
The Scala standard library offers a rich set of tools, such as parallel collections and concurrent classes to scale number-crunching applications. Although these tools are very effective in processing medium-sized datasets, they are unfortunately quite often discarded by developers in favor of more elaborate frameworks.
Although code optimization and memory management is beyond the scope of this chapter, it is worthwhile to remember that a few simple steps can be taken to improve the scalability of an application. One of the most frustrating challenges in using Scala to process large datasets is the creation of a large number of objects and the load on the garbage collector.
A partial list of remedial actions is as follows:
The Scala standard library includes parallelized collections, whose purpose is to shield developers from the intricacies of concurrent thread execution and race condition. Parallel collections are a very convenient approach to encapsulate concurrency constructs to a higher level of abstraction [12:1].
There are two ways to create parallel collections in Scala:
- Converting an existing collection into a parallel collection of the same semantic using the
parmethod, for example,List[T].par: ParSeq[T],Array[T].par: ParArray[T],Map[K,V].par: ParMap[K,V], and so on - Using the collections classes from the
collection.parallel,parallel.immutable, orparallel.mutablepackages, for example,ParArray,ParMap,ParSeq,ParVector, and so on
A parallel collection does lend itself to concurrent processing until a pool of threads and a tasks scheduler are assigned to it. Fortunately, Scala parallel and concurrent packages provide developers with a powerful toolbox to map partitions or segments of collection to tasks running on different CPU cores. The components are as follows:
TaskSupport: This trait inherits the genericTaskstrait. It is responsible for scheduling the operation on the parallel collection. There are three concrete implementations ofTaskSupport.ThreadPoolTaskSupport: This uses thethreadspool in an older version of the JVM.ExecutionContextTaskSupport: This usesExecutorService, which delegates the management of tasks to either a thread pool or theForkJoinTaskspool.ForkJoinTaskSupport: This uses the fork-join pools of typejava.util.concurrent.FortJoinPoolintroduced in Java SDK 1.6. In Java, a fork-join pool is an instance ofExecutorServicethat attempts to run not only the current task but also any of its subtasks. It executes theForkJoinTaskinstances that are lightweight threads.
The following example implements the generation of random exponential value using a parallel vector and ForkJoinTaskSupport:
val rand = new ParVector[Float] Range(0, MAX).foreach(n =>rand.updated(n, n*Random.nextFloat))//1 rand.tasksupport = new ForkJoinTaskSupport(new ForkJoinPool(16)) val randExp = vec.map( Math.exp(_) )//2
The parallel vector of random probabilities, rand, is created and initialized by the main task (line 1), but the conversion to a vector of exponential value, randExp, is executed by a pool of 16 concurrent tasks (line 2).
The main purpose of parallel collections is to improve the performance of execution through concurrency. First, let us create a parameterized class, Benchmark, to evaluate the performance of operations on a parallel array, v, relative to an array, u, as follows:
class ParArrayBenchmark[U](u: Array[U], v: ParArray[U], times:Int)
Next, you need to create a method, timing, that computes the ratio of the duration of a given operation on a parallel collection over the duration of the same operation on a single threaded collection, as shown here:
def timing(g: Int => Unit ): Long = { var startTime = System.currentTimeMillis Range(0, times).foreach(g) System.currentTimeMillis - startTime }
This method measures the time it takes to process a user-defined function, g, times times.
Let's compare the parallelized and default array on the map and reduce methods of Benchmark as follows
def map(f: U => U)(nTasks: Int): Unit = { val pool = new ForkJoinPool(nTasks) v.tasksupport = new ForkJoinTaskSupport(pool) val duration = timing(_ => u.map(f)).toDouble //3 val ratio = timing( _ => v.map(f))/duration //4 Display.show(s"$nTasks, $ratio", logger) }
The user has to define the mapping function, f, and the number of concurrent tasks, nTasks, available to execute a map transformation on the array u (line 3) and its parallelized counterpart v (line 4). The reduce method follows the same design as shown in the following code:
def reduce(f: (U,U) => U)(nTasks: Int): Unit = { val pool = new ForkJoinPool(nTasks) v.tasksupport = new ForkJoinTaskSuppor(pool) val duration = timing(_ => u.reduceLeft(f)).toDouble val ratio = timing( _ => v.reduceLeft(f) )/duration Display.show(s"$nTasks, $ratio", logger) }
The same template can be used for other higher Scala methods, such as filter. The absolute timing of each operation is completely dependent on the environment. It is far more useful to record the ratio of the duration of execution of operation on the parallelized array, over the single thread array.
