
Hadoop has a long history, and in most cases, organizations have already invested in the Hadoop infrastructure before they move their MR jobs to Spark. Unlike the Spark standalone cluster manager, which can run only Spark jobs, and Mesos, which can run a variety of applications, YARN runs Hadoop jobs as first-class. At the same time, it can run Spark jobs as well. This means that when a team decides to replace some of their MR jobs with Spark jobs, they can use the same cluster manager to run Spark jobs. In this recipe, we'll see how to deploy our Spark application on the YARN cluster manager.
Running a Spark job on YARN is very similar to running it against a Spark standalone cluster. It involves the following steps:
While the setup of the cluster itself is beyond the scope of this recipe, for the sake of completeness, let's quickly look at the relevant site XML configurations that were made while setting up a single-node pseudo-distributed cluster on a local machine. Refer to http://www.bogotobogo.com/Hadoop/BigData_hadoop_Install_on_ubuntu_single_node_cluster.php for the complete details on how to set up a local YARN/HDFS cluster:
The core-site.xml file:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
</property>
</configuration>The mapred-site.xml file:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
</property>
</configuration>The hdfs-site.xml file:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>Once the setup of the cluster is done, let's format HDFS and start the cluster (dfs and yarn):
Format namenode:
hdfs namenode -format
Start both HDFS and YARN:
sbin/start-all.sh
Let's confirm that the services are running through jps, and this is what we should see:

Ideally, when we do a
spark-submit, YARN should be able to pick our spark-assembly JAR (or Uber JAR) and upload it to HDFS. However, this doesn't happen correctly and results in the following error:
Error: Could not find or load main class org.apache.spark.deploy.yarn.ExecutorLauncher
In order to work around this issue, let's upload our spark-assembly JAR manually to HDFS and change our conf/spark-env.sh to reflect the location. The Hadoop config directory should also be specified in spark-env.sh:
Uploading the spark assembly to HDFS.
hadoop fs -mkdir /sparkbinary hadoop fs -put /Users/Gabriel/Apps/spark-1.4.1-bin-hadoop2.6/lib/spark-assembly-1.4.1-hadoop2.6.0.jar /sparkbinary/ hadoop fs -ls /sparkbinary
Uploading the Spam dataset to HDFS:
hadoop fs -mkdir /scalada hadoop fs -put ~/SMSSpamCollection /scalada/ hadoop fs -ls /scalada
Entries in spark-env.sh:
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop SPARK_EXECUTOR_URI=hdfs://localhost:9000/sparkbinary/spark-assembly-1.4.1-hadoop2.6.0.jar

Before we submit our Spark job to the YARN cluster, let's confirm that our setup is fine using the Spark shell. The Spark shell is a wrapper arround the Scala REPL, with Spark libraries set in the classpath. Configuring HADOOP_CONF_DIR to point to the Hadoop config directory ensures that Spark will now use YARN to run its jobs. However, there are two modes in which we can run the Spark job in YARN, namely yarn-client and yarn-cluster. Let's explore both of them in this subrecipe. But before we do that, to validate our configuration, we'll launch the Spark shell pointing the master to the yarn-client. After a rain of logs, we should be able to see a Scala prompt. This confirms that our configuration is good:
bin/spark-shell --master yarn-client

Now that we have confirmed that the shell loads up fine against the YARN master, let's head over to deploying our Spark job on YARN.
As we discussed earlier, there are two modes in which we can run a Spark application on YARN: the yarn-client mode and the yarn-cluster mode. In the yarn-client mode, the driver program resides on the client side and the YARN worker nodes are used only to execute the job. All of the brain of the application resides in the client JVM that polls the application master for the status. The application master does nothing except watching out for failure of the executor nodes and reporting and requesting for resources accordingly to the resource manager. This also means that the client (our driver JVM) needs to run as long as the application executes:
./bin/spark-submit --class com.packt.scalada.learning.BinaryClassificationSpamYarn --master yarn-client --executor-memory 1G ~/scalada-learning-assembly.jar

As we see from the YARN console, our job is running fine. Here is a screenshot that shows this:

Finally, we can see the output on the client JVM (the driver) itself:

In the yarn-cluster mode, the client JVM doesn't do anything at all. In fact, it just submits and polls the Application master for status. The driver program itself runs on the Application master, which now has all the brains of the program. Unlike the yarn-client mode, the user logs won't be displayed on the client JVM because the driver, which consolidates the results, is executing inside the YARN cluster:
./bin/spark-submit --class com.packt.scalada.learning.BinaryClassificationSpamYarn --master yarn-cluster --executor-memory 1g ~/scalada-learning-assembly.jar

As expected, the client JVM indicates that the job has run successfully. It doesn't, however, show the user logs.

The following screenshot shows the final status of our client and the cluster mode runs:
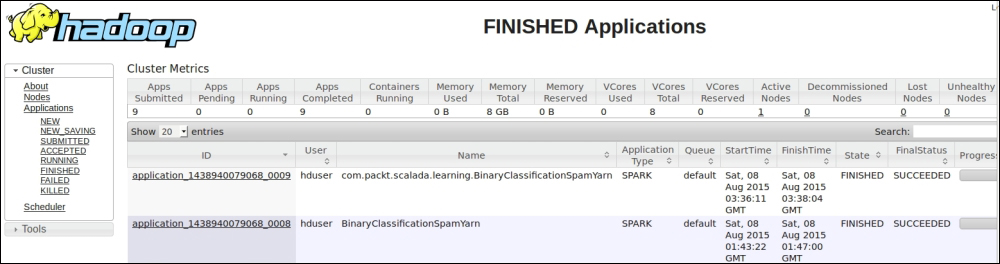
The actual output of this program is inside the Hadoop user logs. We can either go to the logs directory of Hadoop, or check it out from the Hadoop console itself, when we click on the application link and then on the logs link in the console.
As you can see in the following screenshot, the stdout file shows our embarrassing println commands:

In this chapter, we took an example Spark application and deployed it on a Spark standalone cluster manager, YARN, and Mesos. Along the way, we touched upon the internals of these cluster managers.