
Uncertainty in volatility estimation is an important issue, but it is often overlooked. To assess the variability of an estimated volatility, one must consider the kurtosis of a volatility model. In this section, we derive the excess kurtosis of a GARCH(1,1) model. The same idea applies to other GARCH models, however. The model considered is
![]()
where α0 > 0, α1 ≥ 0, β1 ≥ 0, α1 + β1 < 1, and {ϵt} is an iid sequence satisfying
![]()
where Kϵ is the excess kurtosis of the innovation ϵt. Based on the assumption, we have the following:
- Var(at) =
 .
. 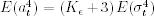 provided that
provided that  exists.
exists.
Taking the square of the volatility model, we have
![]()
Taking expectation of the equation and using the two properties mentioned earlier, we obtain
![]()
provided that 1 > α1 + β1 ≥ 0 and ![]() The excess kurtosis of at, if it exists, is then
The excess kurtosis of at, if it exists, is then

This excess kurtosis can be written in an informative expression. First, consider the case that ϵt is normally distributed. In this case, Kϵ = 0, and some algebra shows that
![]()
where the superscript (g) is used to denote Gaussian distribution. This result has two important implications: (a) the kurtosis of at exists if ![]() , and (b) if α1 = 0, then
, and (b) if α1 = 0, then ![]() , meaning that the corresponding GARCH(1,1) model does not have heavy tails.
, meaning that the corresponding GARCH(1,1) model does not have heavy tails.
Second, consider the case that ϵt is not Gaussian. Using the prior result, we have

This result was obtained originally by George C. Tiao; see Bai, Russell, and Tiao (2003). It holds for all GARCH models provided that the kurtosis exists. For instance, if β1 = 0, then the model reduces to an ARCH(1) model. In this case, it is easy to verify that ![]() provided that
provided that ![]() and the excess kurtosis of at is
and the excess kurtosis of at is

The prior result shows that for a GARCH(1,1) model the coefficient α1 plays a critical role in determining the tail behavior of at. If α1 = 0, then ![]() and Ka = Kϵ. In this case, the tail behavior of at is similar to that of the standardized noise ϵt. Yet if α1 > 0, then
and Ka = Kϵ. In this case, the tail behavior of at is similar to that of the standardized noise ϵt. Yet if α1 > 0, then ![]() and the at process has heavy tails.
and the at process has heavy tails.
For a (standardized) Student-t distribution with v degrees of freedom, we have ![]() = 6/(v − 4) + 3 if v > 4. Therefore, the excess kurtosis of ϵt is Kϵ = 6/(v − 4) for v > 4. This is part of the reason that we used t5 in the chapter when the degrees of freedom of a t-distribution are prespecified. The excess kurtosis of at becomes
= 6/(v − 4) + 3 if v > 4. Therefore, the excess kurtosis of ϵt is Kϵ = 6/(v − 4) for v > 4. This is part of the reason that we used t5 in the chapter when the degrees of freedom of a t-distribution are prespecified. The excess kurtosis of at becomes ![]() provided that
provided that ![]() .
.