
Chapter 16 Novell Server Troubleshooting
This chapter covers the following testing objectives for Novell Course 3005: Advanced Novell Network Management:
![]() Identify Server Hardware and Operating System Components
Identify Server Hardware and Operating System Components
![]() Troubleshoot and Resolve NetWare Server Issues
Troubleshoot and Resolve NetWare Server Issues
![]() Troubleshoot and Resolve Critical Server Abends
Troubleshoot and Resolve Critical Server Abends
![]() Create a Disaster Recovery Plan
Create a Disaster Recovery Plan
![]() Troubleshoot and Resolve Server Communication Issues
Troubleshoot and Resolve Server Communication Issues
![]() Troubleshoot Network Problems
Troubleshoot Network Problems
Congratulations, you’re a network troubleshooter!
In the previous five troubleshooting chapters, you learned how to apply the NetWare troubleshooting model to a variety of critical service and support responsibilities, including NetWare 6 migration, advanced storage management, iFolder troubleshooting, and high availability with NCS. Then, in Chapter 15, “Novell Troubleshooting Tools,” we built a medical bag full of troubleshooting tools for the NetWare server and distributed workstations.
This chapter is about fitness. The American Academy of Physical Education defines fitness as this:
The ability to carry out daily tasks with vigor and alertness, without undue fatigue and with ample energy. To engage in leisure-time pursuits and to meet the above-average physical stresses encountered in emergency situations.
Sound familiar? As a network troubleshooter, you need to promote fitness within your LAN and WAN. This means monitoring the health and activity of your server and networking components. This penultimate troubleshooting chapter focuses on the NetWare 6 server from a hardware and software perspective:
![]() Getting to know the NetWare server—First, I must prepare you for the rigors of server fitness by reviewing the hardware and software architecture of the NetWare server. This is quite a powerful machine, and you’re in charge. In this first fitness lesson, we’ll explore bus types, memory, scalability, kernels, and high-performance multiprocessing.
Getting to know the NetWare server—First, I must prepare you for the rigors of server fitness by reviewing the hardware and software architecture of the NetWare server. This is quite a powerful machine, and you’re in charge. In this first fitness lesson, we’ll explore bus types, memory, scalability, kernels, and high-performance multiprocessing.
![]() Troubleshooting the NetWare server—Second, we’ll attack server fitness with enthusiasm and a bag full of server troubleshooting tools. In the first half of this lesson, you’ll learn how to troubleshoot a plethora of server problems, including installation, console access, storage, memory, and processing. Then, in the second half, we’ll focus on recovering from server abends and troubleshooting communication bottlenecks.
Troubleshooting the NetWare server—Second, we’ll attack server fitness with enthusiasm and a bag full of server troubleshooting tools. In the first half of this lesson, you’ll learn how to troubleshoot a plethora of server problems, including installation, console access, storage, memory, and processing. Then, in the second half, we’ll focus on recovering from server abends and troubleshooting communication bottlenecks.
Very exciting. I’m short of breath just thinking about it. Let’s start with an overview of the server hardware, software, and learn some tips for high-performance NetWare with multiprocessing.
Test Objective Covered:
![]() Identify Server Hardware and Operating System Components
Identify Server Hardware and Operating System Components
Preventive medicine is the hot new topic in twenty-first century health care—this is a good thing. The main goal is to eliminate server problems before they occur, thereby eliminating the need for painful and expensive diagnosis, treatment, and cure. Preventive maintenance benefits users and the network as a whole.
Unfortunately, there’s no magic pill you can take to keep your network healthy. As CNEs, we must play the role of the good doctor by teaching computer users healthy networking habits and by following our own advice! As a NetWare doctor, you need to follow a regimen of no smoking, good nutrition, and vitamin supplements.
Problem prevention in the physical environment (no smoking) deals with temperature, air quality, and network magnetism. A good rule of thumb is that if you’re comfortable in a room, computers are probably comfortable as well, but certain simple precautions still must be taken in the physical environment to protect network components.
Problem prevention in the electrical environment (good nutrition) deals with the main source of a computer’s diet: electrons. Preventive medicine in this environment is a bit trickier than in the physical one. Here you don’t have nearly as much control over the sources of computer power. You need to be concerned about static electricity, lightning, electromagnetic interference (EMI), radio frequency interference (RFI), power spikes, and power loss. Remember—you are what you eat.
Power protection (vitamin supplements) is the last component of your preventive medicine policy. Uninterruptible power supplies (UPSs) are just as important to your network as vitamins are to your body. They ensure that your workstations and servers get all the nutrition they need, regardless of what happens in the electrical environment. It’s almost like a last line of defense against Murphy’s Law.
In this first server troubleshooting lesson, you’ll get to know the server from three different angles:
![]() Server hardware architecture—First, we’ll explore the interaction between the fundamental components of server hardware, including the data bus, storage drives, processors, and memory. At its most basic level, server hardware is the platform for the NetWare server operating system.
Server hardware architecture—First, we’ll explore the interaction between the fundamental components of server hardware, including the data bus, storage drives, processors, and memory. At its most basic level, server hardware is the platform for the NetWare server operating system.
![]() Server operating system architecture—Next, we’ll move on to the real star of our show: the NetWare server operating system. In this section, we’ll discover the core NetWare kernel and learn how to expand its functionality with NLMs and thread processes.
Server operating system architecture—Next, we’ll move on to the real star of our show: the NetWare server operating system. In this section, we’ll discover the core NetWare kernel and learn how to expand its functionality with NLMs and thread processes.
![]() Using high-performance NetWare—Finally, we’ll end Server 101 with a lesson in high-performance NetWare, including multitasking, multithreading, and multiprocessing. This will help you supercharge your server supercar. Vrooom.
Using high-performance NetWare—Finally, we’ll end Server 101 with a lesson in high-performance NetWare, including multitasking, multithreading, and multiprocessing. This will help you supercharge your server supercar. Vrooom.
Let’s get started with server hardware architecture.
Before we dive into server troubleshooting, we need to understand a little more about how the server works. We need to answer some fundamental questions: How do NICs and cabling connect to the server architecture? What processing load does the server require? How do storage devices communicate internally?
When troubleshooting a server problem, it’s important to know what type of PC bus architecture is used in the server. A bus is a common pathway or channel within a computer that connects two or more devices. An IBM-compatible computer contains several buses, including a processor bus (which provides a parallel data path between the CPU, memory, and peripheral buses), memory bus, I/O bus, and address bus.
Internal communications focus on the server architecture and topology. External communications extend the internal bus to other machines with NIC ports, configurations, and LAN cabling. Figure 16.1 is an illustration of the two sides of LAN communications: internal and external.
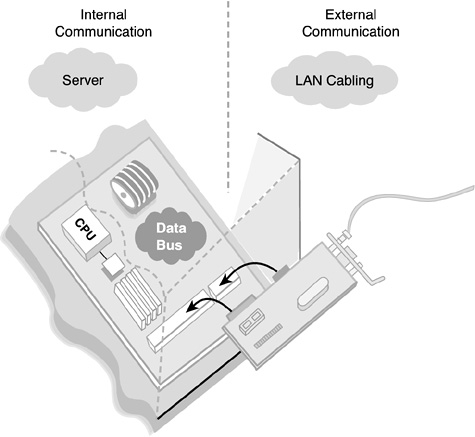
The transfer of data from the NIC to the server or workstation CPU occurs over an internal path called a data bus. The bus architecture of your network server can dramatically affect performance. To optimize and troubleshoot the server architecture, you should understand the strengths and weaknesses of the following bus types (follow along in Figure 16.2):
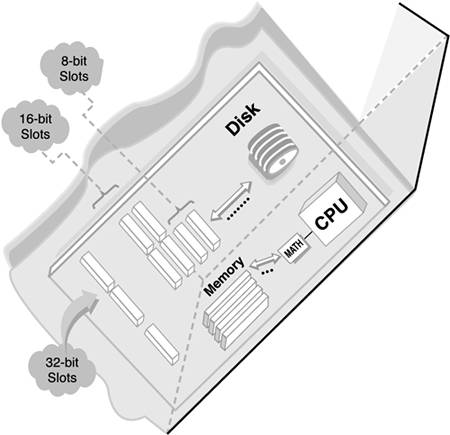
![]() Industry Standard Architecture (ISA)—ISA was the first and is the most basic bus architecture. ISA operates over an 8-bit data bus, and is not appropriate for today’s server applications.
Industry Standard Architecture (ISA)—ISA was the first and is the most basic bus architecture. ISA operates over an 8-bit data bus, and is not appropriate for today’s server applications.
