost surely, a Brownian path cannot be monotone on any time interval since otherwise its first variation on that interval would be finite. Moreover, a Brownian sample path is not differentiable w.r.t. t, since otherwise a differentiable path would have zero quadratic variation. Since Brownian motion is time and space homogeneous, it is sufficient to consider the case with a standard BM on the interval [0,t]. Note that it is customary to denote the quadratic variation of the BM process W on [0,t] by [W, W](t).
.
Proof. Let us first prove that the quadratic variation of BM on [0,t] is finite and equals t. Consider a partition 0 = t0 < t1 < ... < tn = t of [0,t]. Find the expected value and variance of :
where we use the property with Z ~ Norm(0, 1) and hence
Therefore, . The variance of a random variable is zero iff it is (a.s.) a constant. Thus, .
Now, consider the first variation of BM. We find a lower bound of the partial sum of the absolute value of Brownian increments:
In the limiting case, . It can be shown that almost every path of BM is absolutely continuous, therefore (a.s.)
[Note that we are not proving the known absolute continuity of Brownian paths.] Thus, the first variation of BM, given by , is infinite since sn is bounded from below by a ratio converging to .
The results of Theorem 10.4 are in agreement with similar properties of the scaled random walk. In (10.7), we proved that [W(n), W(n)](t) = t. So the quadratic variations of the processes W and W(n) are the same. Moreover, one can show that the first variation of W(n) on [0,t] is equal to (given that nt is an integer). As n → ∞, scaled random walks W(n) converge to Brownian motion and .
10.3 Some Processes Derived from Brownian Motion
10.3.1 Drifted Brownian Motion
Let μ and σ > 0 be real constants. A scaled Brownian motion with linear drift, denoted by W(μ,σ), is defined by
We call this process (and its extensions described below) drifted Brownian motion. The expected value and variance of W(μ,σ)(t) are:
Since W(t) is normally distributed, the sum μt + σW(t) is a normal random variable as well. Moreover, any increment of drifted Brownian motion, W(μ,σ)(t) − W(μ,σ)(s), with 0 ≤ s < t, is normally distributed:
where Z ~ Norm(0, 1). Let us find the transition probability law of the drifted BM. Since Brownian motion is a homogeneous process, it is sufficient to find the probability distribution of the time-t value of a BM with drift:
The PDF of W(μ,σ)(t) is then
Therefore, the transition probability distribution function and transition PDF for the process are, respectively,
for 0 ≤ s < t and x, y ∈ ℝ. Clearly, the transition probability distribution is the same if the underlying BM is not a standard one and is starting at some nonzero point. A drifted BM, , starting at x0 ∊ ℝ, is
Another possible extension is the case where the drift and scale parameters are generally time-dependent functions, μ = μ(t) and σ = σ(t). The drifted BM starting at x0 takes the following form:
10.3.2 Geometric Brownian Motion
Geometric Brownian motion (GBM) is the most well-known stochastic model for modelling positive asset price processes and pricing contingent claims. It is a keystone of the Black–Scholes–Merton theory of option pricing. However, from the mathematical point of view, the GBM is just an exponential function of a drifted Brownian motion. For constant drift μ and volatility parameter σ, GBM is defined by
The process starts at S0 = ex0, since W(μ,σ) (0) = W(0) = 0. This process is hence strictly positive for all t ≥ 0. Since S(t) is an exponential function of a normal variable, the probability distribution of the time-t realization of GBM is log-normal. The CDF of S(t) is
for x > 0. The PDF of S(t) can be obtained by differentiating the above CDF:
By combining the expression (10.26) written for S(t1) and S(t0) with 0 ≤ t0 <t1, we can express S(t1) in terms of S(t0) as follows:
where . This proves that GBM is a time-homogeneous process and its transition PDF is, for any 0 ≤ s < t, x; y > 0,
10.3.3 Brownian Bridge
A bridge process is obtained by conditioning on the value of the original process at some future time. For example, consider a standard Brownian motion pinned at the origin at some time T > 0, i.e., W(0) = W(T) = 0. As a result, we obtain a continuous time process defined for time t ∊ [0,T] such that its probability distribution is the distribution of a standard BM conditional on W(T) = 0. This process is called a standard Brownian bridge. We shall denote it by or simply B. Figure 10.5 depicts some sample paths of this process for T = 1. The process can be expressed in terms of a standard BM as follows:
![Figure showing sample paths of a standard Brownian bridge for t ∈ [0; 1]. Note that all paths begin and end at value zero.](http://imgdetail.ebookreading.net/math_science_engineering/23/9781439892435/9781439892435__financial-mathematics__9781439892435__image__fig10-5.png)
Sample paths of a standard Brownian bridge for t ∈ [0; 1]. Note that all paths begin and end at value zero.
First, we show that it satisfies the boundary condition B(0) = B(T) = 0:
Second, we show that realizations of the Brownian bridge have the same probability distribution as those of the Brownian motion W(t) conditional on W(T) = 0. For all t ∊ (0,T), the time-t realization B(t) is normally distributed as a linear combination of normal random variables. The mean and variance are, respectively,
Let us find the conditional distribution of W(t) | W(T). Since [W(t),W(T)] is jointly normally distributed with zero mean vector and covariance matrix , the conditional distribution is again normal. Applying (10.5) gives the probability distribution of W(t), given W(T) = y, as normal with mean and variance , i.e., . Therefore, for the standard Brownian bridge (pinned at the origin: W(0) = W(T) = y = 0),
On the other hand, the conditional PDF for W (t) | W (T) can be expressed in terms of the transition PDF of BM given in (10.20) as follows:
Simplifying the exponent in the above expression gives
Finally, we obtain
Again, we conclude that for 0 < t < T.
In general, the Brownian bridge from a to b on [0,T], denoted by , is obtained by adding a linear drift function to a standard Brownian bridge (from 0 to 0):
Since adding a nonrandom function to a normally distributed random variable again gives a normal random variable, the realizations of a Brownian bridge are normally distributed:
10.3.4 Gaussian Processes
Most of the continuous-time processes we have considered so far belong to the class of Gaussian processes. The most well-known representative of such a class is Brownian motion. Other examples of Gaussian processes include BM with drift and the Brownian bridge process. Gaussian processes are so named because their realizations have a normal probability distribution (which is also called a Gaussian distribution).
A continuous-time process {X(t)}t≥0 is called a Gaussian process, if for every partition 0 ≤ t1 <t2 < ... <tn, the random variables X(t1),X(t2),...,X(tn) are jointly normally distributed.
The probability distribution of a normal vector X = X(t1),X(t2),...,X(tn)⊤ is determined by the mean vector and covariance matrix. Thus, a Gaussian process is determined by the mean value function defined by mX (t) := E[X(t)] and covariance function defined by cX (t, s) := Cov(X(t),X(s)) = E[(X(t) − mX (t))(X(s) − mX (s))], for t, s ≥ 0. The probability distribution of the time-t realization is normal: X(t) ~ Norm (mX (t),cX (t, t)) for all t> 0. The probability distribution of the vector X is Normn(μ, C) with
The function mX (t) defines a curve on the time-space plane where the sample paths of {X(t)} concentrate around it.
Examples of Gaussian processes include the following processes:
- A constant distribution process X(t) ≡ Z, where Z ~ Norm(a, b2), with mX (t)= a and cX (t, s)= b2;
A piecewise constant process , where Zk ~ Norm(ak,bk2), k ∊ ℕ0, are independent random variables, with and , i.e., the covariance function is zero unless , in which case .
Example 10.5.
Let be i.i.d. standard normal random variables and define . Show that {X(t)}t≥0 is a Gaussian process. Find its mean function and covariance function.
Solution. For any time t ≥ 0, X(t) is a sum of standard normals, hence X(t) is normal. Therefore, any finite-dimensional distribution of the process X is multivariate normal as well. The expected value and variance of X(t) are
For 0 ≤ s < t we have
Thus, the covariance of X(s) and X(t) is
The above argument applies similarly if we assume s ≥ t, giving . Thus, mX (t) = 0 and .
Clearly, Brownian motion and some other processes derived from it are Gaussian processes.
- Standard Brownian motion is a Gaussian process with m(t) = 0 and c(t, s)= t ∧ s, for s, t ≥ 0. Moreover, a Gaussian process having such covariance and mean functions and continuous sample paths is a standard Brownian motion (see Exercise 10.18).
- Brownian motion starting at x ∊ ℝ is a Gaussian process with m(t)= x and c(s, t)= s ∧ t, s, t ≥ 0.
- Clearly, adding a deterministic function to a Gaussian process produces another Gaussian process. Therefore, the drifted Brownian motion starting at , is a Gaussian process with m(t)= x+μt and c(s, t)= σ2 (s∧t), s, t ≥ 0. The drifted BM with time-dependent drift μ(t) and volatility σ(t) is a Gaussian process where m(t)= x + μ(t)t and c(s, t)= σ(s)σ(t)(s ∧ t).
- The standard Brownian bridge from 0 to 0 on [0,T] is a Gaussian process with mean m(t) = 0 and .
