Throughout the rest of the chapter and the book we will introduce a few classic data sets that are simple to understand, easy to explain, and can be used commonly across many different data mining techniques, which allows us to compare the performance of these techniques. The most popular of all data sets for data mining is probably the
Iris data set, introduced by Ronald Fisher, in his seminal work on discriminant analysis, “The use of multiple measurements in taxonomic problems” (
Fisher, 1936). Iris is a flowering plant that is widely found across the world. The genus of Iris contains more than 300 different species. Each species exhibits different physical characteristics like shape and size of the flowers and leaves. The Iris data set contains 150 observations of three different species,
Iris setosa,
Iris virginica, and
Iris versicolor, with 50 observations each. Each observation
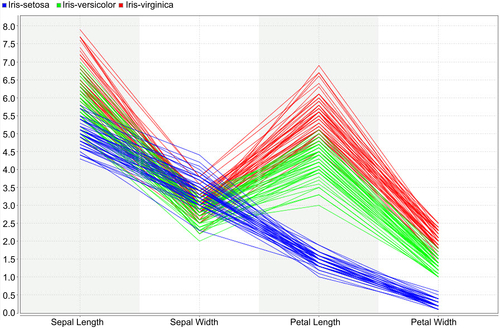
consists of four attributes: sepal length, sepal width, petal length, and petal width. The fifth attribute is the name of the species observed, which takes the values
Iris setosa,
Iris virginica, and
Iris versicolor. Petals are the brightly colored inner part of the flowers and sepals form the outer part of the flower and are usually green in color. In an Iris however, both sepals and petals are purple in color, but can be distinguished from each other by differences in shape (
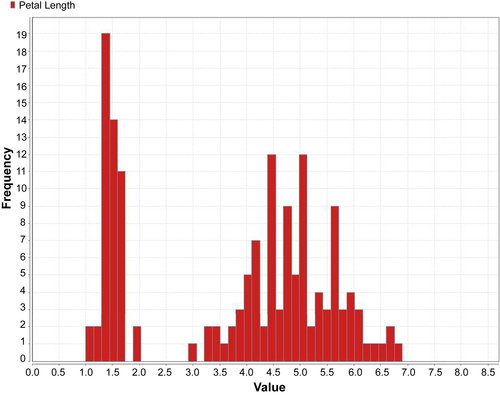
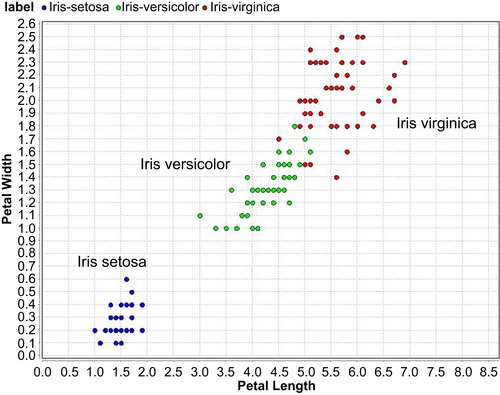
Figure 3.1).
All four attributes in the Iris data set are numeric continuous values measured in centimeters. One of the species,
Iris setosa, can be easily distinguished from the other two using linear regression or simple rules, but separating the
virginica and
versicolor classes requires more complex rules that involve more attributes. The data set is available in all standard data mining tools, such as RapidMiner, or can be downloaded from public websites such as the University of California Irvine – Machine Learning repository (
Bache & Lichman, 2013). This data set and other data sets used in this book can be downloaded from the companion website
www.LearnPredictiveAnalytics.com.
