
Before applying our multilayer perceptron to understand fluctuations in the currency market exchanges, let's get acquainted with some of the key learning parameters introduced in the first section.
The purpose of the first exercise is to evaluate the impact of the learning rate, ![]() , on the convergence of the training epoch, as measured by the sum of the squared errors of all output variables. The observations
, on the convergence of the training epoch, as measured by the sum of the squared errors of all output variables. The observations x (with respect to the labeled output, y) are synthetically generated using several noisy patterns: functions f1, f2, and noise, as follows:
val noise = () => NOISE_RATIO*Random.nextDouble val f1 = (x: Double) => x*(1.0 + noise()) val f2 = (x: Double) => x*x*(1.0 + noise()) def vec1(x: Double): DblVector = Array[Double](f1(x), noise(), f2(x), noise()) def vec2(x: Double): DblVector = Array[Double](noise(), noise()) val x = XTSeries[DblVector](Array.tabulate(TEST_SIZE)(vec1(_))) val y = XTSeries[DblVector](Array.tabulate(TEST_SIZE)(vec2(_)))
The x and y values are normalized [0, 1]. The test is run with a sample of size TEST_SIZE data points over a maximum of 250 epochs, a single hidden layer of five neurons with no softmax transformation and the following MLP parameters:
val NUM_EPOCHS = 250; val EPS = 1.0e-4 val HIDDENLAYER = Array[Int](5) val ALPHA = 0.9; val TEST_SIZE = 40 val features = XTSeries.normalize(x).get val labels = XTSeries.normalize(y).get.toArray val config = MLPConfig(ALPHA, _eta, SIZE_HIDDEN_LAYER, NUM_EPOCHS, EPS) implicit val mlpObjective = new MLP.MLPBinClassifier val mlp = MLP[Double](config, features, labels)
The objective of the algorithm, mlpObjective, has to be implicitly defined prior to the instantiation of the MLP class.
The test is performed with a different learning rate, eta. For clarity's sake, the graph displays the sum of squared errors for the first 22 epochs.

Impact of the learning rate on the MLP training
The chart illustrates that the MLP model training converges a lot faster with a larger value of learning rate. You need to keep in mind, however, that a very steep learning rate may lock the training process into a local minimum for the sum of squared errors generating weights with lesser accuracy. The same configuration parameters are used to evaluate the impact of the momentum factor on the convergence of the gradient descent algorithm.
Let's quantify the impact of the momentum factor, ![]() , on the convergence of the training process toward an optimal model (synapse weights). The total sum of squared errors for the entire time series is plotted for the first five epochs in the following graph:
, on the convergence of the training process toward an optimal model (synapse weights). The total sum of squared errors for the entire time series is plotted for the first five epochs in the following graph:

Impact of the momentum factor on the MLP training
The graph shows that the rate the sum of squared errors declines as the momentum factor increases. In other words, the momentum factor has a positive although limited impact on the convergence of the gradient descent.
Let's apply our newfound knowledge regarding neural networks and the classification of variables, that impact the exchange rate of certain currency.
Neural networks have been used in financial applications from risk management in mortgage applications and hedging strategies for commodities pricing, to predictive modeling of the financial markets [9:14].
The objective of the test case is to understand the correlation factors between the exchange rate of some currencies, the spot price of gold and the S&P 500 index. For this exercise, we will use the following exchange-traded funds (ETFs) as proxies for exchange rate of currencies:
- FXA: Rate of an Australian dollar in US dollar
- FXB: Rate of a British pound in US dollar
- FXE: Rate of an Euro in US dollar
- FXC: Rate of a Canadian dollar in US dollar
- FXF: Rate of a Swiss franc in US dollar
- FXY: Rate of a Japanese yen in US dollar
- CYB: Rate of a Chinese yuan in US dollar
- SPY: S&P 500 index
- GLD: The price of gold in US dollar
Practically, the problem to solve is to extract one or more regressive models that link one ETFs y with a basket of other ETFs {xi} y=f(xi). For example, is there a relation between the exchange rate of the Japanese yen (FXY) and a combination of the spot price for gold (GLD), exchange rate of the Euro in US dollar (FXE) and the exchange rate of the Australian dollar in US dollar (FXA), and so on? If so, the regression f will be defined as FXY = f (GLD, FXE, FXA).
The following two charts visualize the fluctuation between currencies over a period of two and a half years. The first chart displays an initial group of potentially correlated ETFs:

An example of correlated currency-based ETFs
The second chart displays another group of currency-related ETFs that shares a similar price action behavior. Neural networks do not provide any analytical representation of their internal reasoning; therefore, a visual correlation can be extremely useful to novice engineers in validating their models.

An example of correlated currency-based ETFs
A very simple approach for finding any correlation between the movement of the currency exchange rates and the gold spot price, is to select one ticker symbol as the target and a subset of other currency-based ETFs as features.
Let's consider the following problem: finding the correlation between the price of FXE and a range of currencies FXB, CYB, FXA, and FXC, as illustrated in the following diagram:

The mechanism to generate features from ticker symbols
The first step is to define the configuration parameter for the MLP classifier, is as follows:
val path = "resources/data/chap9/"
val ALPHA = 0.5; val ETA = 0.03
val NUM_EPOCHS = 250; val EPS = 1.0e-6
var hidLayers = Array[Int](7, 7) //1
var config = MLPConfig(ALPHA, ETA, hidLayers, NUM_EPOCHS, EPS)Besides the learning parameters, the network is initialized with two configurations:
- One hidden layer with four nodes
- Two hidden layers of four neurons each (line
1)
Next, let's create the search space of the prices of all the ETFs used in the analysis:
val symbols = Array[String]("FXE", "FXA", "SPY", "GLD", "FXB", "FXF", "FXC", "FXY", "CYB") //2
The closing prices of all the ETFs over a period of three years are extracted from the Google Financial tables, using the GoogleFinancials extractor (line 3) for a basket of ETFs (line 2):
val prices = symbols.map(s =>DataSource(s"$path$s.csv",true)) .map( _ |> GoogleFinancials.close) //3 .map( _.toArray)
The next step consists of implementing the mechanism to extract the target and the features from a basket of ETFs, or studies introduced in the previous paragraph. Let's consider the following study as the list of ETF ticker symbols (line 4):
val study = Array[String]("FXE", "FXF", "FXB", "CYB") //4
The first element of the study, FXE, is the labeled output; the remaining three elements are observed features. For this study, the network architecture has three input variables {FXF, FXB, CYB} and one output variable FXE:
val obs = study.map(s =>index.get(s).get).map( prices( _ )) //5 val features = obs.drop(1).transpose //6 val target = Array[DblVector](obs(0)).transpose //7
The set of observations is built using an index (line 5). By convention, the first observation is selected as the label data and the remaining studies as the features for training. As the observations are loaded as an array of time series, the time features of series is computed through transpose (line 6). The single output variable, target, has to be converted into a matrix before transposition (line 7).
Ultimately, the model is built through instantiation of the MLP class:
val THRESHOLD = 0.08 implicit val mlpObjective = new MLP. MLPBinClassifier val mlp = MLP[Double](config, features, target) mlp.accuracy(THRESHOLD)
The objective type, mlpObjective, is implicitly defined as an MLP binary classifier, MLPBinClassifier. The square root of the sum of squares of the difference between the predicted output generated by the MLP and the target value is computed and compared to a predefined threshold. The accuracy value is computed as the percentage of data points, whose prediction matches the target value within a range < THRESHOLD:
val nCorrects = xt.toArray.zip(labels).foldLeft(0)((s, xtl) => {
val output = model.get.getOutput(xtl._1) //8
val _sse = xtl._2.zip(output.drop(1))
.foldLeft(0.0)((err,tp) => {
val diff= tp._1 - tp._2
err + diff*diff
}) //9
val error = Math.sqrt(_sse)/(output.size-1) //10
if(error < threshold) s + 1
else s
})
nCorrects.toDouble/xt.sizeThe implementation of the computation of the accuracy, as in the previous code snippet, retrieves the values of the output layer (line 8). The error value (line 10) is computed as the square root of the sum of squared errors, _sse (line 9). Finally, a prediction is considered correct if it is equal to the labeled output, within the margin error, threshold.
The test consists of evaluating six different models to determine which ones provide the most reliable correlation. It is critical to ensure that the result is somewhat independent of the architecture of the neural network. Different architectures are evaluated as part of the test.
The following charts compare the models for two architectures:
- Two hidden layers with four nodes each
- Three hidden layers with eight (with respect to five and six) nodes
This first chart visualizes the accuracy of the six regression models with an architecture consisting of a variable number of inputs [2, 7], one output variable, and two hidden layers of four nodes each. The features (ETF symbols) are listed on the left-hand side of the arrow => along the y-axis. The symbol on the right-hand side of the arrow is the expected output value:

Accuracy of MLP with two hidden layers of four nodes each
The next chart displays the accuracy of the six regression models for an architecture with three hidden layers of eight, five, and six nodes, respectively:

Accuracy of MLP with three hidden layers with 8, 5, and 6 nodes, respectively
The two network architectures shared a lot of similarity: in both cases, the most accurate regression models are as follows:
- FXE = f (FXA, SPY, GLD, FXB, FXF, FXD, FXY, CYB)
- FXE = g (FXC, GLD, FXA, FXY, FXB)
- FXE = h (FXF, FXB, CYB)
On the other hand, the prediction the Canadian dollar to US dollar's exchange rate (FXC) using the exchange rate for the Japanese yen (FXY) and the Australian dollar (FXA) is poor with both configuration.
Tip
The empirical evaluation
These empirical tests use a simple accuracy metric. A formal comparison of the regression models would systematically analyze every combination of input and output variables. The evaluation would also compute the precision, the recall, and the F1 score for each of those models (refer to the Key metrics section under Validation in the Assessing a model section in Chapter 2, Hello World!.
The next test consists of evaluating the impact of the hidden layer(s) of configuration on the accuracy of three models: (FXF, FXB, CYB => FXE), (FCX, GLD, FXA =>FXY), and (FXC, GLD, FXA, FXY, FXB => FXE). For this test, the accuracy is computed by selecting a subset of the training data as a test sample, for the sake of convenience. The objective of the test is to compare different network architectures using some metrics, not to estimate the absolute accuracy of each model.
The four network configurations are as follows:
- A single hidden layer with four nodes
- Two hidden layers with four nodes each
- Two hidden layers with seven nodes each
- Three hidden layer with eight, five, and six nodes

Impact of hidden layers architecture on the MLP accuracy
The complex neural network architecture with two or more hidden layers generates weights with similar accuracy. The four-node single hidden layer architecture generates the highest accuracy. The computation of the accuracy using a formal cross-validation technique would generate a lower accuracy number.
Finally, we look at the impact of the complexity of the network on the duration of the training, as in the following graph:
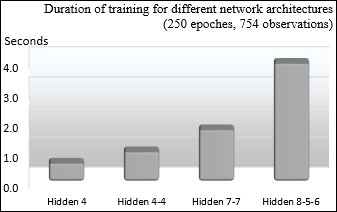
Impact of hidden layers architecture on duration of training
Not surprisingly, the time complexity increases significantly with the number of hidden layers and number of nodes.