Proof. The standard Brownian bridge is the process . For s, t ∊ [0,T], we simply calculate the mean and covariance functions as follows:
- The general Brownian bridge from a to b on [0,T] is a Gaussian process with and . The proof is left as an exercise for the reader (see Exercise 10.19).
- Geometric Brownian motion is not a Gaussian process, but the logarithm of GBM is so (see Exercise 10.20).
10.4 First Hitting Times and Maximum and Minimum of Brownian Motion
From , Section 6.3.7, we recall the discussion and basic definitions of first passage times for a stochastic process. We are now interested in developing various formulae for the distribution of first passage times, the distribution of the sampled maximum (or minimum) up to a given time t > 0, as well as the joint distribution of the sampled maximum (or minimum) and the process value at a given time t > 0 for standard BM as well as translated and scaled BM with drift.
10.4.1 The Reflection Principle: Standard Brownian Motion
Let us recall some basic definitions from Section 6.3.7 that we now specialize to standard BM, W = {W (t)}t≥0, under a given (fixed) measure ℙ. The first hitting time, to a given level m ∊ ℝ, for standard BM is defined by
We recall that either terminology, first hitting time or first passage time, is equivalent since the paths of W are continuous (a.s.). In what follows we can equally say that is a first hitting time or a first passage time to level m. The sampled maximum and minimum of W, from time 0 to time t ≥ 0, are respectively denoted by
and
Note: W (0) = M(0) = m(0) = 0, M(t) ≥ 0 and M(t) is increasing in t. Similarly, m(t) ≤ 0 and m(t) is decreasing in t. If m > 0, then is the same as the first hitting time up to level m. If m < 0, then is the same as the first hitting time down to level m. Hence, we have the equivalence of events:
The path symmetries and Markov (memoryless) properties of standard BM are key ingredients in what follows. We already know that BM is time and space homogeneous. In particular, {W (t+s)−W (s)}t≥0 is a standard BM for any fixed time s ≥ 0. A more general version of this is the property that is a standard BM, independent of , where is a stopping time w.r.t. a filtration for BM. We don’t prove this latter property but it is a consequence of what is known as the strong Markov property of BM. Based on this property, the distribution of is now easily derived.
(First Hitting Time Distribution for Standard BM). The cumulative distribution function of the first hitting time in (10.32), for a level m ≠ = 0, is given by
and zero for all t ≤ 0.
Proof. We prove the result for |m| = m > 0, as the formula follows for m< 0(−m = |m|) by simple reflection symmetry of BM where −W is also a standard BM. If a BM path lies above m at time t, this implies that the path has already hit level m by time t. By the above strong Markov property of BM, is a standard BM. By spatial symmetry of BM paths, given , i.e., we have the conditional probability . Now, by continuity of BM, note that the event that BM is greater than level m at time t, i.e., W (t) >m, is the same as the joint event that it already hit level , and that . So, we have the equivalence of probabilities:
This gives (10.36) for m > 0 since .
Note: W (t) and are continuous random variables, i.e., ℙ(W (t) >m)= ℙ(W (t) ≥ m) and .
From (10.36) we see that, given an infinite time, BM will eventually hit any finite fixed level with probability one, i.e.,
In the opposing limit, given any m ≠ = 0,
Hence, the function defined by is a proper CDF. The PDF (density) of the first hitting time is given by differentiating (10.36) w.r.t. t, :
An important symmetry, which we state without any proof, is called the reflection principle for standard BM. This states that, given a stopping time (w.r.t. a filtration for BM), the process defined by
is also a standard BM. In particular, if we let , then and every path of is a path of W up to the first hitting time to level m and the reflection of a path of W for time t > τm. Since and W are equivalent realizations of standard BM, this means that every path of a standard Brownian has a reflected path. This is depicted in Figure 10.6.

A sample path of standard BM reaching level m > 0 at the first hitting time and its reected path about level m for times past .
Based on the reflection principle, we can now obtain the probability of the joint event that BM at time t, W (t), is below a value x ∊ ℝ and the sampled maximum of BM in the interval [0,t], M(t), is above level m > 0, where x ≤ m. This then leads to the joint distribution for the pair of random variables M(t),W (t).
(Joint Distribution of M(t),W (t)). For all , we have
Hence, for all t ∊ (0, ∞), the joint PDF of (M(t),W (t)) is
and zero for all other values of m, x.
