
Chapter 9. Exception handling and transaction management with Mule
- Error handling strategies
- Using transaction mechanisms in Mule
- Using transaction demarcation
Dealing with the unexpected is an unfortunate reality when you’re writing software. Through the use of exceptions, the Java platform provides a framework for dealing with events of this sort. Exceptions occur when unanticipated events arise in a system. These events include network failures, I/O issues, and authentication errors. When you control a system, you can anticipate these events and provide a means to recover from them. This luxury is often absent in a distributed integration environment. Remote applications you have no control over will fail for no apparent reason or supply malformed data. A messaging broker somewhere in your environment might begin to refuse connections. Your mail server’s disk may fill up, prohibiting you from downloading emails. Your own code might even have a bug that’s causing your data to be routed improperly. In any case, it’s undesirable for your entire application to fail because of a single unanticipated error.
On the other hand, a transaction, whether occurring in software or in real life, is a series of events that need to occur in a specified sequence, leaving all participants in some predetermined state. Leaving the software world aside for a moment, let’s consider a real-world example: paying for groceries in a supermarket. In such a transaction, the following steps need to occur in the specified order:
1. You place your groceries on the counter.
2. The cashier scans each item, adding the price of the item to the running total.
3. The sum of the prices is calculated and the total cost is communicated to you.
4. You present the cashier with a credit card to pay for the groceries.
5. The cashier charges your credit card with the amount for the groceries.
6. The cashier returns the credit card to you.
7. The cashier bags your groceries.
8. You take the bag of groceries and leave the supermarket.
This seemingly mundane undertaking is actually a fairly complex orchestration of events. The events need to happen in the order specified; the cashier can’t scan your items until you’ve put them on the counter, can’t total their prices unless they’re scanned, won’t let you leave the store without paying for them, and so on. The success or failure of each event is also important. If the cashier won’t tell you the total cost of the items, you probably won’t hand over your credit card. Likewise, if your credit card is declined, the cashier is unlikely to bag your groceries (or let you leave the store with them). In this sense, the above transaction is an all-or-nothing proposition. When you walk out of the grocery store, only two states should be possible: you leave with the groceries and their monetary amount charged to your credit card, or you leave without any groceries and your credit card is uncharged.
In the first half of this chapter, we’ll examine how Mule implements exception handling. We’ll first consider the reconnection strategies to deal with problems related to connections, and then we’ll explore exception strategies, in which you’ll see how Mule lets you react when errors arise with a message involved.
In the second half, you’ll see how to add transactional properties to your Mule services. We’ll cover the two major types of transactions supported by the Java and Java EE ecosystems: single- and multiple-resource transactions. We’ll start off by examining how single-resource transactions let you operate on a single resource, such as a database or JMS broker, transactionally. You’ll then see how you can use transactions across multiple resources. As usual, we’ll examine each of these features through the lens of Prancing Donkey. You’ll see how Mule’s transactional support augments the reliability of the integration projects.
Transaction management and exception handling are related issues. The first defines, among other factors, how a task should be accomplished and retried. Exception handling defines how to react to errors, and this reaction may include retries. Sometimes both topics can overlap; at other times they can complement each other. In this chapter, you’ll learn how to always use them in your favor.
9.1. Dealing with errors
Mule’s exception handling recognizes that things in the real world can fail. It lets you plan for and react to errors that would otherwise bring your integration process to a screeching halt. You’ll find yourself using Mule’s exception-handling ability to identify and troubleshoot failures in your connectors that will be handled with reconnection strategies and in your message processors, in which exception strategies will be used to react accordingly. You’ll find that Mule exceptions are grouped into two kinds:
- System exceptions— Errors that happened when there was no message involved; for instance, during system startup or when a transport tries to establish a connection
- Messaging exceptions— Errors that happened with a message involved; this will likely happen inside a flow, when a message processor fails to accomplish its duty
The default exception strategy for messaging exceptions handles errors that occur in a flow (and a message is involved). By default, it will log the exception and Mule will continue execution. You’ll learn how to change this behavior in section 9.1.3.
The default exception strategy for system exceptions is responsible for handling transport-related exceptions such as SSL errors on an HTTPS endpoint or a connection failure on a JMS endpoint. It will notify the registered listeners and only if the exception is caused by a connection failure will it use a reconnection strategy. You’ll learn more about reconnection strategies in the next section. Although reconnection strategies can be configured, the default exception strategy for system exceptions can’t be configured.
9.1.1. Using reconnection strategies
It’s an unfortunate reality that services, servers, and remote applications are occasionally unavailable. Thankfully, however, these outages tend to be short-lived. Network routing issues, a sysadmin restarting an application, and a server rebooting all represent common scenarios that typically don’t take long to recover from. Nevertheless, such failures can have a drastic impact on applications dependent on them. In order to mitigate such failures, Mule provides reconnection strategies to dictate how connectors deal with failed connections.
Let’s imagine a scenario in which you’re connecting to a legacy system that often goes into maintenance at night or, even worse, fails at random hours. Good news: you can handle this situation with reconnection strategies.
Mule offers both a mechanism to implement custom reconnection strategies, that we’ll visit soon, and a couple of ready-to-use reconnection strategies:
- reconnect, with the use of the two attributes (count and frequency), allows configuration of how many times a reconnection should be attempted and the interval there should be between attempts.
- reconnect-forever works like reconnect, but instead of reconnecting a number of times, it will reconnect ad infinitum, waiting the number of milliseconds specified in the frequency attribute between attempts.
Both strategies share an attribute called blocking; if set to true, the Mule application message processing will halt till it’s able to reconnect to the external resource. Otherwise, Mule won’t wait to have all connectors online to process messages, and in the case of reconnection it will handle it in a separate thread. The choice depends on the scenario you’re working on. If you’re working with reliable communication like JMS, you probably can afford to have a nonblocking reconnection strategy. Otherwise, you may want to work with a blocking strategy.
Let’s find out how to use reconnection strategies by configuring a JMS connector with a reconnect element in XML in the following listing. The same can be accomplished in Mule Studio using the dialog shown in figure 9.1.
Figure 9.1. Reconnection tab for a connector in Mule Studio

Listing 9.1. Using the reconnect strategy
<jms:activemq-connector name="jmsConnector">
<reconnect count="5" frequency="1000"/>
</jms:activemq-connector>
You may realize that you set one reconnection strategy for the connector instead of setting one for inbound and another one for outbound connections. If you need separate inbound and outbound behavior, you can get it by using two different connectors, and then applying one to the inbound endpoints and the other to the outbound ones (see the next listing).
Listing 9.2. Using different strategies for inbound/outbound
<jms:activemq-connector name="jmsInboundConnector">
<reconnect-forever frequency="1000" />
</jms:activemq-connector>
<jms:activemq-connector name="jmsOutboundConnector">
<reconnect count="5" frequency="1000" />
</jms:activemq-connector>
The built-in reconnection strategies of Mule are good enough for many cases but not for everything. For instance, one of the associates of Prancing Donkey supplies an excellent barley, but their software services are less than good: their endpoints fail often and so need a restart. Sadly, their maintenance engineers are only available during working hours, so if something fails at night, the chances that a reconnection will succeed are lower.
9.1.2. Creating reconnection strategies
Thankfully, Mule offers the ability to writing custom reconnection strategies. The situation with the barley provider looks like an excellent opportunity to put them into practice. Reconnection strategies are defined by implementing the RetryPolicy interface. Listing 9.3 demonstrates a simple reconnection strategy that instructs a connector to reconnect to the failed resource, waiting a different amount of time depending on if the reconnection happens during working hours or not.
Listing 9.3. A working hours–aware retry policy


This retry policy will sleep at ![]() ; if not interrupted, it will return a PolicyStatus of OK. This informs the connector to attempt to retry again. If the thread is interrupted, a runtime exception will be thrown
; if not interrupted, it will return a PolicyStatus of OK. This informs the connector to attempt to retry again. If the thread is interrupted, a runtime exception will be thrown
![]() . In addition to returning a policyOK state, Policy-Status can also return an exhausted state. This is useful if you want to limit the amount of retry attempts to a particular resource and is demonstrated in the
next listing.
. In addition to returning a policyOK state, Policy-Status can also return an exhausted state. This is useful if you want to limit the amount of retry attempts to a particular resource and is demonstrated in the
next listing.
Beware of the legacy names
In Mule 2, reconnection strategies were called retry policies; this name mistakenly suggests that Mule will retry operations doing message redelivery. In Mule 3, the name was changed, and retry policies became officially deprecated. Nevertheless, you’ll still find it in the Mule API.
Listing 9.4. An exhaustible retry policy


The WorkingHoursAwareExaustibleRetryPolicy will attempt to connect to the remote resource only during working hours; if reconnection is issued outside of working hours,
then a PolicyStatus of exhausted is returned ![]() , along with the cause of the retry. This causes the connector to stop retrying to connect to the failed resource.
, along with the cause of the retry. This causes the connector to stop retrying to connect to the failed resource.
Before you can use either of the retry policies defined in the previous listing, you must implement a policy template. This is accomplished by extending the AbstractPolicyTemplate class. The next listing illustrates a policy template for the WorkingHoursAwareRetryPolicy.
Listing 9.5. A policy template
public class WorkingHoursAwareRetryPolicyTemplate
extends AbstractPolicyTemplate
{
int companyWorkStartHour;
int companyWorkEndHour;
int intervalInWorkingHours;
int intervalInNonWorkingHours;
TimeZone timeZone;
public RetryPolicy createRetryInstance()
{
return new WorkingHoursAwareRetryPolicy(
companyWorkStartHour, companyWorkEndHour, timeZone,
intervalInWorkingHours, intervalInNonWorkingHours);
}
public void setCompanyWorkStartHour(int companyWorkStartHour)
{
this.companyWorkStartHour = companyWorkStartHour;
}
public void setCompanyWorkEndHour(int companyWorkEndHour)
{
this.companyWorkEndHour = companyWorkEndHour;
}
public void setIntervalInWorkingHours(int intervalInWorkingHours)
{
this.intervalInWorkingHours = intervalInWorkingHours;
}
public void setIntervalInNonWorkingHours
(int intervalInNonWorkingHours)
{
this.intervalInNonWorkingHours = intervalInNonWorkingHours;
}
public void setTimeZone(TimeZone timeZone)
{
this.timeZone = timeZone;
}
You need to implement the createRetryInstance method of AbstractPolicy-Template to return an instance of the RetryPolicy you wish to use. In this case, you’ll return a WorkingHoursAwareRetryPolicy, which will cause the connector to use the logic defined in listing 9.3.
The right tool for the right job
Listing 9.4 represents a simple Java implementation of a java.util.Calendar-based retry policy. For complex scenarios you may want to use more powerful tools like the Drools Expert rules engine. Sadly, there’s no out-of-the-box support to do this in Mule. You should create your own adapter implementing RetryPolicy to delegate the logic to Drools.
Finally, to tie everything together, when you define your connector you can pass your recently created policy template using the element reconnect-custom-strategy, as shown in the next listing.
Listing 9.6. Configuring a connector with a custom strategy
<jms:activemq-connector name="jmsWithCustomReconnect">
<reconnect-custom-strategy
class=
"com.prancingdonkey.reconnect.WorkingHoursAwareRetryPolicyTemplate">
<spring:property name="companyWorkStartHour" value="9"/>
<spring:property name="companyWorkEndHour" value="18"/>
<spring:property name="intervalInWorkingHours" value="5000"/>
<spring:property name="intervalInNonWorkingHours"
value="360000000"/>
<spring:property name="timeZone"
value="$[T(TimeZone).getTimeZone('America/Los_Angeles')]"/>
</reconnect-custom-strategy>
</jms:activemq-connector>
Now you’re able to react to system exceptions caused by a connection problem. Let’s find out how you can use exception strategies to react when an error is raised with a message involved.
9.1.3. Handling exceptions
Being able to define different reactions for system exceptions caused by connection problems and for messaging exceptions lets you handle each sort of error independently. You learned how you can react to connection problems; now let’s find out how exception strategies work for situations where there are exceptions with messages involved.
You have the option of explicitly defining exception strategies in multiple places in your Mule configurations. Exception strategies can be configured on a per-flow basis. This is done by defining an exception strategy at the end of each flow definition. You can additionally define exception strategies globally; in this case, to establish the exception strategy in a flow, you’ll have to use a reference. And finally, you can also configure the default exception strategy that Mule will use when there’s no strategy configured for a flow with a problem.
Let’s start by configuring an exception strategy inside a flow. We still haven’t studied the different built-in exception strategies, but don’t worry; we’ll do so soon. In the meantime, let’s use a catch-exception-strategy that will catch and process all exceptions thrown in the flow, shown in the next listing.
Listing 9.7. A locally defined exception strategy

Here you can find one new element, the catch-exception-strategy ![]() . This element instructs the flow to respond with a String that summarizes the exception message, for any kind of error. This
approach is useful for special cases, but requires you to configure different exception strategies for flows that could reuse
exception strategies. To avoid this, you can use the global exception strategies.
. This element instructs the flow to respond with a String that summarizes the exception message, for any kind of error. This
approach is useful for special cases, but requires you to configure different exception strategies for flows that could reuse
exception strategies. To avoid this, you can use the global exception strategies.
To configure a global exception strategy, like you already learned with other message processors, two steps are required. You should first configure a global exception strategy and then put a reference in the desired flows. Let’s configure a global exception strategy, shown in the following listing.
Listing 9.8. A globally defined exception strategy

You can find two outstanding points here: At ![]() you introduce a global exception strategy, and then you reuse it at
you introduce a global exception strategy, and then you reuse it at ![]() . This is extremely useful when you want to reuse an exception strategy in a few flows. But there’s still another scenario
to cover. What happens when you need to configure an exception strategy for all (or most) of the flows? For these cases, you
can use the default exception strategy.
. This is extremely useful when you want to reuse an exception strategy in a few flows. But there’s still another scenario
to cover. What happens when you need to configure an exception strategy for all (or most) of the flows? For these cases, you
can use the default exception strategy.
The default exception strategy is configured by defining a defaultException-Strategy-ref attribute on the Mule configuration element and pointing it to the desired global exception strategy, which is configured like a regular global endpoint. Defining the default exception strategy on the configuration element will cause all flows in the Mule application with no specific exception strategy to use the defined exception strategy. Let’s revisit listing 9.8 and use the global endpoint it configures as the default exception strategy in the next listing.
Listing 9.9. Configuring the default exception strategy

The default exception strategy configured at ![]() will ensure all exceptions thrown in the flow will be handled by the catch-exception-strategy defined at
will ensure all exceptions thrown in the flow will be handled by the catch-exception-strategy defined at ![]() .
.
9.1.4. Using exception strategies
Now that you’re more comfortable with the different ways to configure an exception strategy in Mule, it’s a good moment to learn about the exception strategies Mule supports. As we mentioned before, the default exception strategy will log exceptions and move on. This is often the right degree of action to take, but sometimes you’ll want to take more elaborate measures when an exception occurs. This is particularly true in a large or distributed environment. Equally true in such an environment is the inevitability that a remote service will be unavailable. When such a service is the target of an outbound endpoint, you might want Mule to attempt to deliver the message to a different endpoint or rollback and retry. To suit your needs, Mule provides five exception strategies ready to use:
- Default exception strategy— Implicitly present by default in every flow; will log the exception and roll back the transaction.
- Catch exception strategy— Customize the reaction for any exception; will commit the transaction and so will consume the message.
- Rollback exception strategy— Customize the reaction for any exception; will roll back the transaction, hence won’t consume the message.
- Choice exception strategy— Using a Mule expression will route to one exception strategy within a set; if no exception strategy is suitable in the set, the exception will be routed to the default exception strategy.
- Reference exception strategy— Delegate the responsibility to handle exceptions to a global exception handler.
Those strategies can be found in Mule Studio in the form you can see in figure 9.2. You’re already familiar with the default and reference exception strategies. Let’s learn a little bit more about the other three strategies with a couple of examples.
Figure 9.2. Exception strategies as shown in Mule Studio’s toolbox

You recall Prancing Donkey’s shipping cost calculator from section 6.1.7. When we introduced it for the first time, we approached the error handling naïvely. This time we’ll add some more reality bites with more complex scenarios.
Since Prancing Donkey deployed the brand new shipping cost calculator, many different possible errors have been found. The first reaction of the integration architects was to return a message explaining something went wrong. They used a catch exception strategy to be able to catch the error and react to it without inducing a retry, as you can see in listing 9.10 and in figure 9.3.
Figure 9.3. Mule Studio equivalent for listing 9.10

Listing 9.10. Flow with a catch exception strategy

This approach worked as expected. The catch-exception-strategy at ![]() grabbed all the errors and created a specific response for them. But thanks to the logger at
grabbed all the errors and created a specific response for them. But thanks to the logger at ![]() , Prancing Donkey’s integration architects found that sometimes the errors were caused by an IllegalStateException. They decided to retry three times and then give up, returning another informative message to the requestor.
, Prancing Donkey’s integration architects found that sometimes the errors were caused by an IllegalStateException. They decided to retry three times and then give up, returning another informative message to the requestor.
Fortunately, Mule provides the rollback exception strategy that fits perfectly in this situation. It will use a maxRedeliveryAttempts attribute in combination with an on-redelivery-attempts-exceeded child element to accomplish the desired behavior. The problem with this is that it can only handle the IllegalStateException problem, whereas Prancing Donkey still needs to process the rest of the exceptions as they did in listing 9.10. Here the last of the exception strategies, the choice exception strategy, comes in useful.
The when attribute of the exception strategies should be a Mule expression. This will let you create complex routing without writing extra code:
- exception.causedBy(com.prancingdonkey.MyPrancingException) evaluates if the exception was caused by an instanceof the provided exception type.
- exception.causedExactlyBy(com.prancingdonkey.MyPrancingException) evaluates if the exception was caused by the type provided, and only by that type provided.
- exception.causeMatches("com.prancingdonkey.*") && !exception.causedBy(com.prancingdonkey.MyPrancingException) evaluates if the cause exception type name matches the "com.prancingdonkey.*" regex and is not caused by com.prancingdonkey.MyPrancingException.
The choice exception strategy is the router of the exception strategies: it can contain other exception strategies, routing between them by leveraging a when attribute in the child strategies. Thanks to the choice exception strategy, you can take advantage of any combination of catch and rollback exception strategies. The only limitation is that a choice exception strategy can’t contain another choice exception strategy. Let’s use it in listing 9.11 and in figure 9.4.
Figure 9.4. Mule Studio equivalent for listing 9.11

Listing 9.11. Flow with a choice exception strategy


The choice exception strategy ![]() will route between the child strategies it has. When the exception is caused by an IllegalStateException, the rollback-exception-strategy will be invoked, whereas if it’s of any other type, the catch-exception-strategy will be used. The maxRedeliveryAttempts attribute
will route between the child strategies it has. When the exception is caused by an IllegalStateException, the rollback-exception-strategy will be invoked, whereas if it’s of any other type, the catch-exception-strategy will be used. The maxRedeliveryAttempts attribute ![]() instructs the rollback-exception-strategy to restart the transaction up to three times; after that, the on-redelivery-attempts-exceeded block will be executed.
instructs the rollback-exception-strategy to restart the transaction up to three times; after that, the on-redelivery-attempts-exceeded block will be executed.
Different redelivery attempts
Some reliable transports, like JMS, have their own redelivery mechanism that can include a max redelivery limit. As this works at the transport level, this mechanism could be faster than the rollback exception strategy’s redelivery policy. If you want to rely on your transport’s redelivery policy, don’t set the maxRedeliveryAttempts attribute of the rollback-exception-strategy.
Now we’ll see how to use the built-in exception strategies. This will enable you to apply different behaviors for further processing and responses when dealing with exceptions.
9.2. Using transactions with Mule
At the beginning of this chapter, we considered a real-life transaction example. Similar scenarios are present in software applications. Updating related data in a database, for instance, usually requires that all or none of the tables be updated. If some failure occurs halfway through the database update, then the database is left in an inconsistent state. To prevent this state, you need some mechanism to roll back data that has been updated to the point of failure. This makes the database update atomic; even though a sequence of disconnected events is taking place (the updating of different tables), they’re treated as a single operation that’s either completely successful or completely rolled back.
Having atomicity allows you to make assumptions about consistency. Because the database operations are treated in a singular fashion, the database is guaranteed to be in defined states whether the transaction has completed or failed, making the operation consistent.
While a transaction is taking place, it’s important that other transactions aren’t affected. This is closely related to consistency. If another process is querying a table while the database update we discussed previously is occurring, and then the update is subsequently rolled back, the other process might read data that is now invalid. This can be avoided, for instance, by not only rolling back the failed database updates but also by locking the tables being updated. We refer to such behavior as being isolated.
Transactions must also be permanent in nature. If the cashier’s card reader tells him your card has been charged but in reality it hasn’t, then the grocery store is out the cost of your groceries. Conversely, if the cashier hides some of your groceries under the counter to take home with him after his shift, you’ve been charged for goods you haven’t received. In both cases you want to make sure the transaction has been completely applied to each resource being affected. When this is guaranteed, the transaction is referred to as durable.
These four properties—atomicity, consistency, isolation, and durability—together form the acronym ACID. This term is commonly used to discuss the transactions we’ll examine in this chapter. Such transactions can play an important role in integration scenarios; the nature of distributed data and systems often necessitates their use. Unfortunately, dealing with transactions programmatically can be esoteric and error prone. Mule, thankfully, makes it easy to declare transactional properties on your endpoints. You’ll see in this chapter how to add transactional properties to your Mule services. We’ll cover the two major types of transactions supported by the Java and Java EE ecosystems: single- and multiple-resource transactions. We’ll start off by examining how single-resource transactions let you operate on a single resource, such as a database or JMS broker, transactionally. You’ll then see how you can use transactions across multiple resources. Finally, we’ll look at how you can use exception strategies in conjunction with transactions to provide custom rollback and commit behavior. As usual, we’ll examine each of these features through the lens of Prancing Donkey. You’ll see how Mule’s transactional support augments the reliability of the integration projects.
9.2.1. Single-resource transaction
Let’s start off by examining how to operate on a single resource transactionally with Mule. A single-resource transaction implies a set of operations executed on a single provider, such as a particular database or JMS broker. In the context of Mule, transactions of this sort will occur on or across endpoints using the same connector. For instance, you might use a single-resource JMS transaction on a JMS inbound endpoint or a single-resource JDBC transaction on a JDBC outbound endpoint. Single-resource transactions can also be used across inbound and outbound endpoints, provided the underlying connector is the same. You could, for instance, accept a JMS message on an inbound endpoint and send the message to multiple JMS queues using a static recipient list on an outbound endpoint. Assuming the queues involved were all hosted on the same JMS broker, a failure in sending the message to one of the remote JMS queues could trigger a rollback of the entire operation, up to and including the message being received on the inbound endpoint.
In this section, we’ll start off by looking at how to operate on JDBC endpoints transactionally. We’ll then see how to use these same techniques to consume and send JMS messages in transactions.
Using JDBC endpoints transactionally
Being able to operate transactionally against a database is critical for many applications. The nature of relational databases usually means that data for a single business entity is stored across numerous tables joined to each other with foreign key references. When this data is updated, care must be taken that every required table is updated, or the update doesn’t happen. Anything else could leave the data in an inconsistent state. Implicit transactional behavior can also be required of inserts to a single table. Perhaps you want a group of insert statements to occur atomically to ensure that selects against the table are consistent.
Prancing Donkey makes extensive use of a relational databases for its day-to-day operations. Suppose that recently Prancing Donkey’s operations team has deployed a performance monitoring application to run against their client’s web applications. This application periodically runs a series of tests against a client’s website and writes the results of the tests, represented as XML, to a file. The contents of this file are then sent at a certain interval to a JMS topic for further processing.
Mule is being used to accept this data and persist it to Prancing Donkey’s monitoring database. The payload of these messages must be persisted to a database in an all-or-nothing manner. If any of the row inserts fail, then the entire transaction should be rolled back. This ensures the monitoring data for a given client is consistent when it’s queued by a web-facing analytics engine. Let’s see how to use a JDBC outbound endpoint to enforce this behavior. The following listing illustrates how Prancing Donkey is accomplishing this.
MySQL and transactions
For transactions with MySQL to work properly, they must be supported by an underlying engine that supports transactions, such as InnoDB.
Listing 9.12. Using a JDBC outbound endpoint transactionally


The insert statement is declared at ![]() . It inserts data into the PERF_METRICS table using data from the map populated by the URLMetricsComponent. The URLMetrics-Component builds this map from the JMS message received on the monitoring.performance topic. The insert statement is then executed
. It inserts data into the PERF_METRICS table using data from the map populated by the URLMetricsComponent. The URLMetrics-Component builds this map from the JMS message received on the monitoring.performance topic. The insert statement is then executed ![]() .
.
The action parameter ![]() tells Mule how to initiate the transactional behavior. The ALWAYS_BEGIN value here indicates that the inserts should begin in a new transaction, independent of any other transactions that might
be present. Table 9.1 lists the valid action values for a Mule transaction.
tells Mule how to initiate the transactional behavior. The ALWAYS_BEGIN value here indicates that the inserts should begin in a new transaction, independent of any other transactions that might
be present. Table 9.1 lists the valid action values for a Mule transaction.
Table 9.1. Available options for configuring a transaction action
|
Action value |
Description |
|---|---|
| NONE | Never participate in a transaction, and commit any previously existing transaction. |
| NOT_SUPPORTED | Will execute within an existing transaction context if it’s present but without joining it, because there’s no transactional resource to join. |
| ALWAYS_BEGIN | Always start a new transaction, committing any previously existing transaction. |
| BEGIN_OR_JOIN | If there is an existing transaction, join that transaction. If not, start a new transaction. |
| ALWAYS_JOIN | Always expect and join an existing transaction. Throw an exception if no previous transaction exists. |
| JOIN_IF_POSSIBLE | Join an existing transaction if one exists. If no transaction exists, run nontransactionally. |
Because the JDBC outbound endpoint in listing 9.12 isn’t participating in any other transaction, you naturally use ALWAYS_BEGIN to start a new transaction for the insert.
Now that you’ve seen how transactions work with the JDBC transport, let’s take a look at how you can send and receive JMS messages transactionally.
Using JMS endpoints transactionally
JMS messaging can also be performed transactionally. Transactions on JMS inbound endpoints ensure that JMS messages are received successfully. Messages that aren’t received successfully are rolled back. A rollback in this case means the message is destroyed, causing the JMS provider to attempt redelivery of the message. A transaction on a JMS outbound endpoint indicates that the message was sent successfully. If there was a failure, the message is rolled back and redelivery is attempted. As you’ll see shortly, JMS transactions can be used in conjunction with the all router, allowing multiple messages to be dispatched in the same transaction. First, let’s see how to accept JMS messages transactionally.
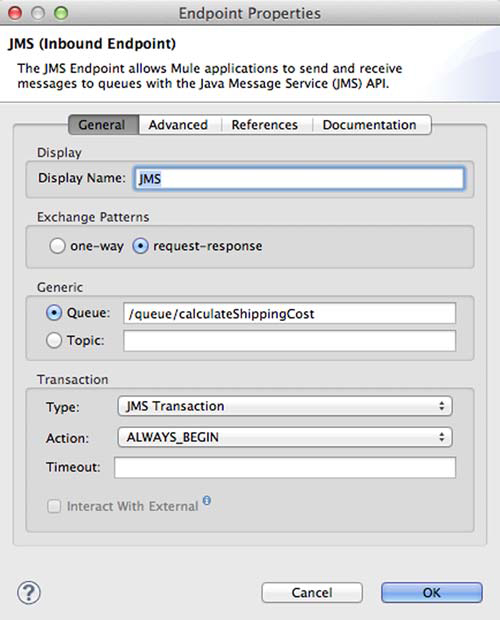
Given that Prancing Donkey is using this service in a production manner for important data (such as messages containing order or provisioning information), instead of passing the message to the console for display, they’re instead forwarding the message to another JMS queue for further processing. In this case, Prancing Donkey wants to be sure the messages aren’t lost, either by a failure occurring at the inbound endpoint or a failure occurring on an outbound endpoint. Listing 9.13 shows a modified configuration that adds transactional semantics to the inbound and outbound endpoints, ensuring that at each step the message processing is successful, and if not, is rolled back. Figure 9.5 represents an JMS endpoint using transactions in Mule Studio.
Figure 9.5. JMS endpoint using transactions
Listing 9.13. Accepting and sending JMS messages transactionally

Messages are received off the messages queue ![]() . If a message has a payload that matches the regular expression defined by the regex-filter, it’s passed to the component
. If a message has a payload that matches the regular expression defined by the regex-filter, it’s passed to the component ![]() . The JMS transaction is defined at
. The JMS transaction is defined at ![]() , where a new transaction is created for every message received. The transaction will span receiving the message on the inbound
endpoint and its processing by the Spring object. When the message reaches the JMS outbound endpoint, the ALWAYS_BEGIN action of the JMS transaction defined at
, where a new transaction is created for every message received. The transaction will span receiving the message on the inbound
endpoint and its processing by the Spring object. When the message reaches the JMS outbound endpoint, the ALWAYS_BEGIN action of the JMS transaction defined at ![]() will cause the previous transaction started at
will cause the previous transaction started at ![]() to commit and a new transaction to begin.
to commit and a new transaction to begin.
Failures in the component are handled differently. Unless overridden by the methods discussed previously in this chapter, Mule will use the default exception strategy to process the exception thrown by the component. Such a failure will, by default, trigger a rollback on the transaction. You’ll see later in this chapter how you can override this behavior and trigger a commit based on the type of exception thrown by a component.
Once the message is passed to outbound endpoint, it’s sent to the processed-messages queue. In listing 9.13, the transaction configured at ![]() will ensure this message is sent in a new transaction. If the message can’t be sent, the transaction won’t begin and the
message will be lost. To solve this problem, let’s see how you can have the outbound endpoint join in the transaction created
at
will ensure this message is sent in a new transaction. If the message can’t be sent, the transaction won’t begin and the
message will be lost. To solve this problem, let’s see how you can have the outbound endpoint join in the transaction created
at ![]() . Then a failure to start the transaction on the outbound endpoint will trigger a rollback up to the beginning of the transaction
created at
. Then a failure to start the transaction on the outbound endpoint will trigger a rollback up to the beginning of the transaction
created at ![]() . Listing 9.14 illustrates how to do this.
. Listing 9.14 illustrates how to do this.
Listing 9.14. Using ALWAYS_JOIN to join in an existing transaction

By changing the transaction action to ALWAYS_JOIN ![]() , you ensure that the sending of the JMS message will always join a preexisting transaction. In the event the message can’t be sent, the transaction will roll back to where it began, at
, you ensure that the sending of the JMS message will always join a preexisting transaction. In the event the message can’t be sent, the transaction will roll back to where it began, at ![]() , and the message will be pushed back to the JMS provider for subsequent redelivery.
, and the message will be pushed back to the JMS provider for subsequent redelivery.
It’s also possible to send multiple messages transactionally. Using an all router with JMS outbound endpoints along with a JMS transaction will cause all the messages sent by the JMS outbound endpoints to either all be committed or all be rolled back atomically. Let’s see how this functionality is useful for Prancing Donkey.
Prancing Donkey currently collects various real-time analytical data about its customer’s web applications. Web application response times, network metrics, and billing data are all collected from Prancing Donkey’s data centers and published to JMS queues for processing by Prancing Donkey’s Mule instances. This data must ultimately be processed and fed into Prancing Donkey’s operational database as well as its data warehouse. In order to decouple the operational database and the data warehousing, your team has decided to republish the data in an appropriate format for each destination. The resultant data is then placed on a dedicated JMS queue where it’s consumed and saved. Because the operational and data-warehouse data must be in sync with each other, it makes sense to group the publishing of this data atomically in a transaction. Figure 9.6 illustrates this.
Figure 9.6. Prancing Donkey’s approach for decoupled data management

The following listing shows the corresponding Mule configuration.
Listing 9.15. Using the multicasting router transactionally

The JMS endpoints defined at ![]() will accept messages from each analytics provider transactionally. This data will be processed by the analyticsService Spring object configured at
will accept messages from each analytics provider transactionally. This data will be processed by the analyticsService Spring object configured at ![]() . If there’s a failure on the JMS endpoints, the transaction will be rolled back. Exceptions thrown by analyticsService will be logged but will have no impact on the transaction. The processed message will then be passed to the all router defined
at
. If there’s a failure on the JMS endpoints, the transaction will be rolled back. Exceptions thrown by analyticsService will be logged but will have no impact on the transaction. The processed message will then be passed to the all router defined
at ![]() . The JMS transactions defined at
. The JMS transactions defined at ![]() and
and ![]() will ensure that the message is sent to both JMS queues successfully. If there’s a failure on either queue, then the transactions
won’t begin and the message will be lost. The timeout value defined at
will ensure that the message is sent to both JMS queues successfully. If there’s a failure on either queue, then the transactions
won’t begin and the message will be lost. The timeout value defined at ![]() specifies how many milliseconds to wait before rolling back the transaction.
specifies how many milliseconds to wait before rolling back the transaction.
Message Redelivery in JMS
You might be wondering how often and for how long message redelivery is attempted. The JMSTimeToLive header property defines how long a message exists until it’s destroyed by the JMS provider. The redelivery fields are dependent on your JMS provider. These can be important properties to reference when tuning and troubleshooting JMS and Mule performance.
In order to ensure messages aren’t lost by such a failure, you can make this entire message flow transactional, from JMS inbound endpoints to JMS outbound endpoints. The next listing shows how to do this.
Listing 9.16. Making an entire message flow transactional

You change the transaction action from ALWAYS_BEGIN to ALWAYS_JOIN at ![]() . Now a failure on either queue in the all router will cause the transaction to roll back up to the message reception on the
inbound endpoint. Such a configuration will make the transaction resilient against a failure on one of the queues. For instance,
if Mule doesn’t have the appropriate rights to access the data-warehouse queue, then the entire operation will roll back to message reception on the JMS inbound endpoint.
. Now a failure on either queue in the all router will cause the transaction to roll back up to the message reception on the
inbound endpoint. Such a configuration will make the transaction resilient against a failure on one of the queues. For instance,
if Mule doesn’t have the appropriate rights to access the data-warehouse queue, then the entire operation will roll back to message reception on the JMS inbound endpoint.
The VM transport can also be used transactionally. For instance, to begin a new VM transaction instead of a JMS transaction in listing 9.16, you would use the vm:transaction element, as follows:
<all>
<vm:outbound-endpoint path="operational.database">
<vm:transaction action="ALWAYS_JOIN" />
</vm:outbound-endpoint>
<vm:outbound-endpoint path="data.warehouse">
<vm:transaction action="ALWAYS_JOIN" />
</vm:outbound-endpoint>
</all>
A transacted VM endpoint shows more reliability than a nontransacted one, but still can’t be considered a completely reliable transport as message loss may occur if the Mule instance goes down. But this isn’t true if you’re using a clustered Mule (only available with Mule Enterprise Edition; see appendix C) where the messages are backed by other nodes in the cluster. You could also improve reliability by using a reliability pattern, as discussed in the sidebar “Implementing a reliability pattern” in section 9.2.2.
Transactions, by their nature, are synchronous operations. As such, Mule endpoints participating in transactions will operate synchronously. In the previous listing, the JMS inbound endpoint that receives a JMS message will block until the transaction is either committed or rolled back on the outbound endpoint. Keep this in mind when structuring transactions in your services.
In this section, you saw how to use transactions with a single resource, such as a single database or JMS provider. It’s also possible to run transactions across multiple resources, such as two databases or a database and a JMS provider. Let’s investigate Mule’s support for that now.
In 2007, Michael Nygard’s book Release It! (www.pragprog.com/titles/mnee/release-it) presented the Decoupling Middleware pattern to decouple remote service invocation, in both space and time, using a messaging broker. This allows you to use the features of the messaging broker, such as durability and delayed redelivery, to improve the resiliency of communication with a remote service.
Let’s consider some of the benefits of this indirection:
- The service can be taken down/brought up without fear of losing messages; they’ll queue on the broker and will be delivered once the service is brought back up.
- The service can be scaled horizontally by adding additional instances (competing consumption off the queue).
- Messages can be reordered based on priority and sent to the remote service.
- Requests can be resubmitted in the event of a failure.
The last point is particularly important. It’s common to encounter transient errors when integrating with remote services, particularly web-based ones. These errors are usually recoverable after a certain amount of time. Mule does have support for message-oriented middleware protocols like JMS or AMQP, and it also has support for transactions, as you learned in the first half of this chapter. This makes Mule a perfect citizen for decoupled systems, although there could be a certain level of feature collision between Mule and your decoupling middleware, depending on the middleware you’re using.
In section 9.1.3, you learned how to use the rollback-exception-strategy. It triggers Mule’s capacity to redeliver failed messages. You also learned how to use the maxRedeliveryAttempts attribute and the on-redelivery-attempts-exceeded child element of the same exception strategy that incidentally represents another one of Michael’s patterns: the “circuit-breaker” (http://en.wikipedia.org/wiki/Circuit_breaker_design_pattern).
Your decoupling middleware, usually present in the form of a JMS broker, is probably able to redeliver and circuit break when necessary. You can use redelivery in conjunction with transactions to periodically re-attempt the failed request. HornetQ supports this by configuring address-settings on the queue. The following addresssetting for exampleQueue specifies 12 redelivery attempts with a five-minute interval between each request:
<address-setting
match="jms.queue.exampleQueue">
<max-delivery-attempts>12</max-delivery-attempts>
<redelivery-delay>300000</redelivery-delay>
</address-setting>
9.2.2. Transactions against multiple resources
Performing transactions on a single resource is appropriate if the operations to be conducted transactionally all use the same connector. You saw examples of this in the last section, in which we showed how you can use the JDBC and JMS transports transactionally. But what if the operations you wish to group atomically span more than one resource? Perhaps you need to accept a JMS message on an inbound endpoint, process it with a component, and then save the message payload to a database with a JDBC outbound endpoint. You want to make this operation transactional so that failures in either the JMS endpoint or the JDBC endpoint trigger a rollback of the entire operation. Figure 9.7 illustrates this scenario.
Figure 9.7. Performing a transaction across multiple resources

The XA standard is a distributed transaction protocol designed to meet this need. For resources that support XA transactions, like many JDBC drivers and JMS providers, this is possible through the use of the Java Transaction API. An XA transaction uses the two-phase commit (2PC) protocol to ensure that all participants in the transaction commit or roll back. During the first phase of the 2PC, the transaction manager polls each participant in the transaction and makes sure each is ready to commit the transaction. In the second phase of the 2PC, if any of the participants indicates that its portion of the transaction can’t be committed, the transaction manager instructs each participant to roll back. If each participant can commit the transaction, the transaction manager instructs them each to do so, and the transaction is completed.
1.5 phase transactions with Mule EE
The Mule Enterprise Edition provides another multiple resource transaction mechanism using a 1.5 phase commit. This is faster than a two-phase commit, but is less reliable and also supports fewer transports. For more information on this system, refer to the Mule documentation: http://mng.bz/i1X8.
To take advantage of XA transactions, use of a specific driver is often required. JMS and JDBC providers usually provide connection factories or data sources prefixed with XA to differentiate them. You’ll need to consult the documentation for your provider and see what these differences are.
XA transactions can be complex beasts. As we mentioned, you usually need to use different JDBC or JMS drivers that specifically have XA support. Resources in XA transactions can also make decisions about rolling back a transaction outside the scope of the transaction manager. These scenarios, often caused by locking or network issues, cause HeuristicExceptions to be thrown. You should be aware of these exceptions and configure your exception strategies accordingly. Finally, XA transactions can also introduce scalability issues when locking occurs in the XA participants. Be aware of this when deciding to use XA transactions in your projects.
Best practice
Exercise caution when using XA transactions as they can have adverse scalability, complexity, and performance impacts on your projects.
You’ll see in this section how Mule uses the Java Transaction API (JTA) to allow you to declaratively configure such transactions via XML. We’ll start off by looking at how to perform standalone XA transactions using JBoss transactions. We’ll then see how to access a transaction manager when running Mule embedded in an application running in a container, such as an application server or servlet container.
Spanning multiple resources with JBossTS
It used to be the case that running JTA transactions required the use of a Java EE application server, like JBoss AS or WebLogic. Thankfully, there are now standalone JTA implementations that don’t require this amount of overhead. One such implementation, which is supported out of the box by Mule, is JBossTS. Let’s see how you can use Mule’s JBossTS support to improve Prancing Donkey’s data warehousing service.
You saw in listing 9.15 how Prancing Donkey was transactionally receiving and republishing analytical data using JMS inbound and outbound endpoints. Two separate transactions were occurring in this scenario. The first transaction was spanning the message reception and subsequent component processing. The second transaction was spanning the publishing of each JMS message to the queues. This approach was taken to decouple message reception from message publication. The JMS inbound endpoints would be able to transactionally receive and process JMS messages independently of messages being successfully consumed by the queues defined in the outbound endpoints.
This approach is robust enough if the providers only care that their JMS messages are received by Mule. It’s less appropriate if the provider needs to be sure whether or not the entire action was successful. This might be the case for the data on the billing endpoint. In this case a provider wants to be sure that the billing data is saved to the operational database and the data warehouse successfully. To support this, Prancing Donkey has added another service that’s dedicated to receiving billing data. Figure 9.8 illustrates the new service, which forgoes the JMS outbound endpoints and will write to the database and data warehouse directly.
Figure 9.8. Wrapping billing data reception into a single transaction

Assuming Prancing Donkey’s JMS provider and its JDBC drivers for the database and data warehouse support XA transactions, you can use Mule’s JBossTS support to wrap this entire operation in a single transaction. The next listing illustrates how Prancing Donkey has accomplished this.
Listing 9.17. Sending outbound messages to list of endpoints using an XA transaction


You start off by defining an ActiveMQ connector that supports XA transactions ![]() . Because the database and data warehouse require separate data sources, you need to configure two JDBC connectors to reference
each data source. These are configured at
. Because the database and data warehouse require separate data sources, you need to configure two JDBC connectors to reference
each data source. These are configured at ![]() and
and ![]() . The referenced data sources for both of these connectors, configured in Spring, should support XA transactions. You specify
that you’re using JBossTS to manage the XA transactions
. The referenced data sources for both of these connectors, configured in Spring, should support XA transactions. You specify
that you’re using JBossTS to manage the XA transactions ![]() . When a JMS message is received on the inbound endpoint, a new XA transaction is started by the ALWAYS_BEGIN value given to the xa-transaction
. When a JMS message is received on the inbound endpoint, a new XA transaction is started by the ALWAYS_BEGIN value given to the xa-transaction ![]() . The message is processed by the component and sent to the two following outbound endpoints.
. The message is processed by the component and sent to the two following outbound endpoints.
ALWAYS_BEGIN and Previous Transactions
If there’s a current transaction running when using ALWAYS_BEGIN in an XA context, that transaction will be suspended and a new transaction started. Once this new transaction has completed, the previous transaction will be resumed.
The xa-transaction configuration ![]() has an action of ALWAYS_JOIN. This means it’s expecting a previous XA transaction to be open and will join to it (as opposed to committing the previous
transaction and starting a new one). The message will then be written to both JDBC outbound endpoints. A failure in either
the JMS message reception or either of the JDBC outbound endpoints will trigger the XA transaction to roll back. This will
trickle back up to the JMS inbound endpoint and cause the JMS provider to engage in redelivery of the message, using the semantics
we discussed for JMS single-resource transactions.
has an action of ALWAYS_JOIN. This means it’s expecting a previous XA transaction to be open and will join to it (as opposed to committing the previous
transaction and starting a new one). The message will then be written to both JDBC outbound endpoints. A failure in either
the JMS message reception or either of the JDBC outbound endpoints will trigger the XA transaction to roll back. This will
trickle back up to the JMS inbound endpoint and cause the JMS provider to engage in redelivery of the message, using the semantics
we discussed for JMS single-resource transactions.
Let’s now take a look at how Prancing Donkey could modify this configuration to run in one of their application servers.
Using XA transactions in a container
If you’re running Mule embedded in an application that’s deployed in a container, such as an application server or servlet container, you have the option to use the container’s JTA implementation (if one exists). As we mentioned previously, many of the popular Java EE application servers ship with JTA implementations. Mule facilitates using these implementations by providing a *-transaction-manager configuration element. This lets you specify a LookupFactory to locate the appropriate JTA transaction manager for your environment. Table 9.2 lists the supported application servers along with their associated configuration elements.
Table 9.2. Transaction manager lookup factories
|
Application server |
Configuration element |
|---|---|
| JBoss AS | <jboss-transaction-manager/> |
| JRun | <jrun-transaction-manager/> |
| Resin | <resin-transaction-manager/> |
| WebLogic | <weblogic-transaction-manager/> |
| WebSphere | <websphere-transaction-manager/> |
Listing 9.17 assumed we were running Mule standalone and as such were leveraging JBossTS outside of any JBoss AS context. Let’s now assume that the Mule configuration in listing 9.17 is running as a WAR application inside Resin. To use Resin’s JTA implementation, you’d replace the jboss-transaction-manager element with Resin’s, as illustrated in the next listing.
Listing 9.18. Using an application server’s transaction manager for XA
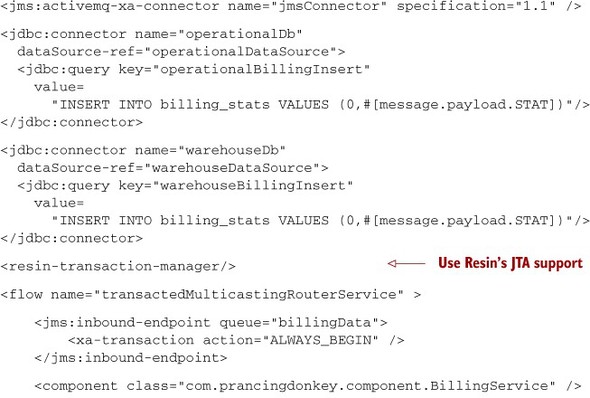

If you need access to a JTA provider that isn’t explicitly supported by Mule, you can use the jndi-transaction-manager. This allows you to specify the JNDI location of a JTA implementation for Mule to use. For instance, to access a JTA implementation with the JNDI name of java:/TransactionManager, you’d use the following transaction-manager configuration:
<jndi-transaction-manager jndiName="java:/TransactionManager"/>
By using Mule’s support for single and multiple transactions in combination with transactional middleware like JMS or JDBC, you can guarantee reliable processing of messages. The messages might be processed correctly, retried, or even fail (informing the requester), but they will never be lost.
But reliable middlewares isn’t always the case. Often you’ll find yourself in situations in which messages are received through an unreliable transport such as HTTP. In this scenario, when you still want to push the reliability to the limit, even if you have to use an unreliable transport, you’ll usually apply a reliability pattern.
You can implement a reliability pattern by coupling with a reliable transport in two phases: the reliable acquisition phase and the application logic phase (see figure 9.9).
Figure 9.9. Reliability pattern for HTTP

Following this design, the reception of the message is placed in the reliable acquisition phase, and it will take the message and try to queue it in a reliable transport. The success or the failure of this process will be reported back to the requestor so the whole operation can be retried in case of error. If the message is accepted with success, the requestor will know for sure that the message won’t be lost.
The reliable transport can vary—the most common scenario will include a JMS broker. Nevertheless, if you have a Mule HA cluster (not available in the Community Edition), a VM transport can well be a favorable solution. In the following listing, you can find an implementation of this pattern using JMS.
Listing 9.19. Implementing a JMS reliability pattern

9.2.3. Transaction demarcation
Transactions can be created on inbound endpoints or outbound endpoints. When used on inbound endpoints, the started transaction can be leveraged by the subsequent endpoints. For instance, you can read a database on a JDBC inbound endpoint and on the same transaction perform two different inserts. If one of the inserts fails, the whole transaction will be rolled back. You can see this behavior in figure 9.10.
Figure 9.10. Using transactions created on inbound endpoints

You can use transactions on outbound endpoints to join, commit, or refuse an already created transaction. You can’t, however, create a transaction in an outbound endpoint that’s intended to be used again later in Mule. If you create a new transaction in an outbound endpoint, the effect may vary on the different transports, but the typical result will be that the previous transaction will be committed and the requested action will be performed by itself transactionally, as you can see in figure 9.11.
Figure 9.11. Creating transactions on outbound endpoints

What happens when you want to call transactionally different endpoints within a transaction that’s not created in an inbound endpoint? To accomplish this, you’ll have to do transaction demarcation. It will let you scope a group of elements that should be executed inside a transaction, as shown in figure 9.12.
Figure 9.12. Using transaction demarcation

Transaction demarcation is established in Mule flows by nesting the Mule logic you want to be transactional inside one of the available transaction demarcators shown in table 9.3.
Table 9.3. Transaction demarcation elements
|
Demarcation type |
Description |
|---|---|
| transactional | Also known as single-resource transaction demarcation. Establishes a transaction for the first resource type found. |
| ee:xa-transactional | Uses a distributed transaction for all of the resource types found. Only available in the Mule Enterprise Edition. |
| ee:multi-transactional | Starts multiple transactions for each of the resource types found. Only available in the Mule Enterprise Edition. |
The usage of the transactional demarcators couldn’t be simpler. You have to wrap the elements you want to use transactionally within the element:

Here you set a single resource transaction using the transactional element ![]() . Mule will find the first resource, in this case a JMS endpoint
. Mule will find the first resource, in this case a JMS endpoint ![]() , and will set a transaction for it.
, and will set a transaction for it.
This raises a question: If this is a single-resource transaction, can you mix and match resources? You can mix resources, but you should explicitly specify that the transactions shouldn’t be used in the nonprimary resources. If you do need to have all of them in the same transaction, you’ll have to use the enterprise transaction demarcators specified in table 9.3. Let’s add a VM endpoint to the previous single-resource transaction example:

You specify NOT_SUPPORTED for the VM outbound endpoint ![]() , and therefore you leave it outside the transaction.
, and therefore you leave it outside the transaction.
By default, transaction demarcators will always begin a transaction. You could also instruct the element to join the transaction if it already exists. This is handy when using subflows in combination with demarcators:
<flow name="transactionalEntryPoint">
<jms:inbound-endpoint queue="orders">
<jms:transaction action="ALWAYS_BEGIN"/>
</jms:inbound-endpoint>
<flow-ref name="transactionalFlow"/>
</flow>
<flow name="nonTransactionalEntry">
<vm:inbound-endpoint path="nonTransactional.in"/>
<flow-ref name="transactionalFlow"/>
</flow>
<subflow name="transactionalFlow">
<transactional action="BEGIN_OR_JOIN">
<jms:outbound-endpoint queue="billingOrders"/>
<jms:outbound-endpoint queue="productionOrders"/>
</transactional>
</subflow>
Finally, we should note that transactional demarcators also support the use of exception handlers in the same fashion you learned at the beginning of this chapter. For instance, let’s say that you want to log a message when the transaction goes wrong. You can do that by adding a rollback-exception-strategy to the transactional element and including a logger in it:
<subflow name="transactionalFlowWithLogger">
<transactional action="BEGIN_OR_JOIN">
<jms:outbound-endpoint queue="billingOrders"/>
<jms:outbound-endpoint queue="productionOrders"/>
<rollback-exception-strategy>
<logger message="Problem in the transaction!" />
</rollback-exception-strategy>
</transactional>
</subflow>
9.3. Summary
In this chapter, we investigated Mule’s error-handling capabilities. You saw how to use reconnection strategies to define how errors are handled when they’re related to reconnection problems. You then saw how to use exception strategies to manage what happens after an exception occurs with a message involved. We then turned our attention to Mule’s transaction support.
Transactions play a critical role when grouping otherwise distinct operations together atomically. They can be indispensable in an integration scenario, in which the nature of such operations is often distinct. You saw in this chapter how Mule makes this potentially difficult task straightforward. By making minor modifications to an endpoint’s configuration, a range of transactional behavior can be enabled. This behavior can be used with single-resource transactions or, by using Mule’s JTA support, with transactions using multiple resources. Mule allows exception strategies to partake in the transactional flow by committing or rolling back a transaction based on the exception thrown. This, too, is easily configurable by modifying an exception strategy’s XML configuration.
In the next chapter, we’ll discuss another aspect crucial to Mule: security.