![]() MicroChannel Architecture (MCA)—IBM introduced MicroChannel Architecture with its PS/2 product line. MCA is an improvement over ISA because it is much faster (32 Mb/s), more easily configurable, and provides better throughput. In addition, MCA uses a software configuration program to automate NIC and adapter settings. Note: The 32-bit MCA slots support only MCA cards.
MicroChannel Architecture (MCA)—IBM introduced MicroChannel Architecture with its PS/2 product line. MCA is an improvement over ISA because it is much faster (32 Mb/s), more easily configurable, and provides better throughput. In addition, MCA uses a software configuration program to automate NIC and adapter settings. Note: The 32-bit MCA slots support only MCA cards.
![]() Extended Industry Standard Architecture (EISA)—EISA cards use a 32-bit bus design and fit into a multilevel slot that appears very similar to a 16-bit ISA slot. EISA slots can accommodate 16-bit and 8-bit ISA cards. This flexibility enables manufacturers to create faster EISA adapters for computers with single 8-bit, dual 16-bit, and tri-level 32-bit slots.
Extended Industry Standard Architecture (EISA)—EISA cards use a 32-bit bus design and fit into a multilevel slot that appears very similar to a 16-bit ISA slot. EISA slots can accommodate 16-bit and 8-bit ISA cards. This flexibility enables manufacturers to create faster EISA adapters for computers with single 8-bit, dual 16-bit, and tri-level 32-bit slots.
![]() Peripheral Component Interconnect (PCI)—PCI is a 32-bit to 64-bit bus that runs at 33MHz and above. PCI has a maximum data transfer rate of 528 Mb/s. In addition, PCI includes a feature called low-access latency, which means that there is very little time between the time the CPU turns control over to the bus and the time the bus takes action. Not all PCI boards are the same, so it’s important to check the specifications before using one on your server.
Peripheral Component Interconnect (PCI)—PCI is a 32-bit to 64-bit bus that runs at 33MHz and above. PCI has a maximum data transfer rate of 528 Mb/s. In addition, PCI includes a feature called low-access latency, which means that there is very little time between the time the CPU turns control over to the bus and the time the bus takes action. Not all PCI boards are the same, so it’s important to check the specifications before using one on your server.
Refer to Table 16.1 for a quick comparison of the top five server bus types.

TIP
Consider using bus mastering PCI NICs and hard drive controllers in your server so that incoming communications can be handled by the NIC and hard drive directly without interrupting the central CPU. Also consider using Hot Plug/Hot Swap devices so that you can swap out expansion units without bringing the server down.
Through your trials and tribulations as a NetWare troubleshooter, you’ll find many problems begin and end with the server hard drive. Servers usually have a large amount of disk storage to meet the storage needs of multiple users. For example, an iFolder server allocates 200MB per user by default.
The type of server disk channel you use has a direct effect on the fitness of your server. You should be familiar with the following:
![]() Fibre Channel—Fibre Channel is an emerging standard that promises the capability to connect storage systems up to 10 kilometers (6 miles) apart. Fibre Channel is compatible with SCSI and targeted to high-performance storage systems.
Fibre Channel—Fibre Channel is an emerging standard that promises the capability to connect storage systems up to 10 kilometers (6 miles) apart. Fibre Channel is compatible with SCSI and targeted to high-performance storage systems.
![]() Small Computer System Interface (SCSI)—In a multidrive environment, Fibre Channel and SCSI drives are more scalable. IDE/ATA channels are limited to 2 devices, but SCSI can handle 8 devices with Narrow SCSI, 16 devices with Wide SCSI, or 32 devices with Very Wide SCSI. SCSI drives also support command queuing (up to 256 commands per device); IDE/ATA drives do not. These performance gains are realized in a multidrive server environment.
Small Computer System Interface (SCSI)—In a multidrive environment, Fibre Channel and SCSI drives are more scalable. IDE/ATA channels are limited to 2 devices, but SCSI can handle 8 devices with Narrow SCSI, 16 devices with Wide SCSI, or 32 devices with Very Wide SCSI. SCSI drives also support command queuing (up to 256 commands per device); IDE/ATA drives do not. These performance gains are realized in a multidrive server environment.
![]() Integrated Drive Electronics/Advanced Technology Attachment (IDE/ATA)—You usually find Fibre Channel or SCSI disk channels in a server and IDE/ATA in a desktop. On single-drive systems, IDE/ATA is less expensive and performs well.
Integrated Drive Electronics/Advanced Technology Attachment (IDE/ATA)—You usually find Fibre Channel or SCSI disk channels in a server and IDE/ATA in a desktop. On single-drive systems, IDE/ATA is less expensive and performs well.
After data bus and storage architecture, the server CPU can have a dramatic effect on server performance. Check it out in Figure 16.2. In many cases, the processing demands placed on the server can be great. As a result, it’s often necessary to have multiple processors running on a server to meet the demand. Refer to the “Using High-Performance NetWare” section at the end of this lesson.
NetWare 6 supports up to 32 processors, with a minimum requirement of a Pentium II or AMD K7 processor. The Xeon, Pentium 4, and Pentium III processors are commonly used in servers.
During installation, NetWare detects multiple processors by reading the multiprocessor (MP) configuration table in BIOS and then determining which of the available NetWare Platform Support Modules (PSMs) matches the MP hardware platform. A PSM is a loadable hardware abstraction layer for processor and interrupt support. Each PSM is specific to a particular hardware platform.
You can either load a PSM (for multiprocessor support) or run NetWare on processor 0 only. The installation program will modify the STARTUP.NCF file to load the PSM whenever the server is started.
Finally, server memory plays a big role in network performance and fitness. In fact, the server’s overall performance is directly related to the amount of available memory. Each application or service running on the server uses memory from the available memory pool. When the amount of available memory becomes low or runs out, the server is negatively affected.
NetWare 6 requires a minimum of 256MB of RAM (512MB recommended) and can address up to 64GB. Up to 4GB can be allocated to cache memory. More than 4GB is allocated to virtual memory. To maintain performance, memory should be added for each additional service or application running on the server.
That completes our quick review of server hardware architecture. As your company’s server needs change and grow, the server must scale to meet the demand. You should be able to add the following to the server at anytime: processors, memory, disk storage, and clustering (refer to Chapter 14, “NetWare 6 High Availability with Novell Cluster Services,” earlier in this book).
In addition, servers typically have redundant, hot-swappable hardware for the following: hard drives, power supplies, processors, cooling fans, network boards, uninterruptible power supplies and battery backup, and memory. Hot Swappable means that the key components can be replaced without interrupting server operations. As I’m sure you can imagine, this flexibility is critical in today’s AAA (Anytime, Anywhere, Always Up) IT environment.
Now let’s continue our server fitness lesson with the “better” half: server operating system architecture.
A NetWare server is a computer that is running any version of the NetWare operating system. Typically, NetWare 6 runs on a computer containing an Intel Pentium processor. Interestingly, NetWare 6 is loaded on a server by executing a file called SERVER.EXE from the server’s DOS partition. This loads the core OS shown in Figure 16.3.

It all begins at the colon prompt. The colon (:) prompt is your ticket to the raw server console. The colon prompt accepts two kinds of NetWare 6 server commands: console commands and NLM load commands. NetWare 6 includes numerous console commands for various server management and maintenance tasks (including NDS management, time synchronization, bindery services, sending messages, activating NLMs, server protection, and network optimization). In addition, there are four basic types of NLMs: disk drivers, LAN drivers, name space modules, and NLM utilities (including management utilities and server enhancements).
The NetWare operating system is modular. It’s composed of many components that work together to provide network services. In this section, we’ll discuss the following four components:
![]() NetWare kernel
NetWare kernel
![]() Server console
Server console
![]() Console commands
Console commands
![]() NetWare Loadable Modules
NetWare Loadable Modules
In an operating system, a kernel is typically defined as the basis or core of the operating system. In other words, the portion of the operating system that’s responsible for essential tasks, such as allocating system resources; maintaining the date/time; managing memory, files, and peripheral devices; and launching applications.
As you can see in Figure 16.4, the NetWare kernel provides a central platform for running server applications, such as NetWare Loadable Modules (NLMs). Additional functions that are provided by the NetWare kernel include multiprocessor support, virtual memory, memory protection, load balancing, scheduling, and preemption.

The server console is the tool that interfaces with the NetWare kernel. It provides a command prompt where console commands can be executed and NLMs can be loaded and unloaded. NetWare 6 also provides a Java-based GUI interface, called the NetWare GUI, which is loaded by default. You can toggle between the various console screens, including the command prompt and the NetWare GUI, by pressing Alt+Esc. The following are tasks that you can perform at the NetWare server console: shut down and restart the server, edit configuration and batch files, set server configuration parameters, add and remove a name space from server volumes, load and unload programs, view network traffic, and send messages.