Proof. As depicted in Figure 10.6, observe that for every Brownian path that hits level m before t > 0 and has value x ≤ m at time t there is a (reflected) Brownian path that has level 2m − x. Indeed, by the reflection principle (taking so for ) and the equivalence in (10.35) for m > 0:
The last equality obtains as follows. Since x ≤ m, then 2m − x ≥ 2m − m = m, which implies , i.e., the reflected BM and hence the BM has already reached level m. This implies that the joint probability is just the probability of the event and so (10.38) obtains since and W are both standard BM. The formula in (10.39) follows by the standard definition of the joint PDF as the second mixed partial derivative of the joint CDF. Note the minus sign here since we are directly differentiating the joint probability in (10.38), which involves {M(t) ≥ m} instead of {M(t) ≥ m}:
P, which is the right-hand side of (10.39).
The joint CDF of (M(t),W (t)) now follows easily by writing the event {W (t) ≤ x} as a union of two mutually exclusive events,
and equating probabilities on both sides,
Isolating the second term on the right-hand side and using (10.38) for the first term on the right-hand side (where ℙ(M(t) > m,W (t) ≤ x)= ℙ(M(t) ≥ m, W (t) ≤ x) since M(t) is continuous) gives the joint CDF for m > 0,x ≤ m,
and for x > m > 0, for m ≤ 0, for all t ∊ (0, ∞). We also see that this joint CDF recovers the joint PDF in (10.39). For m > 0, x ≤ m, it is given by simply differentiating (10.40),
and for all other values of (m, x).
The (marginal) CDF of M(t) follows by setting x = m in (10.40),
for m > 0 and zero for m ≤ 0. Note that this is a CDF for the continuous random variable M(t) where FM(t) is continuous for m ∊ ℝ, monotonically increasing for m > 0, FM(t)(−∞) = 0 and FM(t)(∞) = 1. For m > 0, ,
This therefore recovers the CDF of in (10.36) in the case that m > 0.
The next proposition follows simply from Proposition 10.6 and leads to the joint distribution of the pair (m(t),W (t)), i.e., the sampled minimum of BM in the interval [0,t], m(t), and the value of standard BM at time t.
(Joint Distribution of m(t), W (t)). For all m < 0, m ≤ x < ∞, t ∊ (0, ∞), we have
Hence, for all t ∊ (0, ∞), the joint PDF of (m(t), W (t)) is
and zero otherwise.
Proof. One way to prove the result is to apply the same steps as in the proof of Proposition 10.6, but with arguments applying to a picture that is the reflection (about the vertical axis) of the picture in Figure 10.6. Here we simply make use of the fact that reflected BM defined by {B(t) := −W (t)}t≤0 is also a standard BM. Let . Note that . Since {B(t)}t≥0 is a standard BM, by Proposition 10.6, with values , we have
The left-hand side is re-expressed as:
Substituting , where m < 0, x ≥ m, gives the result in (10.42). The joint density in (10.43) follows by differentiating as in the above proof of (10.39).
The (marginal) CDF of m(t), Fm(t), follows by expressing {W (t) ≥ m} as a union of two mutually exclusive events (note: {m(t) > m} = {m(t) > m,W (t) > m} since {m(t) > m,W (t) ≤ m} = ∅):
Computing probabilities and using (10.42) for x = m > 0 gives
where we used . Hence,
for −∞ <m < 0 and Fm(t)(m) ≡ 1 for m ≥ 0. The reader can easily check that this is a proper CDF for the continuous random variable m(t). Moreover, this also recovers the CDF of the first hitting time in (10.36) for m = −|m| < 0, i.e., we have the equivalence of the CDFs, , for all t > 0,m < 0.
By writing {W (t) ≥ x} = {m(t) ≥ m, W (t) ≥ x}∪{m(t) > m,W (t) ≥ x} and taking probabilities of this disjoint union, while using (10.42), gives another useful relation:
for m < 0, m ≥ x < ∞, t > 0. For given t > 0, the joint CDF of m(t),W (t) follows by using (10.42) and (10.44):
for for x < m < 0, and for m ≥ 0.