The benchmark class, ParMapBenchmark, used to evaluate ParHashMap is similar to the benchmark for ParArray, as shown in the following code:
class ParMapBenchmark[U](val u: Map[Int, U], val v: ParMap[Int, U], times: Int)
For example, the filter method of ParMapBenchmark evaluates the performance of the parallel map v relative to single threaded map u. It applies the filtering condition to the values of each map as follows:
def filter(f: U => Boolean)(nTasks: Int): Unit = { val pool = new ForkJoinPool(nTasks) v.tasksupport = new ForkJoinTaskSupport(pool) val duration = timing(_ => u.filter(e => f(e._2))).toDouble val ratio = timing( _ => v.filter(e => f(e._2)))/duration Display.show(s"$nTasks, $ratio", logger) }
The first performance test consists of creating a single-threaded and a parallel array of random values and executing the evaluation methods, map and reduce, on using an increasing number of tasks, as follows:
val sz = 1000000 val data = Array.fill(sz)(Random.nextDouble) val pData = ParArray.fill(sz)(Random.nextDouble) val times: Int = 50 val bench1 = new ParArrayBenchmark[Double](data, pData, times) val mapper = (x: Double) => Math.sin(x*0.01) + Math.exp(-x) Range(1, 16).foreach(n => bench1.map(mapper)(n)) val reducer = (x: Double, y: Double) => x+y Range(1, 16).foreach(n => bench1.reduce(reducer)(n))
The following graph shows the output of the performance test:

The test executes the mapper and reducer functions 1 million times on an 8-core CPU with 8 GB of available memory on JVM.
The results are not surprising in the following respects:
- The reducer doesn't take advantage of the parallelism of the array. The reduction of
ParArrayhas a small overhead in the single-task scenario and then matches the performance ofArray. - The performance of the
mapfunction benefits from the parallelization of the array. The performance levels off when the number of tasks allocated equals or exceeds the number of CPU core.
The second test consists of comparing the behavior of two parallel collections, ParArray and ParHashMap, on two methods, map and filter, using a configuration identical to the first test as follows:
val sz = 1000000 val mData = new HashMap[Int, Double] Range(0, sz).foreach(n => mData.put(n, Random.nextDouble)) //1 val mParData = new ParHashMap[Int, Double] Range(0, sz).foreach(n => mParData.put(n, Random.nextDouble)) val bench2 = new ParMapBenchmark[Double](mData, mParData, times) Range(1, 16).foreach(n => bench2.map(mapper)(n)) //2 val filterer = (x: Double) => (x > 0.8) Range(1, 16).foreach(n => bench2.filter(filterer)(n)) //3
The test initializes a HashMap instance and its parallel counter ParHashMap with 1 million random values (line 1). The benchmark, bench2, processes all the elements of these hash maps with the mapper instance introduced in the first test (line 2) and a filtering function, filterer (line 3), with 16 tasks. The output is as shown here:
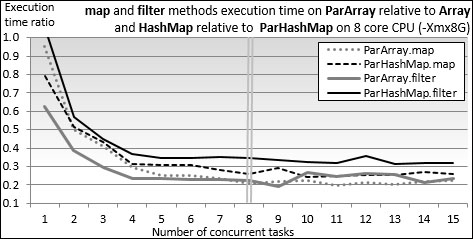
The impact of the parallelization of collections is very similar across methods and across collections. It's important to notice that the performance of the parallel collections levels off at around four times the single thread collections for five concurrent tasks and above. Core parking is partially responsible for this behavior. Core parking disables a few CPU cores in an effort to conserve power, and in the case of singe application, consumes almost all CPU cycles.
Clearly, a four-times increase in performance is nothing to complain about. That being said, parallel collections are limited to single host deployment. If you cannot live with such a restriction and still need a scalable solution, the Actor model provides a blueprint for highly distributed applications.