NetWare 6 supports a variety of hot key sequences that enable you to navigate and troubleshoot the server console, such as the following:
![]() Ctrl+Esc—This key sequence displays the Current Screens menu, which lists active NLM screens. To switch to a particular screen, type the corresponding menu number and press the Enter key.
Ctrl+Esc—This key sequence displays the Current Screens menu, which lists active NLM screens. To switch to a particular screen, type the corresponding menu number and press the Enter key.
![]() Alt+Esc—This key sequence enables you to quickly toggle between active NLM screens.
Alt+Esc—This key sequence enables you to quickly toggle between active NLM screens.
![]() Ctrl+Alt+Esc—This key sequence displays the Hung Console screen, which enables you to safely bring down the server or cancel a volume mount.
Ctrl+Alt+Esc—This key sequence displays the Hung Console screen, which enables you to safely bring down the server or cancel a volume mount.
Console commands are command-line utilities that are built into the NetWare 6 kernel and are executed at the server console. They enable you to perform a variety of server management maintenance tasks, including NDS management, time synchronization, bindery services, NLM activation, server protection, network optimization, and sending messages.
TIP
Console commands are internal operating system tools that are similar to DOS’s internal commands. They’re built into SERVER.EXE just like CD or CLS is built into COMMAND.COM.
NetWare Loadable Modules are modular software programs that provide additional functionality and services to the NetWare server (refer to Figure 16.4). NLMs have the following advantages: They can free up server RAM by enabling network administrators to remove unneeded modules; they can typically be loaded and unloaded without bringing down the server; and they provide an easy method for third-party developers to write their own modules.
In summary, the NetWare 6 kernel offers the following features:
![]() Multiprocessor support—Like previous versions, NetWare 6 supports multiple parallel processors in the server. Unlike previous versions, however, NetWare 6 supports single and multiple processors through the same kernel. The cool thing is that NetWare automatically detects the number of processors available in the server (the maximum is 32). In addition, the kernel is smart enough to detect and distribute processing load across multiple processors when multiple processors are available—this is known as load balancing. With the NetWare 6 multiprocessor kernel (MPK), the server can accomplish more tasks in less time.
Multiprocessor support—Like previous versions, NetWare 6 supports multiple parallel processors in the server. Unlike previous versions, however, NetWare 6 supports single and multiple processors through the same kernel. The cool thing is that NetWare automatically detects the number of processors available in the server (the maximum is 32). In addition, the kernel is smart enough to detect and distribute processing load across multiple processors when multiple processors are available—this is known as load balancing. With the NetWare 6 multiprocessor kernel (MPK), the server can accomplish more tasks in less time.
![]() Memory protection—NetWare 6 segments core OS memory into protected areas of server RAM. This enables you to test ill-behaved applications at the server without risking a kernel crash. In addition, NetWare 6 supports memory protection for Java applications.
Memory protection—NetWare 6 segments core OS memory into protected areas of server RAM. This enables you to test ill-behaved applications at the server without risking a kernel crash. In addition, NetWare 6 supports memory protection for Java applications.
![]() Virtual memory—NetWare 6 further enhances server performance by offering as much memory as you need whenever you need it. This is accomplished by using a new feature called virtual memory. Virtual memory enables NetWare 6 to store information temporarily on a hard drive when there isn’t enough physical RAM to complete a server operation. Although this slows down performance a little, it does avoid that age-old bugaboo—insufficient memory—or even worse—abend. NetWare 6 uses an intelligent least recently used (LRU) algorithm to determine which operations are moved into virtual RAM.
Virtual memory—NetWare 6 further enhances server performance by offering as much memory as you need whenever you need it. This is accomplished by using a new feature called virtual memory. Virtual memory enables NetWare 6 to store information temporarily on a hard drive when there isn’t enough physical RAM to complete a server operation. Although this slows down performance a little, it does avoid that age-old bugaboo—insufficient memory—or even worse—abend. NetWare 6 uses an intelligent least recently used (LRU) algorithm to determine which operations are moved into virtual RAM.
![]() Preemptive scheduling—The NetWare kernel enables you to manage the amount of time each application uses the server processor(s). This gives you total control over high-priority and mission-critical operations. Furthermore, NetWare 6 uses preemption to take control of processors instantly—regardless of the state of the currently running application. Ultimately, this keeps runaway processes under control.
Preemptive scheduling—The NetWare kernel enables you to manage the amount of time each application uses the server processor(s). This gives you total control over high-priority and mission-critical operations. Furthermore, NetWare 6 uses preemption to take control of processors instantly—regardless of the state of the currently running application. Ultimately, this keeps runaway processes under control.
To troubleshoot the NetWare server operating system, it’s helpful to understand, in detail, what happens when you turn on the server machine.
As you learned earlier, the whole magical dance is launched when SERVER.EXE loads from C:NWSERVER on the DOS partition. SERVER.EXE contains files, such as LOADER.EXE, SERVER.NLM, and other NLMs (that are bound in), including PMLODR.NLM, PVER500.NLM, and XLDR.NLM.
The first file loaded from SERVER.EXE is LOADER.EXE, which sets up the initial hardware interfaces (screen, keyboard, memory management, and interrupt handling).
Second, SERVER.NLM is loaded, and it launches most of the server routines. Third, the server has a load template that defines what NLMs will be loaded at each stage of the boot process. Finally, these modules are loaded in the following order:
![]() LOADSTAGE 0
LOADSTAGE 0
![]() STARTUP.NCF
STARTUP.NCF
![]() LOADSTAGE 1
LOADSTAGE 1
![]() LOADSTAGE 2
LOADSTAGE 2
![]() LOADSTAGE 3
LOADSTAGE 3
![]() LOADSTAGE 4
LOADSTAGE 4
![]() AUTOEXEC.NCF
AUTOEXEC.NCF
![]() LOADSTAGE 5
LOADSTAGE 5
TIP
You can view the modules that are loaded in each stage by entering LIST STAGE at the server console prompt. This can be helpful when troubleshooting problems that occur when the server starts.
After the server has booted, NLMs can be viewed with the MODULES or M command. You’ll notice that they’re color coded, which is useful when troubleshooting. Check them out in Table 16.2.

That completes our lesson in server hardware and software. Now, let’s complete this fitness overview with some high-performance features, namely multitasking, multithreading, and multiprocessing.
Our final stop on this whirlwind tour of the NetWare server architecture is the engine itself. Novell has made some dramatic improvements to the core OS in NetWare 6. Most of these efforts focus on increasing the server’s processing performance and reliability.
Like previous versions, NetWare 6 supports multiple parallel processors in the server. Unlike previous versions, however, NetWare 6’s high-performance capability is storage-to-wire. This means that all NetWare 6 services are multiprocessor-enabled—from disk to protocol. This contrasts with NetWare 5 in which only the core OS was tuned for high performance—leaving out the TCP/IP stack, Novell Storage Services (NSS), NetWare Core Protocol (NCP), Web server, and the eDirectory.
To tune your NetWare 6 high-performance engine, you must become a pro in these three server disciplines:
![]() Multitasking—Each processor in the NetWare 6 server can run two or more programs at the same time.
Multitasking—Each processor in the NetWare 6 server can run two or more programs at the same time.
![]() Multithreading—Enables the multiple execution of software threads to take place concurrently within the same program.
Multithreading—Enables the multiple execution of software threads to take place concurrently within the same program.
![]() Multiprocessing—Enables you to distribute processor load across multiple server processors simultaneously.
Multiprocessing—Enables you to distribute processor load across multiple server processors simultaneously.
Let’s take a closer look.
NetWare 6 is a multitasking operating system, which means that each single-processor NetWare 6 server is capable of running two or more programs at the same time. As a result, NetWare 6 can constantly service client needs and operate at peak utilization.
For example, while one program is waiting for input, instructions can be executed in another program running on the same server.
The key thing to remember about NetWare 6 multitasking is that it’s based on a single-processor model. That means you can multitask the server’s multitasking by adding multiple processors. We’ll explore this feature in more detail a little bit later.
Multithreading is basically multitasking within a single program. Because NetWare 6 supports multithreading, it can concurrently execute multiple software threads within the same program. Like multitasking, NetWare 6 multithreading is also based on a single processor model and benefits dramatically from two or more processors.
To fully grasp the benefit of NetWare 6 multithreading, you must understand the subtle differences between these three operating-system terms:
![]() Software thread—Each software thread is composed of two parts: the first piece defines what the computer must do, and the second part performs the action according to the definition. Each NetWare server application allocates threads just like it allocates memory. When the application is done processing the thread, the thread is returned to the system kernel to be called the next time it’s needed. Because the software thread is allocated CPU time, a processor can execute only one thread at a time.
Software thread—Each software thread is composed of two parts: the first piece defines what the computer must do, and the second part performs the action according to the definition. Each NetWare server application allocates threads just like it allocates memory. When the application is done processing the thread, the thread is returned to the system kernel to be called the next time it’s needed. Because the software thread is allocated CPU time, a processor can execute only one thread at a time.
![]() Simultaneous—With respect to software threads, simultaneous means that one processor can run multiple threads at the same time. However, this isn’t possible with a single-processor server. The only way to achieve true simultaneous threading is to use a multiprocessor server.
Simultaneous—With respect to software threads, simultaneous means that one processor can run multiple threads at the same time. However, this isn’t possible with a single-processor server. The only way to achieve true simultaneous threading is to use a multiprocessor server.
![]() Concurrency—With respect to software threads, concurrency is the perception that a single processor is executing threads simultaneously. In reality, multithreading relies on the fact that fast processors can switch between multiple threads so efficiently that they appear to be running in parallel. In the NetWare 6 multithreading concurrency model, a single processor can switch from one thread to another at any point and can place the resting threads in a state of suspension.
Concurrency—With respect to software threads, concurrency is the perception that a single processor is executing threads simultaneously. In reality, multithreading relies on the fact that fast processors can switch between multiple threads so efficiently that they appear to be running in parallel. In the NetWare 6 multithreading concurrency model, a single processor can switch from one thread to another at any point and can place the resting threads in a state of suspension.
Although multitasking and multithreading help supercharge your NetWare 6 engine, they’re limited to the single-processor model. Imagine how powerful they can be when you add one or more additional processors.
“Perception is reality!”
In NetWare 6, you can transform the simultaneous perception of multithreading concurrency into a reality by adding two or more processors to the server. That means NetWare 6 can extend beyond the illusion of simultaneous processing by executing multiple threads at the same time. All of this magic is made possible using a sophisticated NetWare service called the Scheduler.
The Scheduler is the brains behind NetWare 6 multiprocessing. It determines how to distribute software threads based on a number of different criteria:
![]() Single-processor thread—If the programmer thread is not multiprocessor-safe, the Scheduler funnels the program and its threads to a single processor.
Single-processor thread—If the programmer thread is not multiprocessor-safe, the Scheduler funnels the program and its threads to a single processor.
![]() New multiprocessor thread—If the program is multiprocessor-safe but it has never been run on this server before, the Scheduler funnels it to all available processors simultaneously.
New multiprocessor thread—If the program is multiprocessor-safe but it has never been run on this server before, the Scheduler funnels it to all available processors simultaneously.
![]() Returning multiprocessor thread—If the program or thread is multiprocessor-safe and has run on this server before, the Scheduler funnels the program and its threads to the processors where they last ran. This allows the processors to use their cache to execute threads faster and avoid bottlenecks.
Returning multiprocessor thread—If the program or thread is multiprocessor-safe and has run on this server before, the Scheduler funnels the program and its threads to the processors where they last ran. This allows the processors to use their cache to execute threads faster and avoid bottlenecks.
Because NetWare 6 distributes multiprocessing threads according to a cache model, it can create a situation in which some processors are overused and others are underused. To solve this problem, the NetWare Scheduler periodically calculates use of each processor and determines whether it is overused or underused. In the case of an overused processor, the Scheduler moves threads to an underused one to balance processor workloads. However, moving data from one processor cache to another causes another problem: cache contention.
Cache contention slows the processor because it is forced to send data back and forth as it tries to accomplish load balancing. To solve this problem, NetWare 6 forces each thread to run on the same processor each time it is run. To make matters even better, NetWare 6 creates a run queue (a list of threads to be run) for each installed processor. This enables each processor to track the threads it will run without competing with all other processors for access to one global list.
REAL WORLD
Although cache contention is generally a bad thing, there are times when it is preferred:
![]() If a thread is not multiprocessor-enabled, the Scheduler must move it from one processor to another and suffer the corresponding cache contention.
If a thread is not multiprocessor-enabled, the Scheduler must move it from one processor to another and suffer the corresponding cache contention.
![]() In some cases, cache contention can facilitate load balancing because the gain in allocation of an underused processor is much more powerful than the loss incurred by cache-contention shuffling.
In some cases, cache contention can facilitate load balancing because the gain in allocation of an underused processor is much more powerful than the loss incurred by cache-contention shuffling.
To take advantage of NetWare 6 multiprocessing, the processors in your NetWare 6 server must meet the following minimum requirements:
![]() All processors must be functionally identical. That means they should be of the same family and model. However, server processors can use different steppings (similar to revision numbers). For example, you can’t mix a Pentium IV with a Pentium V, but you can mix a Pentium V stepping 3 with a Pentium V stepping 4.
All processors must be functionally identical. That means they should be of the same family and model. However, server processors can use different steppings (similar to revision numbers). For example, you can’t mix a Pentium IV with a Pentium V, but you can mix a Pentium V stepping 3 with a Pentium V stepping 4.
![]() All processors must operate at the same speed.
All processors must operate at the same speed.
![]() All processors must be capable of communicating with each other.
All processors must be capable of communicating with each other.
![]() All processors must share the same I/O subsystem.
All processors must share the same I/O subsystem.
![]() All processors must share the same memory space.
All processors must share the same memory space.
Congratulations, you’ve just helped build the world’s fastest, most reliable NetWare server. Of course, it cost a mint. But nothing is too good for your users.
In this introductory lesson, we explored the server platform (hardware) and the software that runs on top of it (NetWare 6). Now, it’s time to rejoin our fitness discussion with a comprehensive lesson in server troubleshooting tools, performance problems, and crashes.
Sounds dangerous.
Test Objectives Covered:
![]() Troubleshoot and Resolve NetWare Server Issues
Troubleshoot and Resolve NetWare Server Issues
![]() Troubleshoot and Resolve Critical Server Abends
Troubleshoot and Resolve Critical Server Abends
![]() Create a Disaster Recovery Plan
Create a Disaster Recovery Plan
![]() Troubleshoot and Resolve Server Communication Issues
Troubleshoot and Resolve Server Communication Issues
![]() Troubleshoot Network Problems
Troubleshoot Network Problems
Problem prevention is a great thing.
I can’t think of a better time to deal with network problems than before they occur. It’s interesting—as a NetWare doctor, your life is a paradox. You’re needed only when the network is sick, and yet your primary goal is to encourage network health. I guess success is achieved only when you become obsolete. Don’t worry, though—that isn’t going to happen any time soon.
As a matter of fact, we’re going to spend this final server troubleshooting lesson training you to deal with every conceivable server problem—especially the ones dealing with server performance, crashes, memory, processors, and so on. Here’s a preview:
![]() “Troubleshooting Tools for the Server”—Before we tackle server troubleshooting, we’ll fill our medical bag with some additional server tools, namely NetWare Cool Solutions, AppNotes, Novell technical support tools, Alexander SPK, and Storage Manager for Novell NetWare.
“Troubleshooting Tools for the Server”—Before we tackle server troubleshooting, we’ll fill our medical bag with some additional server tools, namely NetWare Cool Solutions, AppNotes, Novell technical support tools, Alexander SPK, and Storage Manager for Novell NetWare.
![]() “Maintaining Current Software”—Real server troubleshooting begins by maintaining fresh software. If you keep the server updated with patches and new drivers, the chances of a crash diminish. Furthermore, new software adds greater functionality and increases server performance.
“Maintaining Current Software”—Real server troubleshooting begins by maintaining fresh software. If you keep the server updated with patches and new drivers, the chances of a crash diminish. Furthermore, new software adds greater functionality and increases server performance.
![]() “Troubleshooting Server Performance”—At the heart of server troubleshooting is a four-pointed star of problematic components, including installation, storage, memory, and processors. In the server performance section, we’ll discuss several troubleshooting matrices for dealing with these tricky hardware/software components.
“Troubleshooting Server Performance”—At the heart of server troubleshooting is a four-pointed star of problematic components, including installation, storage, memory, and processors. In the server performance section, we’ll discuss several troubleshooting matrices for dealing with these tricky hardware/software components.
![]() “Troubleshooting Server Crashes”—If none of these measures work, you’ll undoubtedly experience a server crash—they’re unavoidable. The best things you can do in the event of a server crash are to recognize the warning signs and take immediate action. Taking these steps is usually adequate to restore server health. Sometimes, however, they’re not enough. In those cases, you’ll need an established disaster recovery plan to get your server back on its feet.
“Troubleshooting Server Crashes”—If none of these measures work, you’ll undoubtedly experience a server crash—they’re unavoidable. The best things you can do in the event of a server crash are to recognize the warning signs and take immediate action. Taking these steps is usually adequate to restore server health. Sometimes, however, they’re not enough. In those cases, you’ll need an established disaster recovery plan to get your server back on its feet.
![]() “Troubleshooting Communication Bottlenecks”—Network bottlenecks slow us down. Most servers experience communication bottlenecks in four areas: disk I/O, network I/O, CPU, and bus I/O. These bottlenecks make server troubleshooting even more of a challenge than it already is. Fortunately, I have some time-proven solutions to help you open these bottlenecks and improve communication performance.
“Troubleshooting Communication Bottlenecks”—Network bottlenecks slow us down. Most servers experience communication bottlenecks in four areas: disk I/O, network I/O, CPU, and bus I/O. These bottlenecks make server troubleshooting even more of a challenge than it already is. Fortunately, I have some time-proven solutions to help you open these bottlenecks and improve communication performance.
That’s all there is to it. Let’s get started with server troubleshooting tools.
In the previous chapter, Chapter 15, you learned that your network is alive. Shocking, huh? You also discovered that as the NetWare doctor, you must rely on a medical bag full of tools to keep it that way.
Also in Chapter 15, we discussed NetWare Cool Solutions, a hip Web site dedicated to helping you get the most out of Novell products. Cool Solutions is a great place to start your server troubleshooting duties. There you’ll find tips, articles, Q&As, and free tools to fill up your medical tool bag. In addition, Cool Solutions includes articles posted by readers who want to share their learning experiences and real-life case studies.
Next, you should explore Novell’s monthly AppNotes. The material in AppNotes is based on actual field experience and technical research performed by Novell personnel, covering topics in these main areas: network design and optimization strategies, network management tactics, Novell product internals and theory of operations, Novell product implementation guidelines, integration solutions for third-party products, and network applications development and tools.
In addition, many support tools available from third-party vendors can assist with troubleshooting. First, check out Alexander SPK NetWare at www.Alexander.com (System Protection Kit). This kit provides tools to handle server problems and help prevent or identify problems before they occur. When an abend occurs, the abend call is intercepted by EDNA.NLM (Emergency Diagnostics for NetWare Administrator), part of the Alexander SPK, and takes control of the system. EDNA tries to prevent a crash by suspending the errant NLM. If it’s successful, a hard crash is prevented, a log file is generated, and administrators can be notified through SNMP traps. The SPK Crash Report immediately pinpoints the module that caused the crash. Alexander SPK v4.1 for NetWare runs on NetWare 6–3x.
Another great third-party server troubleshooting tool is Storage Manager for Novell NetWare at www.PortLockSoftware.com. This is server image and recovery software that supports NetWare 6 and NSS. Storage Manager minimizes the management, setup, installation, and reconfiguration time for NetWare servers. It offers data and disaster recovery. And don’t forget Dave’s Novell Shareware. This is a free service for NetWare enthusiasts and authors of NetWare-based software, shareware, and freeware. Check it out at www.novellshareware.com.
Finally, Novell itself provides a plethora of support tools for preventing and troubleshooting server problems. These support tools can be downloaded free of charge. The following are a few of the many tools available:
![]() Enhanced ToolBox Utility—TOOLBOX.NLM lets various utility functions be executed on the server console or via NCF files without involving any clients. You can download this tool at www.novell.com/coolsolutions/tools/1490.html.
Enhanced ToolBox Utility—TOOLBOX.NLM lets various utility functions be executed on the server console or via NCF files without involving any clients. You can download this tool at www.novell.com/coolsolutions/tools/1490.html.
![]() Server Configuration Information Tool—The Server Configuration Information program creates CONFIG.TXT that contains server configuration information. CONFIG.NLM works on all versions of NetWare; however, NetWare Remote Manager provides the same functionality in NetWare 5.x and 6. You can download this tool at www.novell.com/coolsolutions/tools/1506.html.
Server Configuration Information Tool—The Server Configuration Information program creates CONFIG.TXT that contains server configuration information. CONFIG.NLM works on all versions of NetWare; however, NetWare Remote Manager provides the same functionality in NetWare 5.x and 6. You can download this tool at www.novell.com/coolsolutions/tools/1506.html.
![]() NetWare Config Reader—The Config Reader (2.67) is a Windows 95/98/NT client utility that analyzes the CONFIG.TXT file produced by CONFIG.NLM. You can download this tool from www.novell.com/coolsolutions/tools/1500.html.
NetWare Config Reader—The Config Reader (2.67) is a Windows 95/98/NT client utility that analyzes the CONFIG.TXT file produced by CONFIG.NLM. You can download this tool from www.novell.com/coolsolutions/tools/1500.html.
![]() Other tools—There are many tools available for download that address a wide range of administrative needs. Support tools from Novell Technical Support are available at support.novell.com/tools-files.html.
Other tools—There are many tools available for download that address a wide range of administrative needs. Support tools from Novell Technical Support are available at support.novell.com/tools-files.html.
This completes our first section of server troubleshooting. Now let’s dive into the real nuts-and-bolts of problem prevention in the server environment—starting with patches.
If a server seems to be experiencing problems, one of the first troubleshooting steps you should perform is to determine whether the server is running the latest version of operating system patches, device drivers, and NLMs.
Novell provides three types of operating system patches for known server problems:
![]() Dynamic—Dynamic patches are implemented as .NLM files that can be loaded and unloaded while the server is running. Unloading a dynamic patch restores the operating system to its original, unpatched state.
Dynamic—Dynamic patches are implemented as .NLM files that can be loaded and unloaded while the server is running. Unloading a dynamic patch restores the operating system to its original, unpatched state.
![]() Semistatic—Semistatic patches can be loaded while the server is up and running, but they cannot be unloaded without restarting the server. To remove a semistatic patch, simply restart the server without loading the patch.
Semistatic—Semistatic patches can be loaded while the server is up and running, but they cannot be unloaded without restarting the server. To remove a semistatic patch, simply restart the server without loading the patch.
![]() Static—Static patches are implemented using a DOS executable that modifies the SERVER.EXE file. After a static patch has been applied, the effects are permanent. Therefore, you should always make a backup of SERVER.EXE before applying a static patch.
Static—Static patches are implemented using a DOS executable that modifies the SERVER.EXE file. After a static patch has been applied, the effects are permanent. Therefore, you should always make a backup of SERVER.EXE before applying a static patch.
You can install patches individually or via a support pack. A support pack includes all updates to the products included in a NetWare operating system version as of a certain date. The advantage of installing a support pack, rather than individual patches, is that the updated files in a support pack have been tested both individually and as a complete suite. To install a support pack, use NWCONFIG.NLM or INSTALL.NLM.
Novell uses a specific naming convention for operating system patch files. The following are examples of operating system patch files that follow the official Novell naming convention: 600PTD.EXE (NetWare 6) and 510SP3.EXE (NetWare 5.1). The first three digits refer to the operating system version; the next two characters stand for the type of patch (for example, PT stands for passed test and SP stands for support pack); and finally, the last character is the revision number or letter.
Use the following procedure to install support packs and patches on a NetWare 6 server:
1. Back up all volumes on your server.
2. Obtain the latest service pack from the Novell Support Resource Library or the Novell Support Web site.
3. Create a temporary directory on one of the server’s volumes.
4. Expand the support pack by entering the filename at the DOS prompt. For example:
600PTD
5. Enter one of the following console commands:
NWCONFIG (NetWare 5.x or 6) or INSTALL (NetWare 4.x)
6. Select Product Options.
7. Choose Install a Product Not Listed.
8. Press F3, and then specify the complete path to the temporary directory you created in step 3.
9. Follow the instructions.
10. Restart the server.
It’s also important to ensure that your server is running the latest version of various device drivers. Device drivers are software programs that form the interface between NetWare and hardware resources, such as storage devices or network boards. Three important types of server device drivers include LAN drivers (for server NICs), disk drivers (for server storage devices), and NWPA drivers (new driver architecture for server storage devices). (Note: NetWare 6 does not support disk drivers with a .DSK filename extension found in earlier versions of NetWare.)
Finally, it’s important to ensure that your server is running the latest version of various NLMs. NLMs can typically be loaded and unloaded while the server is running without affecting the NetWare operating system. System NLMs are stored in the SYS:SYSTEM directory, by default. Other NLMs are stored elsewhere. The latest versions of these server programs are available on the Novell Support Resource Library CD-ROM and the Novell Support Web site.
At the heart of server troubleshooting is a four-pointed star of problematic components. Each of these hardware/software players plays an important role in keeping the server in peak condition. In addition, you have to understand the interrelationships between these components because many of them depend on each other.
In this server performance section, we’ll discover several troubleshooting matrices for dealing with each of the following hardware/software components:
![]() Installation
Installation
![]() Storage
Storage
![]() Memory
Memory
![]() Processor
Processor
Let’s troubleshoot!
If the server isn’t communicating properly after installation, it’s usually an indication that the network was installed incorrectly or incompletely. The following are a few items to check:
![]() Check all network boards for conflicting address and I/O settings.
Check all network boards for conflicting address and I/O settings.
![]() Verify that the network board driver is loaded and bound to the correct protocol.
Verify that the network board driver is loaded and bound to the correct protocol.
![]() Make sure that all network boards are seated properly and are initializing.
Make sure that all network boards are seated properly and are initializing.
![]() Verify that all cables are fastened securely to all network boards and network connectors.
Verify that all cables are fastened securely to all network boards and network connectors.
![]() Verify the correct IP address and subnet mask are being used.
Verify the correct IP address and subnet mask are being used.
![]() Test IP connectivity by pinging the server from a workstation and ping the workstation from the server.
Test IP connectivity by pinging the server from a workstation and ping the workstation from the server.
![]() If the workstation can ping the server, but the server cannot ping the workstation, check the default route on the server.
If the workstation can ping the server, but the server cannot ping the workstation, check the default route on the server.
![]() Verify that the server hasn’t run out of packet receive buffers.
Verify that the server hasn’t run out of packet receive buffers.
The server hard drive is the center of your users’ universe. This is where all of their valuable data and applications reside. Take great care in protecting this critical company asset. Check out Table 16.3 for some time-proven storage troubleshooting solutions.

Server memory is the cornerstone of NetWare performance. So, it stands to reason that this would be an ideal place to spend some quality preventative maintenance time. First, make sure that the server is recognizing all the installed hardware memory chips. Second, track how applications and NLMs are using server memory. Memory leaks can slowly degrade server performance over time. Finally, develop an action plan to respond when the server ultimately runs out of memory.
Look over Table 16.4 for a list of server memory problems and Novell technical support solutions. This is good stuff.


Some of the most troublesome gremlins in the server garden are applications that monopolize the server CPU processing time. Slow server processing speed can indicate a poorly designed application or a conflict between applications.
A program or NLM that monopolizes the server CPU is sometimes referred to as a CPU hog. To solve this problem, locate the offending application using Remote Manager. Then try some of the following solutions:
![]() Unload the module
Unload the module
![]() Replace the module with a newer version that has been fixed
Replace the module with a newer version that has been fixed
![]() Use NetWare Remote Manager to debug and troubleshoot the problem down to the disassembled code level
Use NetWare Remote Manager to debug and troubleshoot the problem down to the disassembled code level
![]() Unload and reload the module and troubleshoot if the problem reoccurs
Unload and reload the module and troubleshoot if the problem reoccurs
![]() Contact the application vendor for support
Contact the application vendor for support
That’s it. You’re done with server performance. Congratulations, you have kept the server running in peak condition. But what do you do if the server isn’t running at all? Ouch. Let’s see.
A server crash occurs when the NetWare operating system or server hardware unexpectedly stops working. The following are the two main types of server crashes:
![]() Server abends—Abend stands for ABnormal END. A server abend occurs when internal server activity stops abruptly. It’s typically caused by a server process or condition that threatens the integrity of internal data.
Server abends—Abend stands for ABnormal END. A server abend occurs when internal server activity stops abruptly. It’s typically caused by a server process or condition that threatens the integrity of internal data.
![]() Server lockups—A server lockup occurs when internal processing ends for no apparent reason. Lockups differ from abends in that all input/output (I/O) is frozen and no error message appears. Server lockups can be caused by a variety of problems, such as a hardware malfunction or an NLM thread that dominates the CPU and refuses to relinquish control.
Server lockups—A server lockup occurs when internal processing ends for no apparent reason. Lockups differ from abends in that all input/output (I/O) is frozen and no error message appears. Server lockups can be caused by a variety of problems, such as a hardware malfunction or an NLM thread that dominates the CPU and refuses to relinquish control.
In this section, we’ll explore the architecture of server crashes and learn how to troubleshoot server abends and lockups.
The NetWare operating system continually monitors the status of various server activities to ensure proper operation. If NetWare detects a condition that threatens the integrity of its internal data, it abruptly halts the active process and displays an abend message on the server console screen.
Abends can be detected by the internal CPU or by NetWare itself. The following are three types of NetWare abends:
![]() Interrupt—When the server CPU detects an error, the processor can interrupt program execution by issuing an interrupt or exception. An external device that needs attention generates an interrupt.
Interrupt—When the server CPU detects an error, the processor can interrupt program execution by issuing an interrupt or exception. An external device that needs attention generates an interrupt.
![]() Exception—The processor responding to a condition it detected while executing an instruction causes an exception. Exceptions are classified as faults, traps, or aborts. The most common type of NetWare exception is the non-maskable interrupt (NMI).
Exception—The processor responding to a condition it detected while executing an instruction causes an exception. Exceptions are classified as faults, traps, or aborts. The most common type of NetWare exception is the non-maskable interrupt (NMI).
![]() Consistency check—Consistency checks continually validate critical disk, memory, and communications processes. If a consistency check fails, it indicates a serious error and some degree of memory corruption. A consistency check error can be caused by a corrupted operating system file, outdated drivers or NLMs, bad packets from a client, or an internal hardware failure.
Consistency check—Consistency checks continually validate critical disk, memory, and communications processes. If a consistency check fails, it indicates a serious error and some degree of memory corruption. A consistency check error can be caused by a corrupted operating system file, outdated drivers or NLMs, bad packets from a client, or an internal hardware failure.
When a NetWare 6 server experiences an abend, the abend messages and additional information are written to the ABEND.LOG file. Depending upon several SET parameters, the server might immediately restart or restart after a preset amount of time has passed. By default, NetWare determines the source of the abend, suspends the process, restores the process to a safe state, or brings the server down.
Table 16.5 describes abend-related SET parameters in NetWare 6.

Refer to the sample NetWare abend message in Figure 16.5 while reviewing the following descriptions:
![]() Line 1: Date and time—Indicates the date and time at which the system halted.
Line 1: Date and time—Indicates the date and time at which the system halted.
![]() Line 2: Abend message string—Includes the text of the abend message. This information can help you determine whether the CPU or the operating system detected the error. In this case (Figure 16.5), it’s a CPU error.
Line 2: Abend message string—Includes the text of the abend message. This information can help you determine whether the CPU or the operating system detected the error. In this case (Figure 16.5), it’s a CPU error.
![]() Line 3: Operating system version—Identifies the version of NetWare that was running on the server at the time of the abend.
Line 3: Operating system version—Identifies the version of NetWare that was running on the server at the time of the abend.
![]() Line 4: Running process—Identifies which process was running at the time of the abend. This process might or might not have caused the abend.
Line 4: Running process—Identifies which process was running at the time of the abend. This process might or might not have caused the abend.
![]() Line 5: Stack—The hexadecimal bytes displayed on the abend screen represent part of the CPU’s stack from the current process. All three lines of the stack dump might be useful to Novell technical support in diagnosing the cause of the problem.
Line 5: Stack—The hexadecimal bytes displayed on the abend screen represent part of the CPU’s stack from the current process. All three lines of the stack dump might be useful to Novell technical support in diagnosing the cause of the problem.
![]() Line 6: Executing NLM—The name of the NLM that was being executed when the error occurred.
Line 6: Executing NLM—The name of the NLM that was being executed when the error occurred.
![]() Line 7: Server action—Displays the action that will be taken by the server upon error detection.
Line 7: Server action—Displays the action that will be taken by the server upon error detection.
![]() Line 8: OS version and state—Displays the operating system version and the server’s current operating state.
Line 8: OS version and state—Displays the operating system version and the server’s current operating state.
![]() Line 9: Console prompt—Indicates the number of threads that have been stopped since the server was last rebooted, displayed in angle brackets next to the console prompt.
Line 9: Console prompt—Indicates the number of threads that have been stopped since the server was last rebooted, displayed in angle brackets next to the console prompt.

Abends are the most common type of server crash, and they provide a clear troubleshooting path. Server lockups, on the other hand, are a bit harder to diagnose and troubleshoot. A server lockup occurs when internal processing ends for no apparent reason. Lockups differ from abends in that all I/O is frozen and no error message appears. Most server lockups fall into one of two categories: full server lockup or partial server lockup.
When a full server lockup occurs, no processes are allowed to run, users are unable to log in, and all current connections are dropped. In addition, the server console keyboard is frozen. Partial server lockups freeze only the current server screen. Users might still be allowed to log in and some NLMs might continue to work.
A server lockup can be caused by a variety of different problems. For example, one possible cause is an NLM thread that becomes caught in a tight loop and fails to relinquish control of the server CPU. This type of server lockup can be related to either a hardware or software problem and can be controlled with the CPU Hog Timeout SET parameter. Another possible cause is a process that locks up resources by blocking access to them. Finally, server lockups can be caused by the same types of problems that cause server abends: corrupted operating system files, corrupted or outdated drivers, bad packets, or simple hardware failures.
If a server crashes and no abend or other error message displays, press Ctrl+Alt+Esc to access the Hung Server console screen. Select Down the File Server and Exit to DOS and then restart the server.
To help diagnose the cause of a server abend, you might be instructed by Novell technical support to generate a memory image file and to send it to them. This is called a core dump in reference to the core memory from the mainframe days. A core dump is a byte-for-byte representation of the NetWare server’s memory at the time of the abend.
The core dump contains the following information that can be used to analyze the problem:
![]() Processes—All processes on the server at the time of the abend are included in the core dump. The state of these processes can be running, waiting to run, or not in use. A history of what the process has done (call stack) is also preserved in the core dump.
Processes—All processes on the server at the time of the abend are included in the core dump. The state of these processes can be running, waiting to run, or not in use. A history of what the process has done (call stack) is also preserved in the core dump.
![]() Loaded modules—This includes module information, code, and data of all NLMs.
Loaded modules—This includes module information, code, and data of all NLMs.
![]() Allocated memory—This includes the memory allocated by processes included in the core dump.
Allocated memory—This includes the memory allocated by processes included in the core dump.
![]() Cache memory—Memory that’s available for allocation by modules or processes can also be included in the core dump. Most of the time it isn’t necessary to include cache memory in a core dump and the latest utilities allow it to be excluded from the core dump.
Cache memory—Memory that’s available for allocation by modules or processes can also be included in the core dump. Most of the time it isn’t necessary to include cache memory in a core dump and the latest utilities allow it to be excluded from the core dump.
![]() Screen shots—Console screens are preserved in the core dump. This includes helpful information such as the abend message, server name, and application error messages.
Screen shots—Console screens are preserved in the core dump. This includes helpful information such as the abend message, server name, and application error messages.
Normally, the abend error console gives you the opportunity to create a core dump file. However, you might encounter an error that causes you to force a memory image copy. This can be accomplished in one of three ways:
![]() Abend Console—The abend console will automatically prompt you to copy the memory image to a designated DOS drive. In NetWare 6, the following two SET parameters must be configured for the memory image copy to work: Auto Restart After Abend = 0 and Developer Option = On.
Abend Console—The abend console will automatically prompt you to copy the memory image to a designated DOS drive. In NetWare 6, the following two SET parameters must be configured for the memory image copy to work: Auto Restart After Abend = 0 and Developer Option = On.
![]() NetWare Debugger—If the NetWare server is running, press Left-Shift+Right-Shift+Alt+ Esc to load the NetWare Debugger. From the Debugger console, enter .c to start the diagnostic image copy. When the copy is finished, press G to enable NetWare to continue or press Q to exit to DOS.
NetWare Debugger—If the NetWare server is running, press Left-Shift+Right-Shift+Alt+ Esc to load the NetWare Debugger. From the Debugger console, enter .c to start the diagnostic image copy. When the copy is finished, press G to enable NetWare to continue or press Q to exit to DOS.
![]() Forced NMI—You can force the NetWare Debugger to load by issuing a non-maskable interrupt using an approved method from the server manufacturer.
Forced NMI—You can force the NetWare Debugger to load by issuing a non-maskable interrupt using an approved method from the server manufacturer.
TIP
An abbreviated version of the server memory image containing only the most vital components is automatically placed in the ABEND.LOG file. The total size of the memory image file is roughly equal to the size of server memory.
After you’ve created the core dump file, you must choose one of four destination storage media for it: floppy disk, hard drive, network drive, and/or parallel port (to an external hard drive). If you choose a floppy drive letter, the abend console prompts you for formatted 1.44MB disks. This destination medium should be used as a last resort because bad sectors on a single disk can make an image unreadable. A local DOS hard disk is a much better choice. In this case, the default image filename is COREDUMP.IMG. You can also copy the image to a NetWare drive using the IMGCOPY.NLM utility bundled with NetWare.
The ultimate level of memory image fault tolerance and performance can be accomplished using the network drive method (it is five times faster than other methods). To use this method, the server must meet the following minimum configuration: two NIC cards installed, at least one client driver loaded in DOS conventional memory, and NETALIVE.NLM running in server memory.
You can use the following five steps to troubleshoot server crashes and eliminate some of the most obvious causes:
1. Gather information—When faced with a critical server problem, you should gather as much information as you can, including error messages, complete hardware configurations, and disk and LAN driver information. You should also gather a list of the following: current NLMs and NCF files, the most recent changes made to the system, and all events that occurred prior to the crash. To help you gather this information, Novell provides an NLM called CONFIG.NLM, which creates a text file called CONFIG.TXT in the SYS:SYSTEM directory. This text file contains a list of all modules that were loaded on the server at the time it was run. It also tracks the contents of all NetWare and DOS startup files.
2. Identify probable causes—Next, identify probable causes by asking a variety of questions, such as the following: When did the abend problem begin? Did it coincide with any other activity? Is the server running the latest version of patches, drivers, and NLMs? Do the server error logs shed any light on the problem? After you’ve asked yourself any pertinent questions, restart the server and check the system error log and volume error log. Also check the ABEND.LOG file.
3. Test possible solutions—After you’ve gathered all the relevant information, you should begin formulating hypotheses. The first thing you can try is applying current patches, drivers, and NLMs. Next, you might want to consider replacing suspect components, such as NICs, memory chips, and hard drive controllers. (Note: You can isolate suspect components more easily by removing other hardware temporarily.)
4. Use debugging tools—If you haven’t been able to gather enough information to form conclusions about the abend or lockup, consider the use of additional debugging tools (such as MONITOR.NLM) and network analyzers (such as LANalyzer for Windows).
5. Resolve the problem and document the solution—After you’ve identified the cause of the server crash, you can implement the solution. Finally, be sure to document both the problem and its solution.
In general, server crashes can be dangerous. Fortunately, you can resolve them quickly and painlessly with just a bit of preparation and guidance. Here’s an important troubleshooting rule to remember:
The severity of a server disaster is directly related to your ability to recover from it.
In the event that you cannot recover from a server crash, you’ll need a reliable disaster recovery plan to fall back on. This plan should include recovery tools, procedures, and third-party solutions. The following are two vital components of a NetWare disaster recovery plan:
![]() VREPAIR for volumes
VREPAIR for volumes
![]() DSREPAIR for eDirectory
DSREPAIR for eDirectory
VREPAIR is an NLM that corrects minor data structure errors on a volume. DSREPAIR performs a similar operation on eDirectory databases. These utilities can solve only relatively minor problems. For really serious disaster recovery, you should consider third-party solutions such as ODR for NetWare and other professional data recovery services.
TIP
Before using VREPAIR (to recover from file system errors) or DSREPAIR (to recover from NDS disasters), you should create multiple backups and verify them carefully.
The VREPAIR NLM is designed to correct minor data structure errors on a volume. Like other system NLMs, VREPAIR is loaded from the SYS:SYSTEM directory, by default, unless otherwise instructed. VREPAIR can repair one dismounted volume while other NetWare volumes are functioning. One way to repair the SYS: volume is to load VREPAIR from the DOS partition. Alternately, you can load VREPAIR from the SYS: volume, press Alt+Esc, dismount the SYS: volume, and then run VREPAIR.
The following are some problems that VREPAIR might be able to solve:
![]() A hardware failure that either prevents a volume from mounting or causes a disk read error.
A hardware failure that either prevents a volume from mounting or causes a disk read error.
![]() A volume that was corrupted by a power failure.
A volume that was corrupted by a power failure.
![]() A server that displays memory errors and is unable to mount a volume after a namespace has been added. If this happens, you must either add more memory to the server or use VREPAIR to remove the newly added namespace.
A server that displays memory errors and is unable to mount a volume after a namespace has been added. If this happens, you must either add more memory to the server or use VREPAIR to remove the newly added namespace.
![]() A volume containing a namespace that needs to be removed.
A volume containing a namespace that needs to be removed.
![]() A volume containing bad blocks.
A volume containing bad blocks.
To run VREPAIR, you must first make sure that the target volume is dismounted. If this is the SYS: volume, confirm that VREPAIR.NLM is on the DOS partition. You can then use the SEARCH ADD command to create a console path. Whatever you do, make sure that you warn users on the volume to close their files before you dismount the volume. You can do this by using the BROADCAST or SEND console commands.
After you’ve dismounted the appropriate volume, follow these simple steps for repairing it:
1. Load the VREPAIR NLM by typing the following at the server console:
LOAD VREPAIR
2. Check the VREPAIR options and change them if necessary by selecting Set VREPAIR Options.
3. Select Repair a Volume from the Options menu. When the list appears, select the appropriate volume.
4. The Current Error Settings screen appears next. Change the current settings if necessary.
5. Choose the appropriate option to continue with the repair.
6. A screen appears listing total errors and current error settings. If VREPAIR seems to be finding a large number of errors, press F1 to change the setting to Not Pause on Errors.
7. Press any key to return to the Options menu. Then choose the appropriate option to exit.
8. Mount the repaired volume.
NetWare 6 includes the DSREPAIR.NLM utility, which repairs errors in the eDirectory database and resolves inconsistencies related to time and replica synchronization. The Advanced Options menu in DSREPAIR enables you to set advanced repair configurations, such as log file management, pause on errors, validation, schema rebuilding, remote server ID list, and scheduling.
The following is a list of eDirectory corruption symptoms that DSREPAIR might be able to solve:
![]() Users cannot create, delete, or modify objects, even though they have sufficient rights.
Users cannot create, delete, or modify objects, even though they have sufficient rights.
![]() Users cannot log in to the eDirectory tree with the correct username and password.
Users cannot log in to the eDirectory tree with the correct username and password.
![]() Unknown objects appear in the eDirectory tree and do not disappear after all servers are synchronized.
Unknown objects appear in the eDirectory tree and do not disappear after all servers are synchronized.
![]() Administrators cannot create, merge, or modify partitions.
Administrators cannot create, merge, or modify partitions.
To load DSREPAIR, type the following command at the file server console: LOAD DSREPAIR. You can also use the -U option, which loads DSREPAIR, performs volume repairs, and automatically exits upon completion. After the DSREPAIR process is complete, you can review the DSREPAIR.LOG file in the SYS:SYSTEM directory.
Network bottlenecks slow us down. If the disk is full, you cannot print. If the printer’s down, you cannot share saved files via hard copy. As a network troubleshooter, you need to be able to quickly identify bottlenecks and take steps to resolve them.
Most networks experience bottlenecks in four areas:
![]() Disk I/O
Disk I/O
![]() Network I/O
Network I/O
![]() CPU
CPU
![]() Bus I/O
Bus I/O
As you can see, bottlenecks don’t discriminate—they can occur anywhere. This makes troubleshooting bottlenecks an even greater challenge. In addition, bottlenecks are interdependent, which means that a problem in any of these four components can bring the entire network to its knees. Let’s take a closer look.
The server disk is probably the most active component in the network. It stores the central network operating system (NOS) and participates in almost every activity from file sharing to printing. This is a great place to start your bottleneck explorations.
The best way to determine whether you have a disk I/O bottleneck using traditional volumes is to load MONITOR.NLM at the server and check the number of dirty cache buffers. Also consider monitoring current disk requests. If these numbers are growing at a constant rate, you might have a disk I/O problem. Finally, on some machines, the disk light is a great indicator of overwork. You should be concerned if it’s continually flashing.
An obvious way to increase disk performance is to utilize faster disks. Using many smaller disks to replace one large one can also improve the speed of the disk subsystem. As you learned in Chapter 12, “Advanced Novell Storage Management,” RAID offers dramatic improvements in speed because of data striping and simultaneous disk requests. Upgrading to a fast disk controller can also alleviate disk I/O bottlenecks. Consider Fast SCSI II or Wide SCSI II for central servers. Refer to Chapter 12 earlier for more on disk I/O bottlenecks.
Next, check the communications path between users and the central server. Congestion and LAN traffic can often adversely affect network performance.
Probably the best way to identify network I/O problems is through the LAN/WAN Information screen in MONITOR.NLM. If any one of the following statistics is rapidly climbing, you might have a network I/O bottleneck (NetWare 6 statistics are shown in parentheses):
![]() Send packet too big (transmit failed, packet too big)
Send packet too big (transmit failed, packet too big)
![]() Receive packet overflow count (adapter overflow condition)
Receive packet overflow count (adapter overflow condition)
![]() Receive packet too big count (receive failed, packet too big)
Receive packet too big count (receive failed, packet too big)
![]() Send packet miscellaneous errors (transmit failed, miscellaneous errors)
Send packet miscellaneous errors (transmit failed, miscellaneous errors)
![]() No ECB available
No ECB available
![]() Packet receive buffers (receive discarded, no available buffers)
Packet receive buffers (receive discarded, no available buffers)
![]() Receive packet miscellaneous errors (receive failed, miscellaneous error)
Receive packet miscellaneous errors (receive failed, miscellaneous error)
The best way to solve network I/O bottlenecks is to upgrade the server NIC. Consider 32-bit bus mastering and/or peripheral-component interconnect (PCI). In addition, you might want to split the LAN channel into multiple segments by adding NICs to the server. Of course, at some point, the high level of network I/O will overload the server processor or disk. In this case, you might consider adding bridges or routers to externally segment the LAN. In either case, the goal is to minimize traffic overload.
With today’s fast CPU technology, processor performance is rarely an issue. Most Pentium III (and above) processors perform at sufficient speeds to handle network requests. Remember, the server is only handling 25% of the network’s overall processing. Of course, this doesn’t mean the server CPU is immune from bottleneck problems. If you’re using an older CPU with a slow clock speed (below 1GHz), you might run into problems. Also, CPU-intensive applications could create bottlenecks of their own. If CPU upgrading isn’t an option, consider using bus-mastering NICs and disk controllers. These devices communicate directly with each other and don’t bother the CPU for simple I/O tasks. This leaves the CPU free for all the important work.
The best way to identify CPU bottlenecks is with the Processor Utilization screen in MONITOR.NLM. Not only does it enable you to track CPU load, it also identifies specific internal resources. As a result, you can determine whether it’s the CPU or an NLM that’s causing the problem.
Bus I/O bottlenecks are related to server CPU problems. As a matter of fact, it’s difficult to distinguish between the two in many cases. Bus-mastering I/O devices contend with cache systems for access to main memory, but they run much slower than the CPU. Therefore, most high-performance servers are manufactured to overcome this problem by allowing I/O devices and the CPU to access memory simultaneously. If your server isn’t engineered to do this, consider upgrading to a model that is. This is especially important if you have many users and an active server disk.
This completes our lesson on network bottlenecks. The most important thing to remember is that the LAN is only as strong as its weakest component. Use MONITOR.NLM and other protocol analysis tools to track disk, network, CPU, and bus bottlenecks. This strategy goes a long way in helping you achieve holistic server fitness.
TIP
Study the four types of network bottlenecks listed in this lesson. Specifically, be able to identify which type of bottleneck is causing a specific network problem: disk I/O (high number of dirty cache buffers or current disk requests), network I/O (climbing receive packet overflow count or receive packet too big count), CPU (slow applications), and/or bus I/O (slow network communications). Finally, learn everything you can about bus mastering and remember that it can solve both network I/O and bus I/O bottlenecks.
This completes our lesson in server troubleshooting. So, what have we learned? First, we identified the architectural components of the hardware/software platform that is the NetWare server. Then we discovered that an ounce of prevention is worth more than a pound of cure. This strategy is implemented by maintaining the freshest server software available, solving communication bottlenecks, sending core dumps to Novell technical support, and solving a plethora of server memory, storage, and processor problems.
Next, in the final chapter of Part II (Chapter 17, “Novell eDirectory Troubleshooting”), we’ll extend beyond the server and develop an eDirectory fitness plan to help you ensure the health of your eDirectory. This fitness plan will accomplish two important goals: eDirectory performance and eDirectory reliability. In fact, we’ll develop our own eDirectory troubleshooting model with eight simple steps to guarantee the peaceful co-existence of eDirectory and users.
Remember, you are what you eat! And eDirectory offers a plethora of healthy leaves, roots, and a schema for flavor.