
Most of the applications using support vector machines are related to classification. However, the same technique can be applied to regression problems. Luckily, as with classification, LIBSVM supports two formulations for support vector regression:
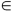 -VR (sometimes called C-SVR)
-VR (sometimes called C-SVR)
- υ-SVR
For the sake of consistency with the two previous cases, the following test uses the ![]() (or C) formulation of the support vector regression.
(or C) formulation of the support vector regression.
The SVR introduces the concept of error insensitive zone and insensitive error, ε. The insensitive zone defines a range of values around the predictive values, y(x). The penalization component C does not affect the data point {xi,yi} that belongs to the insensitive zone [8:14].
The following diagram illustrates the concept of an error insensitive zone, using a single variable feature x and an output y. In the case of a single variable feature, the error insensitive zone is a band of width 2ε. Ε is known as the insensitive error. The insensitive error plays a similar role to the margin in the SVC.

For the mathematically inclined, the maximization of the margin for nonlinear models introduces a pair of slack variables. As you may remember, the C-support vector classifiers use a single slack variable. The preceding diagram illustrates the minimization formula.


Let's reuse the SVM class to evaluate the capability of the SVR, compared to the linear regression (refer to the Ordinary least squares (OLS) regression section of Chapter 6, Regression and Regularization).
This test consists of reusing the example on single-variate linear regression (refer to the One-variate linear regression section of Chapter 6, Regression and Regularization). The purpose is to compare the output of the linear regression with the output of the SVR for predicting the value of a stock price or an index. We select the S&P 500 exchange traded fund, SPY, which is a proxy for the S&P 500 index.
The model consists of the following:
- One labeled output: SPY-adjusted daily closing price
- One single variable feature set: the index of the trading session (or index of the values SPY)
The implementation follows a familiar pattern:
- Define the configuration parameters for the SVR (the
Ccost/penalty function,GAMMAcoefficient for the RBF kernel,EPSfor the convergence criteria, andEPSILONfor the regression insensitive error). - Extract the labeled data (the SPY
price) from the data source (DataSource), which is the Yahoo financials CSV-formatted data file. - Create the linear Regression,
SingleLinearRegression, with the index of the trading session as the single variable feature and the SPY-adjusted closing price as the labeled output. - Create the observations as a time series of indexes,
xt - Instantiate the SVR with the index of trading session as features, and the SPY adjusted closing price as the labeled output
- Run the prediction methods for both SVR and the linear regression and compare the results of the linear regression and SVR
val path = "resources/data/chap8/SPY.csv" val C = 1; val GAMMA = 0.8; val EPS = 1e-3; val EPSILON = 0.1 //1 val price = DataSource(path, false, true, 1) |> adjClose //2 val priceIdx = price.zipWithIndex .map(x => (x._1.toDouble, x._2.toDouble)) val linRg = SingleLinearRegression(priceIdx) //3 val config = SVMConfig(new SVRFormulation(C, EPSILON), RbfKernel(GAMMA)) //3 val labels = price.toArray val xt = XTSeries[DblVector]( Array.tabulate(labels.size)(Array[Double](_))) //4 val svr = SVM[Double](config, xt, labels) //5 collect(svr, linRg, price) //6
The collect method invokes the predictive method for the support vector regression (line 7) and the linear regression model (line 8), and then buffers the results along with the original observation, price (line 9).
def collect(svr: SVM_Double,
lin: SingleLinearRegression[Double],
price: DblVector): Array[XYTSeries] = {
val collector = Array.fill(3)(new ArrayBuffer[XY]
Range(1, price.size-2).foldLeft(collector)( (xs, n) => {
xs(0).append((n, (svr |> n.toDouble).get)) //7
xs(1).append((n, (lin |> n).get)) //8
xs(2).append((n, price(n))) //9
xs
}).map( _.toArray)
}The types XY=(Double, Double) and XYTSeries=Array[(Double, Double)] have already been defined in the Primitive types section of Chapter 1, Getting Started.
The results are displayed in the following graph, generated using the JFreeChart library. The code to plot the data is omitted because it is not essential to the understanding of the application.

Comparative plot linear regression and SVR
The support vector regression provides a more accurate prediction than the linear regression model. You can also observe that the L2 regularization term of the SVR penalizes the data points (the SPY price) with a high deviation from the mean of the price. A lower value of C will increase the L2-norm penalty factor as λ =1/C.
There is no need to compare SVR with the logistic regression as the logistic regression is a classifier. However, SVM is related to the logistic regression; the hinge loss in SVM is similar to the loss in the logistic regression [8:15].