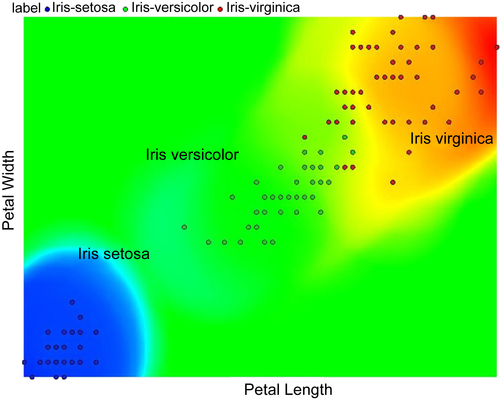
The Iris data set is used for learning data mining mainly because it is simple to understand and explore and can be used to illustrate how different data mining algorithms perform on the same standard data set. The data set extends beyond two dimensions, with three class labels of which one class is easily separable (
Iris setosa) by visual exploration, while classifying the
other two classes is slightly challenging. It helps to reaffirm the classification results that can be derived based on visual rules, and at the same time sets the stage for data mining to build new rules beyond the limits of visual exploration.
3.2.1. Types of Data
Data comes in different formats and types. Understanding the properties of each variable or features or attributes provides information about what kind of operations can be performed on that variable. For example, the temperature in weather data can be expressed as any of the following formats:
▪ Numeric centigrade (31ºC, 33.3ºC) or Fahrenheit (100ºF, 101.45ºF) or on the Kelvin scale
▪ Ordered label as in Hot, Mild, or Cold
▪ Number of days within a year below 0ºC (10 days in a year below freezing)
All of these attributes indicate temperature in a region, but each has different data type. A few of these data types can be converted from one to another.
Numeric or Continuous
Temperature expressed in centigrade or Fahrenheit is numeric and continuous because it can be denoted by numbers and take an infinite number of values between digits. Values are ordered and calculating the difference between values makes sense. Hence we can apply additive and subtractive mathematical operations and logical comparison operations like greater than, less than, and is equal operations.
An integer is a special form of the numeric data type that doesn’t have decimals in the value or more precisely doesn’t have infinite values between consecutive numbers. Usually, they denote a count of something like number of days with temperature less than 0ºC, number of orders, number of children in a family, etc.
If a zero point is defined, numeric becomes a ratio or real data type. Examples include temperature in Kelvin scale, bank account balance, and income. Along with additive and logical operations, ratio operations can be performed with this data type. Both integer and ratio data types are categorized as a numeric data type in most Data Mining tools.
Categorical or Nominal
Categorical data types are variables treated as distinct symbols or just names. The color of the human iris is a categorical data type because it takes a value like black, green, blue, grey, etc. There is no direct relationship among the data values and hence we cannot apply mathematical operators except the logical or “is equal” operator. They are also called a nominal or polynominal data type, derived from the Latin word for “name.”
An ordered data type is a special case of a categorical data type where there is some kind of order among the values. An example of an ordered data type is credit score when expressed in categories such as poor, average, good, and excellent. People with a good score have a credit rating better than average and an excellent rating is a credit score better than the good rating.
Data types are relevant to understanding more about the data and how the data is sourced. Not all data mining tasks can be performed on all data types. For example, the neural network algorithm does not work with categorical data. However, we can convert data from one data type to another using a type conversion process, but this may be accompanied with possible loss of information. For example, credit scores expressed in poor, average, good, and excellent categories can be converted to either 1, 2, 3, and 4 or average underlying numerical scores like 400, 500, 600, and 700 (scores here are just an example). In this type conversion, there is no loss of information. However, conversion from numeric credit score to categories (poor, average, good, and excellent) does incur some loss of information.



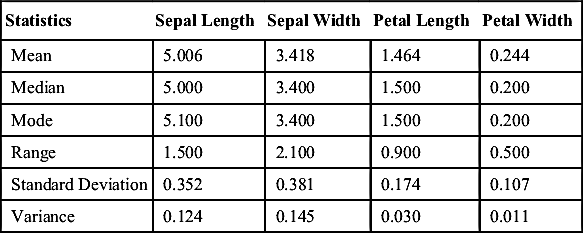

 (3.2)
(3.2)