
Now that we have seen a neural network in action and have gained a basic understanding of how it works by looking over the code, let's dig a little bit deeper into some of the concepts, such as the logistic cost function and the backpropagation algorithm that we implemented to learn the weights.
The logistic cost function that we implemented as the _get_cost method is actually pretty simple to follow since it is the same cost function that we described in the logistic regression section in Chapter 3, A Tour of Machine Learning Classifiers Using Scikit-learn.

Here, ![]() is the sigmoid activation of the
is the sigmoid activation of the ![]() unit in one of the layers which we compute in the forward propagation step:
unit in one of the layers which we compute in the forward propagation step:
Now, let's add a regularization term, which allows us to reduce the degree of overfitting. As you will recall from earlier chapters, the L2 and L1 regularization terms are defined as follows (remember that we don't regularize the bias units):

Although our MLP implementation supports both L1 and L2 regularization, we will now only focus on the L2 regularization term for simplicity. However, the same concepts apply to the L1 regularization term. By adding the L2 regularization term to our logistic cost function, we obtain the following equation:

Since we implemented an MLP for multi-class classification, this returns an output vector of ![]() elements, which we need to compare with the
elements, which we need to compare with the ![]() dimensional target vector in the one-hot encoding representation. For example, the activation of the third layer and the target class (here: class 2) for a particular sample may look like this:
dimensional target vector in the one-hot encoding representation. For example, the activation of the third layer and the target class (here: class 2) for a particular sample may look like this:

Thus, we need to generalize the logistic cost function to all activation units ![]() in our network. So our cost function (without the regularization term) becomes:
in our network. So our cost function (without the regularization term) becomes:

Here, the superscript ![]() is the index of a particular sample in our training set.
is the index of a particular sample in our training set.
The following generalized regularization term may look a little bit complicated at first, but here we are just calculating the sum of all weights of a layer ![]() (without the bias term) that we added to the first column:
(without the bias term) that we added to the first column:

The following equation represents the L2-penalty term:

Remember that our goal is to minimize the cost function ![]() . Thus, we need to calculate the partial derivative of matrix
. Thus, we need to calculate the partial derivative of matrix ![]() with respect to each weight for every layer in the network:
with respect to each weight for every layer in the network:

In the next section, we will talk about the backpropagation algorithm, which allows us to calculate these partial derivatives to minimize the cost function.
Note that ![]() consists of multiple matrices. In a multi-layer perceptron with one hidden unit, we have the weight matrix
consists of multiple matrices. In a multi-layer perceptron with one hidden unit, we have the weight matrix ![]() , which connects the input to the hidden layer, and
, which connects the input to the hidden layer, and ![]() , which connects the hidden layer to the output layer. An intuitive visualization of the matrix
, which connects the hidden layer to the output layer. An intuitive visualization of the matrix ![]() is provided in the following figure:
is provided in the following figure:

In this simplified figure, it may seem that both ![]() and
and ![]() have the same number of rows and columns, which is typically not the case unless we initialize an MLP with the same number of hidden units, output units, and input features.
have the same number of rows and columns, which is typically not the case unless we initialize an MLP with the same number of hidden units, output units, and input features.
If this may sound confusing, stay tuned for the next section where we will discuss the dimensionality of ![]() and
and ![]() in more detail in the context of the backpropagation algorithm.
in more detail in the context of the backpropagation algorithm.
In this section, we will go through the math of backpropagation to understand how you can learn the weights in a neural network very efficiently. Depending on how comfortable you are with mathematical representations, the following equations may seem relatively complicated at first. Many people prefer a bottom-up approach and like to go over the equations step by step to develop an intuition for algorithms. However, if you prefer a top-down approach and want to learn about backpropagation without all the mathematical notations, I recommend you to read the next section Developing your intuition for backpropagation first and revisit this section later.
In the previous section, we saw how to calculate the cost as the difference between the activation of the last layer and the target class label. Now, we will see how the backpropagation algorithm works to update the weights in our MLP model, which we implemented in the _get_gradient method. As we recall from the beginning of this chapter, we first need to apply forward propagation in order to obtain the activation of the output layer, which we formulated as follows:

Concisely, we just forward propagate the input features through the connection in the network as shown here:

In backpropagation, we propagate the error from right to left. We start by calculating the error vector of the output layer:
Here, ![]() is the vector of the true class labels.
is the vector of the true class labels.
Next, we calculate the error term of the hidden layer:

Here,  is simply the derivative of the sigmoid activation function, which we implemented as
is simply the derivative of the sigmoid activation function, which we implemented as _sigmoid_gradient:

Note that the asterisk symbol ![]() means element-wise multiplication in this context.
means element-wise multiplication in this context.





To better understand how we compute the ![]() term, let's walk through it in more detail. In the preceding equation, we multiplied the transpose
term, let's walk through it in more detail. In the preceding equation, we multiplied the transpose ![]() of the
of the ![]() dimensional matrix
dimensional matrix ![]() ; t is the number of output class labels and h is the number of hidden units). Now,
; t is the number of output class labels and h is the number of hidden units). Now, ![]() becomes an
becomes an ![]() dimensional matrix with
dimensional matrix with ![]() , which is a
, which is a ![]() dimensional vector. We then performed a pair-wise multiplication between
dimensional vector. We then performed a pair-wise multiplication between ![]() and
and ![]() , which is also a
, which is also a ![]() dimensional vector. Eventually, after obtaining the
dimensional vector. Eventually, after obtaining the ![]() terms, we can now write the derivation of the cost function as follows:
terms, we can now write the derivation of the cost function as follows:
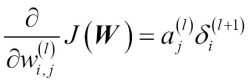
Next, we need to accumulate the partial derivative of every ![]() th node in layer
th node in layer ![]() and the
and the ![]() th error of the node in layer
th error of the node in layer ![]() :
:
Remember that we need to compute ![]() for every sample in the training set. Thus, it is easier to implement it as a vectorized version like in our preceding MLP code implementation:
for every sample in the training set. Thus, it is easier to implement it as a vectorized version like in our preceding MLP code implementation:

After we have accumulated the partial derivatives, we can add the regularization term as follows:
Lastly, after we have computed the gradients, we can now update the weights by taking an opposite step towards the gradient:
To bring everything together, let's summarize backpropagation in the following figure:
