
Chapter 2. Processing messages with Mule
This chapter covers
- What role flows play in Mule
- How messages are created
- The structure of Mule messages
- The Mule Expression Language
Mule is a workhorse whose sole purpose in life is to move your messages around. It actually does way more than just moving messages: it’s also able to transform, enrich, and smartly route them. Picture a mail delivery service that would automatically rewrite letters in the preferred language of the recipient, while decorating them with illustrations that appeal to the culture of the addressee.
Where does such capacity come from? The answer is two words: control and abstraction.
Mule gives you complete control over the way messages flow through it. We said the word: Mule indeed uses flows as the main control structure in its configuration files. You’ve already seen a flow in the very first chapter of this book; it was used by Prancing Donkey to accept product registration data. In this chapter, you’ll learn more about flows and how they work, and the kind of control they give you when processing messages.
Mule also uses a set of abstractions that allows users to deal with complex message processing scenarios in a unified manner using consistent and generic artifacts. In this chapter, we’ll look into the abstractions that sit at the core of Mule, namely:
- The Mule message
- Message sources and processors
- Exchange patterns
- Endpoint URIs
We’ll take the time to delve deep into these abstractions, how they operate, and why they’re important. We’ll also look at how these abstractions are put in motion inside flows and how the Mule Expression Language dynamizes configurations. For this, we’ll look at more examples from Prancing Donkey’s systems, including their email order handler and part of their invoicing chain.
The journey may feel arid at times, but it’s a necessary voyage, so grab a fresh bottle of Prancing Donkey Pale Ale, relax, and get ready for the ride!
In Mule, things start moving when they get assembled in a flow. So let’s just go with it...
2.1. Going with the flow
Flows are the foremost elements of a Mule configuration. They typically start with a message source (discussed in section 2.2.1) followed by message processors (discussed in section 2.2.2), all chained together by the sole virtue of being encompassed by the flow element. Flows impose virtually no limit to the type of message processors that can be added in them or in what order they can be added.
Let’s circle back to the product registration flow you’ve already seen in section 1.4.2. Listing 2.1 shows this flow with a slight modification that you, astute reader, have certainly already spotted: a logger element has been added to allow Prancing Donkey to perform some activity auditing.
Listing 2.1. The product registration flow, now with logging
<flow name="product-registration">
<http:inbound-endpoint
address="http://api.prancingdonkey.com/products"
method="POST" />
<byte-array-to-string-transformer />
<logger level="INFO" category="products.registration" />
<jms:outbound-endpoint queue="products" />
</flow>
The same flow represented in Mule Studio would look like figure 2.1.
Figure 2.1. The product registration flow in Mule Studio

So where’s the message source? And what are the message processors? Let’s represent this flow slightly differently and make the difference between message sources and processors more apparent. Figure 2.2 uses ovals for message sources and rectangles for message processors. We’ll use the same representation in upcoming similar diagrams.
Figure 2.2. A symbolic representation of the product registration flow that highlights its message source and processors

In a flow, messages are produced by the message source and then processed along the top-down path, going from message processor to message processor. Following the message processors along this path gives you a good idea about how requests will be handled in a flow. Later in this chapter, and further in the book, you’ll see that this path can be altered by message processors. For example, routing message processors (discussed in chapter 5) allows you to exert even more control on the paths followed by messages.
Exceptional circumstances
Another important aspect of controlling message flows resides in exception handling. You’ll learn how to define alternate flow paths when exceptions occur in chapter 9.
If a message processor in a flow returns null, processing will be stopped right away. The response phase, discussed in the next section, won’t even be fired. Note that regular transformers or components can’t return null, but instead return a Null-Payload,[1] which doesn’t affect the flow execution.
1 Mule takes care of returning a NullPayload even if the transformer or component has returned null. This doesn’t apply to custom message processors.
Each flow represents a meaningful unit of work in your overall message processing needs. For example, receiving messages from a source, transforming them to a canonical form, and then sending them to another flow via an outbound endpoint for subsequent processing is a typical unit of work you’ll naturally roll out in one flow.
Mule offers specialized flow elements, named configuration patterns; these patterns are preconfigured flows designed to perform very specific tasks. Configuration patterns will be discussed in section 6.2.
Services = Flows + Constraints
Mule 2–style services are flows with extra constraints added that severely limit the types of message processors that can fit in them. Services have been kept in Mule 3 for backward compatibility. They are now legacy and shouldn’t be used anymore.
So far we’ve considered flows in one direction only: the top-down path. This path is the one taken by a message that comes into Mule and gets processed. But what about the opposite way? Let’s look at how flows behave when it comes to building and delivering responses.
2.1.1. The response phase
Understanding the response phase of flows is crucial to mastering the art of moving messages around Mule. We’ll take our time and do a deep dive into this concept so that you feel confident with what’s happening inside your flows.
The first thing to realize is that the response phase is implicit; it’s always present and, by default, consists of a simple echo of the message as it is at the end of the request phase, which is the top-down path in the flow. Though not apparent, the flow shown in listing 2.2 (used by Prancing Donkey for exposing their Accounts REST resource) has a response phase.
Listing 2.2. A flow with an implicit response phase
<flow name="accountService">
<http:inbound-endpoint exchange-pattern="request-response"
host="localhost"
port="8080"
path="services" />
<jersey:resources>
<component class="com.prancingdonkey.resource.Accounts" />
</jersey:resources>
</flow>
Mule Studio makes this response phase very apparent. Look at figure 2.3; the bottom part of the flow where arrows are pointed left (back to the HTTP-inbound endpoint) represents the response phase.
Figure 2.3. Mule Studio clearly shows the response phase.

The payload and properties used for the response are what they were in the Mule message when it hit the end of the flow (in top-bottom order). When a flow contains branching (like with a choice router; see section 5.1), it actually ends up having not a single but several possible endings, one at the end of each routing branch.
With this in mind, the second thing to consider is that Mule gives you the capacity to hook into the response phase with a specific configuration element appropriately named response. This allows you to add in a flow message processor that will only be called during the response phase. What can be a little confusing about elements in the response phase is that they kick-in in reverse order, from the bottom of the flow to its top (or more accurately, from where the flow ended back to where it started).
Take a look at the configuration in listing 2.3; can you guess what the response will be if we send a message to it with a payload of “hello”?
Listing 2.3. A flow with elements explicitly in the response phase
<flow name="explicitResponse">
<vm:inbound-endpoint path="input"
exchange-pattern="request-response">
<response>
<append-string-transformer message=" web" />
</response>
</vm:inbound-endpoint>
<response>
<append-string-transformer message=" wide" />
</response>
<append-string-transformer message=" world" />
</flow>
The right answer is “hello world wide web.” As expected, the string appenders have been hit in the following order: “world” during the request phase, then “wide” and “web” during the response phase. Notice how we’ve placed response elements in the main flow and in an endpoint.
Readability first
Locate response elements where it makes the most sense when reading the flow.
Response elements allow you to perform all the necessary processing to ensure that the message that will be returned to the caller of the flow has the expected content. You’ll typically perform message transformations in the response phase in order to prepare for delivery the payload that has been created by components or outbound endpoint interactions.
Finally, the last thing to consider is that the outcome of the response phase is ignored if the flow response is returned via reply-to routing. In that case, it’s the state of the message at the end of the request phase that’s used as the flow response. The message processors of the response phase are executed, but their outcome will be silently discarded.
That was quite a chunk of information to swallow! Now that you’re starting to grok the dynamics of flows, let’s take a look at how flows can be modularized.
2.1.2. Subflows
Copy-pasting is the bane of software development. If you reach the point where you start to have a lot of commonality between your flows, you should quickly feel the need to extract and reuse common sequences of message processors across your flows. Enter subflows, a configuration construct that has been created for this very purpose.
A subflow behaves like a standard flow, but without a message source. It receives messages to process only when explicitly invoked by name via a flow-ref element. You can think of a subflow as a macro that contains a predefined set of message processors and which you can invoke on demand.
When a flow invokes a subflow, the whole Mule message (payload, properties, attachments) and its context (session, transactions) are passed to the subflow. Similarly, the complete context of the result of the subflow is passed back to the main flow. Actually, everything behaves as if the message processors in the subflow were in the main flow. It’s also important to note that the caller thread is used to execute the subflow.
A chain with a name
Conceptually, a subflow is a processor-chain that’s named, can live outside of a main flow, and can be invoked by any flow. It’s very similar to a macro in your favorite office productivity suite.
Listing 2.4 illustrates this by showing how Prancing Donkey leveraged subflows to share a common message transformation chain in the context of a migration strategy, which impacts many flows. In the listing, you can see how they placed a set of transformers in a subflow and reused them in two different flows. As expected, messages going through these flows will be transformed by the set of transformers as if they were directly configured in each of them.
Listing 2.4. Using a subflow to share a common set of transformers
<sub-flow name="legacyAdapterSubFlow">
<mulexml:xslt-transformer xsl-file="v1_to_v2.xsl" />
<mulexml:xml-to-object-transformer />
</sub-flow>
<flow name="mainFlow1">
<http:inbound-endpoint host="localhost"
port="8080"
path="v1/email" />
<flow-ref name="legacyAdapterSubFlow" />
<component class="com.prancingdonkey.service.v2.EmailGateway" />
</flow>
<flow name="mainFlow2">
<jms:inbound-endpoint queue="v1.email" />
<flow-ref name="legacyAdapterSubFlow" />
<component class="com.prancingdonkey.service.v2.EmailGateway" />
</flow>
The same code is shown as represented by Mule Studio in figure 2.4.
Figure 2.4. Two flows and a subflow shown in Mule Studio

This is pretty straightforward. Oftentimes, you’ll face a situation where reuse is needed, but there isn’t a clear-cut set of processors you can extract and share. Bear in mind that flow variables (a.k.a. invocation-scoped message properties, discussed in section 2.3.1) can help enable reuse because they can act as flow-control variables, introducing the dynamic part that may be missing in your original configuration.
Let’s illustrate this with an example. Consider the subflow in listing 2.5. It relies on the preexistence of a custom flow variable named valid to direct the message to one path or another in the choice router. It’s the responsibility of each parent flow to set this message property based on the specific validity rules they enforce. Everything else has been put in common in the shown subflow.
Listing 2.5. Flow variables can be used to parameterize a subflow.