Before closing this section we make another important connection to BM that is killed at a given level m. Given m ≠ 0, standard BM killed at level m is standard BM up to the first hitting time at which time the process is “killed and sent to the so-called cemetery state ∂†.” [Remark: We can also define a similar BM that is “frozen or absorbed” at the level m.] Let {Wm(t)}t≥0 denote the standard BM killed at level m, then
For m > 0, according to (10.35), . The event that the process W(m) has not been killed and hence lies below or at any x < m at time t is the joint event that W lies below or at x < m at time t and the maximum of W up to time t is less than m:
Here we used (10.40). Differentiating this expression w.r.t. x gives the density for killed standard BM (starting at W(m)(0) = 0) on its state space x ∊ (−∞,m), m > 0:
where
for x < m, and for x ≥ m. Here p0(t; x), defined in (10.19), is the Gaussian density for standard BM, W . Note that we also readily obtain the transition PDF for the killed BM by the time and space homogeneous property (see (10.20)) with m → m − x,
0 ≤ S < t, −∞ < x,y < m, m > 0
For m < 0, . The event that Wm has not been killed and hence lies at or above a value x > m at time t is the joint event that W lies above or at x > m at time t and the minimum of W up to time t is greater than m:
where we used (10.45). Following the same steps as above gives the density for killed standard BM on its state space x ∊ (m, ∞), m < 0:
where
for x > m and for x ≥ m. Note that this expression is the same as that in (10.49), but now x > m, m < 0.
For any finite time t > 0, it is simple to show that the densities in (10.49) and (10.52) are strictly positive on their respective domains of definition. However, they do not integrate to unity, as is clear from their definitions. In fact, they can be used to obtain the distribution of M(t) and m(t), respectively, and hence to obtain the distribution of the first hitting time . For example, let’s take the case with m > 0. Then, the probability of event is the probability that the process has been killed and is hence in the state ∂† at time t. Hence, the CDF of the first hitting time to level m > 0 is given by
which recovers our previously derived formula in (10.36) for m > 0. We leave it to the reader to verify that the CDF in (10.36) for the first hitting time down to level m < 0 is also recovered by integrating the density in (10.52):
10.4.2 Translated and Scaled Driftless Brownian Motion
Let us now consider the process X = {X(t)}t≥0 as a scaled and translated BM defined as in (10.24), x0 ∊ ℝ,σ > 0, but with zero drift μ = 0:
Hence, all paths of X start at the point X(0) = x0 ∊ ℝ. The relationship between X(t) and W (t) is simply a monotonically increasing mapping, i.e., X(t) = f(W(t)) where . As a consequence, all formulae derived in Section 10.4.1 for the CDF (PDF) of the first hitting time, the maximum, as shown just below.
The first hitting time of the X process to a level m ∊ ℝ, denoted by , is given by the first hitting time of standard BM, W, to the level :
That is, sending m → (m − x0)/σ in for W gives . Similarly, for the sampled maximum and minimum of X, from time 0 to time t ≥ 0, we have the simple relations
and similarly
Note that x0 = MX (0) = mX (0), mX (t) ≤ X(t) ≤ MX (t), MX (t) is increasing and mX (t) is decreasing.
Based on (10.56), the formula in (10.36) directly gives us the CDF of , for all m ∊ ℝ:
Clearly, we have the equivalence of events:
Based on these relations, all relevant formulae for the marginal and joint CDFs immediately follow from those for standard BM upon sending m → (m − x0)/σ and x → (x − x0)/σ in the CDF formulae of Section 10.4.1. For example, using (10.38), for m >x0, x ≤ m:
For all t > 0, the joint CDF of MX (t),X(t) is obtained by sending m → (m − x0)/σ and x → (x − x0)/σ in (10.40):
for . Differentiating gives the joint PDF,
for x < m,x0 <m and zero otherwise.
The (marginal) CDF of M X (t), t > 0, follows from (10.41), upon sending m → (m − x0)/σ,
for m > x0 and zero for m ≤ x0.
Similarly, for t > 0, the joint variables mX (t),X(t) satisfy (from (10.42)):
for x0 > m,x ≥ m and with joint PDF
for x > m,x0 > m and zero otherwise.
Upon sending m → (m − x0)/σ and x → (x − x0)/σ, the relation in (10.45) gives
for m < x0, m ≤ x < ∞, t > 0 and (10.46) gives the joint CDF of mX (t),X(t):
for and .
Formulae for the transition PDF of driftless BM killed at level m and started at x0 < m, or x0 > m, are given by (10.49) or (10.52) upon making the substitution m → (m − x0)/σ and x → (x − x0)/σ.
10.4.3 Brownian Motion with Drift
We now consider BM with a constant drift, i.e., let the process {X(t)}t≥0 be defined by (10.23) for σ = 1:
We remark that it suffices to consider this case, as it also leads directly to the respective formulae for the process defined in (10.24), where the BM is started at an arbitrary point x0 and has arbitrary volatility parameter σ> 0. This is due to the relation
So, the process in (10.24) is obtained by scaling with σ and translating by x0 the process X in (10.68), as in the previous section, and now by applying the additional scaling of the drift, i.e., send . For clarity, we shall discuss this scaling and translation in Section 10.4.3.1.