<sub-flow name="requestDispatcher">
<choice>
<when expression="#[valid]">
<vm:outbound-endpoint path="valid.request.handler"
exchange-pattern="request-response" />
</when>
<otherwise>
<vm:outbound-endpoint path="invalid.request.handler"
exchange-pattern="request-response" />
</otherwise>
</choice>
</sub-flow>
If you have experience with Mule before version 3, you have certainly used a lot of VM endpoints to tie services together (the VM transport will be discussed in section 3.8). Should subflows be used all the time, or does tying together flows with VM endpoints still make sense? A big differentiator between the two approaches is that a subflow invocation carries all the message properties along while a VM endpoint message exchange requires copying properties across scopes. On the other hand, using a VM queue to connect flows introduces decoupling that can be useful in some situations.
Mule offers another option for sharing flows called private flows. Let’s see how they differ from subflows and when it’s a good time to use them.
2.1.3. Private flows
Private flows are another type of reusable flows, very similar to subflows, but with a different behavior in terms of threading and exception handling. The primary reason for using a private flow instead of a subflow is to define in it a different exception strategy from the calling flow (something that is impossible with a subflow). Another reason is that subflows aren’t materialized at runtime and, as such, don’t have specific statistics or debug properties attached to them and can’t be controlled or monitored independently. Private flows offer all this.
As we said in the previous section, when a subflow is invoked, the execution behaves as if the message processors of the subflow were actually located in the calling flow. With a private flow, the execution behaves as if a message was passed from the calling flow to the private flow. This decoupling allows for defining processing and error handling strategies that are local to the private flow.
So what does a private flow look like? Basically it’s just a regular flow, but without any message source. To illustrate this, let’s revisit the subflow used by Prancing Donkey to transform messages from an old format to a new one (see listing 2.4). It happened that for a small subset of messages, the transformation was failing; they then decided to configure an exception strategy local to the transformation in order to send failed messages to a JMS queue for later analysis and reprocessing. For this, they had to convert their subflow into a private flow as shown in the next listing.
Listing 2.6. Using a private flow to define a local exception strategy
<flow name="legacyAdapterPrivateFlow" processingStrategy="synchronous">
<mulexml:xslt-transformer xsl-file="v1_to_v2.xsl" />
<mulexml:xml-to-object-transformer />
<catch-exception-strategy>
<jms:outbound-endpoint queue="legacyAdapter.failures" />
</catch-exception-strategy>
</flow>
In the previous example, you may have noticed that we’ve configured an attribute named processingStrategy on the private flow. Though not compulsory, we strongly recommend that you do so for all your private flows, selecting either a synchronous or an asynchronous strategy, depending on the expectations of the calling flow (use synchronous if the calling flow expects a response from the private flow).
If you don’t specify the processing strategy, Mule will use the synchronicity of the inflow event to select one. Events generated from one-way endpoints will be executed asynchronously even if the calling flow is expecting a response from the private flow. We’ll have an in-depth discussion of flows’ processing strategies in chapter 11.
Similarly, we strongly recommend that you wrap your flow-ref invocations towards asynchronously processed private flows with <async> blocks (see section 5.3.3). Strictly defining the expected invocation and processing behavior with private flows will save you headaches.
In Mule Studio, the only notable difference with a subflow is in the grey label before the private flow name, which says flow, as shown in figure 2.5.
Figure 2.5. A private flow shown in Mule Studio

So far, we’ve focused on flows and the control they give you over how messages transit within Mule. We’ll now look in detail into the message interactions Mule supports and the set of abstractions that enables these interactions.
2.2. Interacting with messages
Mule supports a handful of interactions that lead to either creating a new message or processing an existing one. It’s important you become knowledgeable about the lingo used for these interactions, so let’s review it in detail:
- Receiving happens in message sources when an external event occurs (for example, a new HTTP request or an incoming JMS message), generating a new Mule message.
- Polling happens in message sources too, but this time at the initiative of Mule, at a particular frequency, also generating a new Mule message.
- Dispatching happens in message processors when Mule sends out a message, but doesn’t wait for a response.
- Sending happens in message processors when Mule sends out a message and waits for a synchronous response. This response generates a new Mule message.
- Requesting happens programmatically and thus whenever decided, generating a new Mule message by fetching data from a particular source (for example, reading a particular file content or consuming one message out of a JMS queue). Requesting can be done by code using the Mule client (see section 12.2).
Don’t be alarmed if your head spins a little; we’ll come back to these interactions many times in the remainder of the book. For now, it’s good enough that you’ve been exposed to this terminology.
To support these interactions, Mule relies on a set of core abstractions that act as a foundation for all the other aspects of message processing. In this section, we’ll detail the following abstractions, a grasp of which is fundamental to successfully using Mule:
- Message sources
- Message processors
- Message exchange patterns
- Endpoint URIs
First things first, so let’s start with message sources.
2.2.1. Message sources
In a Mule configuration, message sources usually manifest themselves as inbound endpoints. Pollers (discussed in section 14.4.1) are also commonly used message sources. Cloud connectors can also provide message sources that can be used in a configuration (more on this in section 13.2.7).
Only a single message source is allowed in a flow (discussed in section 2.1). To allow multiple inbound endpoints to feed messages in the same flow, a composite message source must be used. As you’ve guessed, this composite message source is also a message source! The following listing shows a few valid message sources, including a composite one.
Listing 2.7. Simple and composite message sources
<vm:inbound-endpoint path="payment-processor" />
<composite-source>
<jms:inbound-endpoint queue="payment-processor" />
<http:inbound-endpoint host="localhost"
port="8080"
path="payment-processor" />
</composite-source>
Composite message sources
Each endpoint in a composite message source will start a new flow execution when it receives a message. There’s no constraint on the transports, nor even on the exchange patterns of the inbound endpoints in a composite source. You mix and match at will!
That wasn’t too hard, so let’s immediately jump into the next abstraction: message processors.
2.2.2. Message processors
Message processors are the basic building blocks of a Mule configuration; as you’ve seen in the previous section, besides message sources, flows are mostly composed of message processors. Message processors take care of performing all the message handling operations in Mule and as such manifest themselves in the configuration under a diversity of elements.
Here’s a list of the main features provided by message processors:
- As outbound endpoints (discussed in section 3.1), they take care of dispatching messages to whatever destination you want.
- As transformers (discussed in chapter 4), they’re able to modify messages.
- As routers (discussed in chapter 5), they ensure messages are distributed to the right destinations.
- As components (discussed in chapter 6), they perform business operations on the messages.
Most of the time, you’ll be configuring message processors without knowing it; all you’ll see in your configuration files will be transformers, components, or endpoints. The fact that all these diverse entities are message processors is the key to Mule’s versatility; it allows you to freely tie them together in flows, since behind the scene they’re all of the same nature and thus interchangeable.
Shoehorn message processors with a chain
When only a single message processor is allowed at a configuration location, use a processor-chain element, which is a message processor that can encapsulate several message processors that will be called one after the other (as if they were chained).
It’s also possible to create custom message processors by implementing the org.mule.api.processor.MessageProcessor in a custom class and referencing it in the configuration with a custom processor element. This is extremely powerful, but at the cost of a direct exposure to Mule internals (something components shield you from).
The next abstraction we’ll explore deals with the time aspect of message interactions.
2.2.3. Message exchange patterns
Message exchange patterns (MEPs) define the timely coupling that will occur at a particular inbound or outbound endpoint. By defining if an endpoint interaction is synchronous or asynchronous, a MEP influences the way both sides of the endpoint (sender and receiver or, said differently, client and server) interact with each other.
Currently, Mule supports only two MEPs:
- One-way, where no synchronous response is expected from the interaction
- Request-response, where a synchronous response is expected
Both MEPs can be used on inbound and outbound endpoints, but some transports can apply restrictions to the MEPs they actually support (for example, POP3 is one-way). On inbound endpoints, one-way means Mule won’t return a response to the caller, while request-response means it will. On outbound endpoints, one-way means Mule won’t wait for a response from the callee, disregarding it if there is one, while request-response means it will.
Say something!
If a client calls a one-way service and blocks expecting a response, it will receive an empty one. For example, performing a GET on an in-only HTTP inbound endpoint will return an empty response (content length of size 0) and a 200 OK status. The notable exception to this is the VM transport; both client and server must be in agreement for the MEP they use, otherwise the message exchange will fail.
Don’t equate one-way with fire-and-forget; Mule ensures that the messages have been correctly delivered over a one-way endpoint. For example, when dispatching to a one-way JMS endpoint, Mule will ensure that the message has been reliably delivered and will raise an exception if that’s not the case. The same will apply to a one-way HTTP endpoint, whereas the biggest difference with request-response endpoints is that Mule will stop caring for the HTTP interaction as soon as it gets a response status code.
Let’s illustrate this with an example. Look at listing 2.8 to see two different HTTP endpoints, each configured with a different MEP (configured by the exchange-pattern attribute). The inbound endpoint uses the request-response MEP, so it will provide synchronous responses to clients that send HTTP requests to it. On the other hand, the outbound endpoint is one-way, which means that Mule (acting as client in this case) won’t wait for any response from the remote server, whether there is one or not.
Listing 2.8. HTTP endpoints with different exchange patterns
<http:inbound-endpoint host="localhost"
port="8080"
path="payment-processor"
exchange-pattern="request-response" />
<http:outbound-endpoint host="localhost"
port="8081"
path="notifier"
exchange-pattern="one-way" />
MEPs affect the timeline of message interactions; request-response creates a timely coupling, while one-way avoids it. MEPs have a direct impact on the parallelization of tasks in Mule, and when this happens, flows may behave in mysterious ways.
To illustrate this, let’s take a look at the configuration in the next listing.
Listing 2.9. A simple flow in which execution doesn’t happen as expected
<flow name="acmeApiBridge">
<vm:inbound-endpoint path="invokeAcmeAmi" />
<jdbc:outbound-endpoint queryKey="storeData" />
<http:outbound-endpoint address="http://acme.com/api" />
</flow>
Prancing Donkey uses this configuration to keep track of the state of HTTP conversations in a database. This flow is used when a new conversation with the Acme Corp. API is initiated. In another flow, out-of-band HTTP responses further change the state of the conversation. Surprisingly, issues have arisen because in this flow it happens from time to time that the HTTP request gets dispatched before the JDBC insert, though the latter is positioned before the former in the configuration. How is that possible?
To answer this question, let’s look at the log file recorded while a message goes through the flow of listing 2.9:
DEBUG acmeApiBridge.stage1.02 [HttpConnector]
Borrowing a dispatcher for endpoint: http://acme.com/api
INFO jdbcConnector.dispatcher.01 [SimpleUpdateSqlStatementStrategy]
Executing SQL statement: 1 row(s) updated
DEBUG acmeApiBridge.stage1.02 [HttpClientMessageDispatcher]
Connecting: HttpClientMessageDispatcher{this=1e492d8,
endpoint=http://acme.com/api, disposed=false}
Pay attention to the thread names (recorded between the log level and the class name in square brackets). What do you see? Bingo! The JDBC insert is performed by a different thread than the main one that goes through the flow (notice how it’s named after the flow name). Why does Mule perform the JDBC operation in a separate thread?
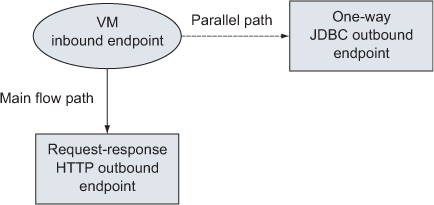
The answer to this excellent question lies in the message exchange pattern used by each endpoint. Notice how in this previous flow no exchange pattern is specified; the default ones are thus used, meaning one-way for JDBC and request-response for HTTP. Because it’s one-way, Mule knows no response is expected in the flow and consequently detaches the processing of this particular interaction in a separate thread!
Figure 2.6 illustrates how a one-way MEP initiates parallel processing of the message interaction. In section 5.3.3, we’ll look at other ways to parallelize message processing.
Figure 2.6. Message exchange patterns influence a flow’s threading model.
No guessing game
Make your flows predictable; don’t rely on transport defaults, and use explicit MEPs on your endpoints.
The last abstraction we’ll look at is not the least: endpoint URIs are indeed the means by which Mule is able to represent all the resources it interacts with (message sources and destinations) in a unified manner.
2.2.4. Endpoint URIs
Mule uses Uniform Resource Identifiers (URIs) as the unified representation for all the resources it exposes or accesses via its endpoints. In other words, inbound and outbound endpoints are internally configured by a URI. Externally, in the XML configuration, they’re configured by specific elements with transport-specific attributes. Behind the scenes, all this information is folded into an endpoint URI.
Don’t skip this section thinking that you’ll never have to deal with endpoint URIs since they’re internal. In fact, you’ll need to understand endpoint URIs no later than in the last section of this chapter. Indeed, the Mule client uses endpoint URIs to interact with Mule or through Mule (more about this in section 12.2).
Take a look at the following examples. Though the URI representation for HTTP resources is obviously feeling familiar, note how a JMS topic and a TCP socket are also very naturally represented with this scheme. Notice how query parameters, like a connector name, are used to provide extra information to Mule:
http://localhost:8080/products jms:topic://news tcp://localhost:51000?connector=pollingTcpConnector
Now compare that with listing 2.10, which shows a Mule configuration exposing resources at the URIs listed in the preceding code block; the external/internal correspondence we were talking about previously should feel much clearer.
Listing 2.10. Mule endpoints exposing different types of resources
<http:inbound-endpoint host="localhost"
port="8080"
path="products" />
<jms:inbound-endpoint topic="news" />
<tcp:inbound-endpoint host="localhost"
port="51000"
connector-ref="pollingTcpConnector" />
That’s it, you’ve discovered the most important abstractions at work within the very core of Mule.
No URIs for DevKit Connectors
Connectors built with DevKit (see section 13.1) don’t expose standard Mule endpoints, so they aren’t accessible via endpoint URIs.
We’ve been talking about messages moving around in Mule. But what is the exact nature of these messages? It’s now time to take our magnifying glass and explore the Mule message.
2.3. Exploring the Mule message
When a message transits in Mule, it is in fact an event (for example, an instance of org.mule.api.MuleEvent) that’s moved around. This event carries not only a reference to the actual message itself (for example, an instance of org.mule.api.Mule-Message), but also the context in which this message is processed. This event context is composed of references to different objects, including security credentials, if any, the session in which this request is processed, and the global Mule context, through which all the internals of Mule are accessible. This is illustrated in figure 2.7.
Figure 2.7. The MuleEvent and its main objects

In this section, we’ll focus exclusively on the structure of the Mule message and leave the discussion of the encapsulating event to chapter 12. This will be more than enough to cover all your needs in the vast majority of Mule use cases.
A Mule message is composed of different parts, as illustrated in figure 2.8.
Figure 2.8. Structure of the Mule message

- The payload, which is the main data content carried by the message
- The properties, which contain the meta information of the message
- Optionally, multiple named attachments, to support the notion of multipart messages
- Optionally, an exception payload, which holds any error that occurred during the processing of the event
Messages are normally created by message sources (discussed in section 2.2.1), whether because they’ve received an incoming event (like a new HTTP request or an incoming JMS message) or because they’ve successfully polled a resource (like a filesystem or a database). Messages can also be created programmatically (see section 12.3.2).
Thread safety
By default, Mule ensures that only a single thread can modify a message at any point in time. Message copying is a common way to pass messages between threads.
Figure 2.9 illustrates messages that have been created by HTTP (left) and email (right) sources. Notice how the Mule message structure is versatile enough to carry all the relevant information from these two very different transports.
Figure 2.9. Mule messages can contain data from any source.
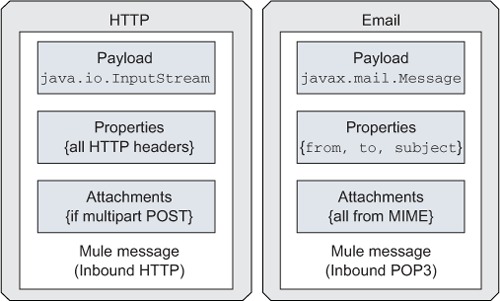
As illustrated in figure 2.9, the Java class of the message payload depends on the origin of the message. Byte arrays, implementations of java.io.InputStream, or String are payload types commonly created by standard Mule transports. More transport-specific payload types, like java.io.File for the File transport, can be also be carried by Mule messages.
The payload wouldn’t be enough to ensure that the whole context of an event has been captured and is being propagated in Mule. This is when message properties come into play.
2.3.1. Message properties
Message properties are meta information that provides contextual data around the payload that’s being carried by Mule. This meta information is created automatically when a new message is generated (typically by an inbound endpoint). Message properties are also read by Mule when it needs to dispatch a message to a particular destination (typically via an outbound endpoint). On top of that, message properties are often used when processing or routing messages.
Concretely, message properties are defined by a name (string), a value (object), and a scope (enumeration). While name and value are pretty much self-explanatory, we’ll discuss scope in the next section.
Usually, message properties represent the meta information coming from the transport that’s underlying the source they originate from. More precisely, message properties encompass the following:
- Generic transport meta information, which is stored as-is in message properties. Think about the headers of an HTTP request or the properties of a JMS message. Some transports, like TCP, don’t create any generic meta information.
- Mule-specific transport meta information, used by the transport to store extra contextual information in the message. For example, the request path of all HTTP requests received by Mule is stored in a property named http.request.path.
Most Mule transports have outbound endpoints that are intrinsically sensitive to message properties. For example, the SMTP transport automatically recognizes properties relevant to all the meta information required to send an email, like subject or toAddresses (see section 3.5.2).
Transport properties
Some transports have requirements regarding property names. For example, the JMS transport will remind you loud and clear when you’re trying to make it use properties that aren’t compatible with the JMS spec!
Unfortunately, no authoritative list of all the properties transports create or recognize exists; you’ll need to consult the online reference documentation for each transport you’re interested in. Moreover, we suggest using the logger message processor in development mode to discover what properties are actually created by a transport.
Message properties are strictly scoped in Mule. Let’s see what this means.
2.3.2. Understanding property scopes
As the name scope suggests, properties in one scope aren’t available in another. This means that, unlike payloads, message properties won’t automatically be carried across Mule. Scopes are boundaries that properties won’t propagate through. But how are these boundaries defined?
Flows define the boundaries that property scopes abide by. More precisely, flows’ inbound and outbound endpoints are the boundaries between which message properties can travel. Figure 2.10 illustrates the different property scopes and how they relate to these boundaries.
Figure 2.10. Properties’ scopes determine their travel boundaries.

To recapitulate, Mule fully supports four property scopes:
- Inbound— Created by message sources like inbound endpoints, these properties are read-only for the end user. Inbound properties can be wiped out midflow by outbound endpoints; if this happens to you, message enrichment is your friend (see section 4.3.5).
- Outbound— Created by set-property, message-properties-transformer with outbound scope, or code and recognized by outbound endpoints.
- Invocation— Created by set-variable, message-properties-transformer with invocation scope, or code, mainly known as flow variables because they are strictly bound to a flow.
- Session— Created by message sources, set-session-variable, message-properties-transformer with session scope, or code, this scope is bound to the in-flight message[2] and can therefore span multiple flows, as it follows the message through them (think of Java’s ThreadLocal mechanism but with a MessageLocal twist).
2 And not to the conversation with the remote client, like with a web container session.
Crossing boundaries
Use the copy-properties element to copy properties across scopes, for example, to propagate an inbound property to the outbound scope or to store it in the session scope.
So far, we’ve focused on properties in the context of the request phase. What happens to them in the response phase? As you might expect, during the response phase (discussed in section 2.1.1) things are reversed. Inbound endpoints look for properties in the outbound scope to propagate to their callers. Request-response outbound endpoints create inbound properties. Only the flow and session variables behave the same, provided they’ve been preserved and have remained unaffected by the interactions that happen in message processors.
Let’s make this concrete. Take a look at listing 2.11, which illustrates how to set the HTTP content-type header in the response phase; see how we’ve created the property so that the inbound endpoint uses it when it responds to its caller? The trick here is that set-property creates properties in the outbound scope.
Listing 2.11. Adding a header to the outbound scope adds it to the response
<flow name="responseHeader">
<http:inbound-endpoint exchange-pattern="request-response"
host="localhost"
port="8080"
path="json/data" />
<component class="com.prancingdonkey.data.JsonDataFetcher" />
<response>
<set-property propertyName="Content-Type"
value="application/json" />
</response>
</flow>
Response phase property propagation
Propagating a message property from the response of an outbound endpoint back to the caller of an inbound endpoint requires copying it from the inbound to the outbound scopes in the response phase.
Let’s look at another example, with more scopes involved. Listing 2.12 shows a flow that receives an XML user representation. It extracts its ID with an XPath expression and stores it in a flow variable named userId. This flow variable is subsequently used in two places: in an HTTP outbound endpoint in order to build a REST resource URI, and in a response block to add a property named X-User-ID. As you can see, the invocation scope is still active in the response phase; the flow variable that was set in the inbound phase is still present in the response phase.
Listing 2.12. A flow that sets a variable and uses it in two places
<flow name="flowVarPersistence">
<vm:inbound-endpoint path="user.fetch"
exchange-pattern="request-response" />
<response>
<set-property propertyName="X-User-ID"
value="#[userId]" />
</response>
<set-variable variableName="userId"
value="#[xpath('/user/@id').value]" />
<http:outbound-endpoint
address="http://${internalApiBaseUri}/api/users/#[userId]"
method="GET"
exchange-pattern="request-response" />
</flow>
Accessible but not owned
Though the flow and session variables are both accessible via the properties accessor of a Mule message, they are, behind the scene, respectively owned by the Mule Event and Session objects. For convenience, the Mule message shares references to the maps that back these two scopes.
Though less frequently used, attachments are also important members of a Mule message. Let’s look into them.
2.3.3. Using message attachments
As briefly presented in the introduction, message attachments allow for supporting extra chunks of data that aren’t meta information, semantically speaking, but that are more like alternative or complementary chunks of payload.
An attachment is defined by a name, a source of data (an instance of javax.activation.DataHandler), and a scope. Attachments’ scopes are limited to inbound and outbound, with the same flow-bound boundaries as the properties’ scopes.
Attachments are mainly used to support the multiple parts of inbound email messages (created with the POP or IMAP transport) and outbound email messages (sent with the SMTP transport). Inbound attachments are created by the email endpoint directly, while outbound endpoints require attachments to be created -programmatically.
The following listing shows a flow that’s used by Prancing Donkey to accept email orders.
Listing 2.13. Extracting message attachments with an expression transformer

Notice at ![]() how an expression transformer is used to extract all the attachments and replace the current message payload with the extracted
attachments list (inbound-Attachments is a java.util.Map of attachment names and values). Though Prancing Donkey likes a little chitchat from time to time, in this particular case,
the email message body that was stored in the message payload after
how an expression transformer is used to extract all the attachments and replace the current message payload with the extracted
attachments list (inbound-Attachments is a java.util.Map of attachment names and values). Though Prancing Donkey likes a little chitchat from time to time, in this particular case,
the email message body that was stored in the message payload after ![]() is abandoned in favor of the attachments. Because customers are allowed to attach several invoices to one email, a message
splitter
is abandoned in favor of the attachments. Because customers are allowed to attach several invoices to one email, a message
splitter ![]() is used to split the attachment list into individual messages, each of them processed downstream by a service behind the
endpoint called at
is used to split the attachment list into individual messages, each of them processed downstream by a service behind the
endpoint called at ![]() .
.
This wraps up our in-depth discussion about the structure and hidden goodness of Mule messages. Payload, properties, scopes, and attachments should by now have lost their mystery for you.
We’ve alluded to it in many places, so it’s now time to look into the Mule Expression Language.
2.4. Speaking the Mule Expression Language
As we said in the opening of this chapter, expressions are the way to bring dynamism to your configuration. Indeed, Mule offers a rich expression language that allows you to hook advanced logic into different parts of your configuration.
Expressions reloaded
The Mule expression evaluation framework has gone through a complete overhaul in version 3.3. The old syntax, which was of the form #[evaluator:expression] and required two attributes (expression and evaluator), has been deprecated and replaced by a unified syntax. We’ll cover only this new syntax in the book.
The Mule Expression Language, a.k.a. MEL, is based on the MVFLEX Expression Language (MVEL), which gives access to a complete range of programmatic features, enriched with Mule-specific variables and functions. MEL’s thorough documentation is available online, so we’ll only discuss here its general principles before delving into a few examples (you can also refer to appendix A for a more detailed reference).
With MEL, you can do the following:
- Use any Java class available on the classpath
- Easily navigate lists, maps, arrays, and bean properties
- Express complex logic, including ternary expressions
- Define local variables and use them in statements
On top of that, Mule binds a set of top-level objects that act as entry points to Mule’s overall execution context, but also to the context of the message currently processed. Currently, four context objects are available:
- server— Properties of the hardware, operating system, user, and network interface, for example, server.ip
- mule— Properties of the Mule instance, for example, mule.version
- app— Properties of the Mule application into which the expression is evaluated, for example, app.name
- message— The in-flight Mule message, for example, message.correlationId or message.payload
Mule also binds helper methods as top-level members of the evaluation context. As of this writing, two helpers are available:
- xpath— To easily extract values from XML payloads or any other MEL expressions, for example, xpath('/orders/order[0]')
- regex— To return an array of matches for payloads or any other MEL expressions, for example, regex('^(To|From|Cc):')
Extending MEL
It’s possible to extend MEL in order to define custom imports, reusable functions, and even global aliases. Refer to appendix A, section A.2, for more information.
It’s valid to place several statements in the same expression, as long as they’re separated by semicolons. The value of the last statement is used as the value of the whole expression. For example, evaluating the following expression
targetDir = new java.io.File(server.tmpDir, 'target'), targetDir.mkdir(); targetDir
returns targetDir as a java.io.File (and also ensures that it exists).
In the XML configuration, it’s recommended to wrap the expression with a hash-square #[] in any attribute where you use an expression (not using #[] works in many places, but the behavior is not consistent enough to be relied on). For example, though the following no-hash-square expression works,
<when expression="message.inboundProperties['valid']">
we recommend you use
<when expression="#[message.inboundProperties['valid']]">
This doesn’t apply to expression components (discussed in section 6.1.6), in which the #[] can be omitted.
Let’s now look at a few examples using expressions.
2.4.1. Using expressions
Expressions can be used almost anywhere a string attribute is expected in the XML configuration. Of course, because they’re evaluated at runtime when messages are flying through Mule, you can’t use expressions that require an in-flight message to work in values that are read by Mule on startup (say, for example, a port to which Mule must bind).
Almost everywhere
Expressions are well supported across all Mule modules and transports. This said, you may still encounter in your configurations XML attributes in which expressions are not supported. If that’s the case, raise the issue with MuleSoft (www.mulesoft.org/jira/browse/MULE).
Listing 2.14 shows how the java.util.UUID class is used to dynamically create a transaction ID and pass it to an XSLT transformer (discussed in section 6.1.6). Notice how, because an expression-specific XML attribute wasn’t available, the expression needed to be hash-square wrapped as discussed previously.
Listing 2.14. Using an expression to create a dynamic XSLT parameter
<mulexml:xslt-transformer xsl-file="to_payment_processor_call.xsl">
<mulexml:context-property key="transactionId"
value="#[java.util.UUID.randomUUID().toString()]" />
</mulexml:xslt-transformer>
Message processors make fair usage of expressions too. In section 4.3.5, we’ll discuss the message enricher, a message processor that relies heavily on expressions. Another message processor that relies on expressions is the logger.
Take a look at listing 2.15 to see how the xpath helper is used by Prancing Donkey for logging the invoice ID out of an in-flight message with an XML payload. Notice also how the getValue() method is called on the org.dom4j.Attribute returned by the xpath evaluation via the value short bean property access.
Listing 2.15. Logging a value extracted with XPath
<logger message="#[xpath('/invoice/@id').value]"
category="com.prancingdonkey.service.Invoice.id"
level="INFO" />
Another way in which expressions are used a lot is to express the decision logic of conditional routers, like the choice router and other similar filtering routers. These routers will be discussed in detail in section 5.2.
True or false
MEL expressions that return Boolean values can be used in conditional logic. String values that can be evaluated as Booleans can be used too, but we prefer the stricter approach that results in returning true Booleans.
Configuration patterns, discussed in section 6.2, also rely a lot on expressions in order to offer the most concise configuration possible. Listing 2.16 shows a validator pattern that uses simple string literals for its acknowledgement and rejection messages. It also uses MEL for checking if the in-flight message has any attachment.
Listing 2.16. The validator configuration pattern heavily relies on expressions.
<pattern:validator name="ensureAttached"
inboundAddress="vm://ensure.attached"
outboundAddress="vm://valid.request.handler"
ackExpression="#['OK']"
nackExpression="#['ERROR: no attachment!']">
<expression-filter
expression="#[!(message.inboundAttachments.empty)]" />
</pattern:validator>
Expressions can also be used in the configuration of endpoints. Consider, for example, listing 2.17, which shows a flow that allows for dynamically fetching stock market history. This flow receives the ticker identifier as its main payload, but doesn’t assume that it will be a java.lang.String (it could very well be byte[]). Instead, it uses a payload evaluator to fetch the current payload and transform it into a java.lang.String before building the HTTP path with it.
Listing 2.17. Expressions in endpoint URIs can be resolved at runtime by evaluators.
<flow name="tickerFetcher">
<vm:inbound-endpoint path="ticker.fetcher"
exchange-pattern="request-response" />
<http:outbound-endpoint
exchange-pattern="request-response"
host="www.google.com"
port="80"
path="finance/historical?q=#[message.payloadAs(java.lang.String)]" />
</flow>
It’s possible to use the Mule expression evaluation framework from your own code. The only thing you need is a reference to the Mule context (discussed in section 12.1), which allows you to use the expression language evaluator:
ExpressionLanguage mel = muleContext.getExpressionLanguage();
String applicationName = mel.evaluate("app.name");
You should find that the evaluation methods on the evaluator are pretty self-explanatory; if not, refer to the Mule API SDK (www.mulesoft.org/docs/site/current3/apidocs/).
Expressions can be used in annotations too (see section 6.1.4). For that, the @Mule annotation must be used, as shown here:
@Mule("#[app.name]")
String applicationName
We can’t possibly cover all the possibilities of MEL in this section. But throughout the remainder of the book, you’ll have plenty of opportunities to see the power of MEL in action!
2.5. Summary
We’re done with our tour of Mule message processing capacities. You’ve learned about controlling message paths with flows. You’ve also discovered the abstractions that sit at Mule’s core, the true nature of messages that move around in Mule, and how expressions can help you solve advanced problems that static configurations can’t.
It’s now time that you expand your horizon by looking into the different ways that Mule reaches the outside world. The next chapter will cover Mule transports and cloud connectors and how you can use them to transfer data using popular protocols and APIs.