The sampled maximum and minimum of the process X ≡ W (μ,1) are defined by
and
In contrast to our previous expressions for driftless or standard BM, the drift term is a time-dependent function that is added to the standard (zero drift) BM. Hence, we cannot use the reflection principle in this case. In Chapter 11 we shall see how to implement methods in probability measure changes in order to calculate expectations of random variables that are functionals of standard Brownian motion. A very powerful tool is Girsanov’s Theorem. Section 11.8.1 contains some applications of Girsanov’s Theorem. Here we simply borrow the key results derived in Section 11.8.1 that allow us to derive formulae for the CDF of the first hitting time of drifted BM and other joint event probabilities, PDFs and CDFs for the above sampled maximum and minimum random variables.
Our two main formulae are given by (11.104) and (11.105). The joint CDF in (11.106) and (11.107) are important cases. These were used in Section 11.8.1 to derive the joint PDF of MX (t),X(t) and of mX (t),X(t), given in (11.109) and (11.110). The joint CDF in (11.106) also leads to the useful relation
for x < m,m > 0. To see how this identity arises, we use the definition of the joint PDF of MX (t),X(t) as the second partial derivative of the CDF, i.e., . Hence, for x < m,m > 0, the joint CDF of MX (t),X(t) is expressed equivalently as
Note that . On the other hand, by substituting the expression in (11.109), i.e., , into the first integral above and then repeating the same steps (but now with FM(t),W (t) in the place of ) gives
Hence, (10.72) holds by equating integrands in (10.73) and (10.74).
Note that the probabilities in (10.72) represent the probability for X(t) (or respectively W (t)) to take on a value in an infinitesimal interval around the point x, assuming that the sampled maximum MX (t) (or respectively M(t)) is less than m, i.e., the respective probabilities correspond to a density in x (obtained by differentiating the joint CDF w.r.t. x) times the infinitesimal dx,
and
We have already seen that this last probability is related to the density for standard BM killed at m > 0. This is given by (10.48) and (10.49). The previous probability is similarly related to the density for drifted BM killed at m > 0.
For any m ≠ 0, drifted BM killed at level m is defined as
where is the first hitting time of the drifted BM, X = W (μ,1), to level m. For m > 0,the process X(m) has state space (−∞,m) and starts at zero, as does W(m). Hence, taking any value x <m, the joint CDF FMX (t),X(t)(m, x) is equivalent to the probability that the drifted BM with killing at m lies below x, i.e.,
and the analogue of (10.48) is
Hence, (10.72) is equivalent to
In particular, the density for the drifted killed BM, started at X(m) (0) = 0, is related to the density in (10.49) by
for x < m and zero otherwise. We can rewrite this density in a more convenient form by multiplying and completing the squares in the two exponents,
for x < m and zero otherwise. This expression involves a linear combination of densities for standard BM at any point x ∊ (−∞,m). Note that setting μ = 0 recovers pW(m)in (10.49). In the limit m →∞, this density recovers the density pX (t;0,x) ≡ p0(t; x − μt) for drifted BM, X ≡ W (μ,1) ∊ ℝ, with no killing.
The joint CDF of MX (t),X(t) can be obtained by evaluating a double integral of the joint PDF. Alternatively, since we now have the density pX(m) at hand, we can simply use it to compute a single integral to obtain the joint CDF. Indeed, using (10.80) within the last integral in (10.73):
for x ≤ m,m > 0. For x > m > 0, and for m ≤ 0.
The (marginal) CDF of MX (t) is given by setting x = m in (10.81),
and . The first hitting time up to level m > 0 has CDF
for t > 0, and zero otherwise.
We now consider the case where m < 0. The analogue of (10.72) for the joint pair mX (t),X(t) is
for x > m,m < 0. The derivation is very similar to that given in (10.73) and (10.74). We can relate this to the first hitting time , which is now the first hitting time of the drifted BM down to level m < 0. The process X(m) has state space (m, ∞). The identity in (10.78) is now valid for x >m, m < 0. The analogues of (10.76) and (10.77) are
and
x > m,m < 0. By (10.78), the density pX(m) (t;0,x) for the process X(m) ∊ (m, ∞) is still given by the expression in (10.79), or equivalently in (10.80), but now for x > m, m < 0. The density pX(m) (t;0,x) is identically zero for x ≤ m.
The derivation of the joint CDF of mX (t),X(t) is left as an exercise for the reader. In what follows it is useful to compute the following joint probability (using similar steps as in (10.81)):
for x ≥ m,m < 0. The CDF of the first hitting time down to level m < 0 follows from this expression for x = m:
for t > 0, and zero otherwise. For given t > 0, this expression is also the CDF of mX (t), for −∞ <m ≤ 0, and for m ≥ 0.
Other probabilities related to (10.72) and (10.84) also follow. For example, we can compute the probability that drifted BM process X is within an infinitesimal interval containing x ∊ ℝ jointly with the condition that the process has already hit level m > 0 (i.e., its sampled maximum MX (t) ≥ m). This probability is given by
where we used (10.77) and (10.78). We can write down the explicit expression by combining pX (t;0,x)= p0(t; x − μt) with the density in (10.80), i.e., for m > 0:
For m < 0, a similar derivation gives the probability that the drifted BM process is within an infinitesimal interval jointly with the condition that the process has already hit level m < 0 (i.e., its sampled minimum mX (t) ≤ m):
10.4.3.1 Translated and Scaled Brownian Motion with Drift
All the formulae derived for the process W (μ,1) in the previous section are trivially extended to generate all the corresponding formulae for drifted BM starting at arbitrary x0 ∊ ℝ and with any volatility parameter σ > 0. To see this, consider the process defined by (10.24). According to (10.69),
The sampled maximum of this process is given by
Here we are using M(μ,σ)(t) to denote the sampled maximum of process W (μ,σ). The analogous relation for the sampled minimum mX (t) follows in the obvious manner.
Computing the joint CDF of MX (t),X(t),
where , and . Hence, this is the joint CDF of the random variable pair , where the function is evaluated at arguments . By definition, this is given by the formula for the joint CDF in (10.81) with the variable replacements:
These are precisely the same variable replacements that we saw in Section 10.4.2 for driftless BM. In the case of drifted BM we see that the volatility parameter σ also enters into the adjusted drift. By simply making the above variable replacements in (10.81), we obtain the joint CDF,
for For and . The CDF of MX (t) is given by
By the above analysis it follows that all formulae for any marginal CDF or joint CDF of the random variables MX (t),mX (t),X(t), as well as the CDF of the first hitting time, derived in the previous section for the process X(t)= W (μ,1)(t), now give rise to the respective formulae for the process defined by (10.92) upon making the variable replacements in (10.95). Note that for every differentiation of a (joint) CDF w.r.t. variables x, m, or t, there is an extra factor of that multiplies the expression for the resulting PDF. For example, let X(m) be the process X in (10.92) killed at an upper level m >x0. The density for X(m)(t) is then given by applying (10.95) to (10.80) and multiplying by :
for x0,x < m and zero otherwise. The same expression for the density is also valid for the domain x0,x > m where m is a lower killing level. Similarly, the corresponding expressions for the probability densities in (10.90) and (10.91) follow upon making the variable replacements in (10.95) and multiplying by .
For completeness, we now re-state the formulae in (10.83), (10.87), and (10.88) for the drifted BM in (10.92):
for x, x0 ≥ m,t > 0, and
10.5 Exercises
Exercise 10.1. The PDF of a sum of two continuous random variables X and Y is given by the convolution of the PDF’s and :
- (a) Use (10.102) to show that a sum of two independent standard normal variables results in a normal variable. Find the PDF of such a sum.
- (b) Assuming that and are correlated with Corr(X1,X2)= ρ, find the mean and variance of a1X1 + a2X2 for a1,a2 ∊ ℝ.
- Exercise 10.2. Consider a log-normal random variable with . Find formulae for the following expected values:
- (a) , where K is a real positive constant;
- (b) ;
- (c) E[max(S, K)], where you may use the property
Express your answers in terms of the standard normal CDF function and constants a, b, and K. [Note: This calculation is part of the Black–Scholes–Merton theory of pricing vanilla European style options. K is the constant strike price and S is the random stock price.]
Exercise 10.3. Suppose X =[X1,X2,X3]Τ is a three-dimensional Gaussian (normal) random vector with mean vector zero and covariance matrix
Set Y =1+ X1 − 2X2 + X3 and Z = X1 − 2X3.
- (a) Find the probability distribution of Y .
- (b) Find the probability distribution of the vector [Y, Z]Τ.
- (c) Find a linear combination W = aY + bZ that is independent of X1.
- Exercise 10.4. Take X0 = 0 and define Xk = Xk−1 + Zk, for k =1, 2,...,n, where Zk are i.i.d. standard normals. So we have
Let X ∊ Rn be the vector X =[X1,X2,...,Xn]Τ.
- (a) Show that X is a multivariate normal.
- (b) Use the formula (10.103) to calculate the covariances Cov(Xk,Xj), for 1 ≤ k, j ≤ n.
- (c) Use the answers to part (b) to write a formula for the elements of C = Cov(X, X)= E(X − E[X]) (X − E[X])Τ.
- (d) Write the joint PDF of X.
- Exercise 10.5. Prove the following properties of a scaled symmetric random walk W (n) (t), t ≥ 0. Forall 0 ≤ s ≤ t such that ns and nt are integers, we have
- (a) (the martingale property) and E[W (n)(t)] = 0;
- (b) Var(W (n)(t)) = t and Cov(W (n)(t),W (n)(s)) = s.
- (c) Let 0 ≤ t0 <t1 < ... <tn be such that ntj is an integer for all 0 ≤ j ≤ n, then the increments W (n)(t1) − W (n)(t0),...,W (n)(tn) − W (n)(tn−1) are independent and stationary with mean zero and variance Var(W (n)(tj) − W (n)(tj−1)) = tj − tj −1, 1 ≤ j ≤ n.
- Exercise 10.6. Show that the following processes are standard Brownian motions.
- (a) X(t) := −W (t).
- (b) X(t) := W (T + t) − W (T), where T ∊ (0, ∞).
- (c) X(t) := cW (t/c2), where c ≠ 0 is a real constant.
- (d) X(t) := tW (1/t),t > 0, and X(0) := 0.
- Exercise 10.7. Let {B(t)}t≥0 and {W (t)}t≥0 be two independent Brownian motions. Show that , is also a Brownian motion. Find the coefficient of correlation between B(t) and X(t).
- Exercise 10.8. For Brownian motion {W (t)}t≥0 and its natural filtration , calculate Es[W3(t)] for 0 ≤ s < t.
- Exercise 10.9. Find the distribution of W (1) + W (2) + ... + W (n) for n =1, 2,...
- Exercise 10.10. Let a1,a2,...,an ∊ ℝ and 0 < t1 <t2 < ... <tn. Find the distribution of . Note that the choice with , leads to Asian options.
- Exercise 10.11. Suppose that the processes {X(t)}t≥0 and {Y (t)}t≥0 are respectively given by and , and σy > 0 are real constants. Find the covariance Cov(X(t),Y (s)) for s, t ≥ 0.
- Exercise 10.12. Consider the process X(t) := x0 + μt + σW (t) t ≥ 0, where x0, μ, and σ are real constants. Show that
- Exercise 10.13. By directly calculating partial derivatives, verify that the transition PDF
of standard Brownian motion satisfies the heat equation, also called the diffusion equation:
- Exercise 10.14. Find the transition PDF of {Wn(t)}t≥0 for n = 1; 2; ...
- Exercise 10.15. Find the transition PDF of {Sn(t)}t≥0, where
- Exercise 10.16. Find the transition probability function and transition PDF of the process X(t) := |W (t)|, t ≥ 0. [Hint: make use of {|W (t)| <x} = {−x < W (t) <x}.] We note that this process corresponds to nonnegative standard BM reflected at the origin.
- Exercise 10.17. Show that formulae (10.11) and (10.21) are equivalent by considering successive Brownian increments and applying (10.3).
- Exercise 10.18. Prove that a Gaussian process with the covariance function c(s, t)= s ∧t, mean function m(t) ≡ 0, and continuous sample paths is a standard Brownian motion.
- Exercise 10.19. Show that the mean and covariance functions of the Brownian bridge from a to b on [0,T] are, respectively, and , for s, t ∊ [0,T].
- Exercise 10.20. Find the mean and covariance functions of the GBM process defined by (10.26).
Exercise 10.21. Consider the GBM process . The respective sampled maximum and minimum of this process are defined by
and the first hitting time to a level B > 0 is defined by . Derive expressions for the following:
- (a) , for all t> 0, 0 <x ≤ y < ∞, S0 ≤ y;
- (b) , for all t > 0, S0 ≤ y < ∞;
- (c) , for all t > 0, S0 <B;
- (d) ℙ(MS(t) ≤ y, S(t) ∊ dx), for all t > 0, x ≤ y < ∞, S0 ≤ y;
- (e) ℙ(mS (t) ≥ y, S(t) ≥ x), for all t > 0, 0 <y ≤ x < ∞, S0 ≥ y;
- (f) , for all t > 0, S0 >B;
- (g) ℙ(mS(t) ≥ y, S(t) ∊ dx), for all t > 0, 0 < y ≤ x < ∞, S0 > y.
- Exercise 10.22. Consider the drifted BM defined by X(t) := μt+W (t), t ≥ 0, with MX (t) and mX (t) defined by (10.70) and (10.71). For any T > 0, show that
and
Hint: Use an appropriate conditioning.