
A useful step in multivariate volatility modeling is to reparameterize ![]() by making use of its symmetric property. We consider two reparameterizations.
by making use of its symmetric property. We consider two reparameterizations.
10.3.1 Use of Correlations
The first reparameterization of ![]() is to use the conditional correlation coefficients and variances of
is to use the conditional correlation coefficients and variances of ![]() . Specifically, we write
. Specifically, we write ![]() as
as
where ![]() is the conditional correlation matrix of
is the conditional correlation matrix of ![]() , and
, and ![]() is a k × k diagonal matrix consisting of the conditional standard deviations of elements of
is a k × k diagonal matrix consisting of the conditional standard deviations of elements of ![]() (i.e.,
(i.e., ![]() ).
).
Because ![]() is symmetric with unit diagonal elements, the time evolution of
is symmetric with unit diagonal elements, the time evolution of ![]() is governed by that of the conditional variances σii, t and the elements ρij, t of
is governed by that of the conditional variances σii, t and the elements ρij, t of ![]() , where j < i and 1 ≤ i ≤ k. Therefore, to model the volatility of
, where j < i and 1 ≤ i ≤ k. Therefore, to model the volatility of ![]() , it suffices to consider the conditional variances and correlation coefficients of ait. Define the k(k + 1)/2-dimensional vector
, it suffices to consider the conditional variances and correlation coefficients of ait. Define the k(k + 1)/2-dimensional vector
10.8 ![]()
where ![]() is a k(k − 1)/2-dimensional vector obtained by stacking columns of the correlation matrix
is a k(k − 1)/2-dimensional vector obtained by stacking columns of the correlation matrix ![]() , but using only elements below the main diagonal. Specifically, for a k-dimensional return series,
, but using only elements below the main diagonal. Specifically, for a k-dimensional return series,
![]()
To illustrate, for k = 2, we have ![]() and
and
which is a three-dimensional vector, and for k = 3, we have ![]() and
and
10.10 ![]()
which is a six-dimensional random vector.
If ![]() is a bivariate normal random variable, then
is a bivariate normal random variable, then ![]() is given in Eq. (10.9) and the conditional density function of
is given in Eq. (10.9) and the conditional density function of ![]() given
given ![]() is
is

where
![]()
The log probability density function of ![]() relevant to the maximum-likelihood estimation is
relevant to the maximum-likelihood estimation is
10.11 
This reparameterization is useful because it models covariances and correlations directly. Yet the approach has several weaknesses. First, the likelihood function becomes complicated when k ≥ 3. Second, the approach requires a constrained maximization in estimation to ensure the positive definiteness of ![]() . The constraint becomes complicated when k is large.
. The constraint becomes complicated when k is large.
10.3.2 Cholesky Decomposition
The second reparameterization of ![]() is to use the Cholesky decomposition; see Appendix A of Chapter 8. This approach has some advantages in estimation as it requires no parameter constraints for the positive definiteness of
is to use the Cholesky decomposition; see Appendix A of Chapter 8. This approach has some advantages in estimation as it requires no parameter constraints for the positive definiteness of ![]() ; see Pourahmadi (1999). In addition, the reparameterization is an orthogonal transformation so that the resulting likelihood function is extremely simple. Details of the transformation are given next.
; see Pourahmadi (1999). In addition, the reparameterization is an orthogonal transformation so that the resulting likelihood function is extremely simple. Details of the transformation are given next.
Because ![]() is positive definite, there exist a lower triangular matrix
is positive definite, there exist a lower triangular matrix ![]() with unit diagonal elements and a diagonal matrix
with unit diagonal elements and a diagonal matrix ![]() with positive diagonal elements such that
with positive diagonal elements such that
This is the well-known Cholesky decomposition of ![]() . A feature of the decomposition is that the lower off-diagonal elements of
. A feature of the decomposition is that the lower off-diagonal elements of ![]() and the diagonal elements of
and the diagonal elements of ![]() have nice interpretations. We demonstrate the decomposition by studying carefully the bivariate and three-dimensional cases. For the bivariate case, we have
have nice interpretations. We demonstrate the decomposition by studying carefully the bivariate and three-dimensional cases. For the bivariate case, we have
![]()
where gii, t > 0 for i = 1 and 2. Using Eq. (10.12), we have
![]()
Equating elements of the prior matrix equation, we obtain
Solving the prior equations, we have
However, consider the simple linear regression
where b2t denotes the error term. From the well-known least-squares theory, we have

Furthermore, the error term b2t is uncorrelated with the regressor a1t. Consequently, using Eq. (10.14), we obtain
![]()
where ![]() denotes no correlation. In summary, the Cholesky decomposition of the 2 × 2 matrix
denotes no correlation. In summary, the Cholesky decomposition of the 2 × 2 matrix ![]() amounts to performing an orthogonal transformation from
amounts to performing an orthogonal transformation from ![]() to
to ![]() such that
such that
![]()
where q21, t = β is obtained by the linear regression (10.15) and Cov(![]() ) is a diagonal matrix with diagonal elements gii, t. The transformed quantities q21, t and gii, t can be interpreted as follows:
) is a diagonal matrix with diagonal elements gii, t. The transformed quantities q21, t and gii, t can be interpreted as follows:
1. The first diagonal element of ![]() is simply the variance of a1t.
is simply the variance of a1t.
2. The second diagonal element of ![]() is the residual variance of the simple linear regression in Eq. (10.15).
is the residual variance of the simple linear regression in Eq. (10.15).
3. The element q21, t of the lower triangular matrix ![]() is the coefficient β of the regression in Eq. (10.15).
is the coefficient β of the regression in Eq. (10.15).
The prior properties continue to hold for the higher dimensional case. For example, consider the three-dimensional case in which

From the decomposition in Eq. (10.12), we have

Equating elements of the prior matrix equation, we obtain

or, equivalently,

These quantities look complicated, but they are simply the coefficients and residual variances of the orthogonal transformation

where βij are the coefficients of least-squares regressions
![]()
In other words, we have qij, t = βij, gii, t = Var(bit) and ![]() for i ≠ j.
for i ≠ j.
Based on the prior discussion, using Cholesky decomposition amounts to doing an orthogonal transformation from ![]() to
to ![]() , where b1t = a1t, and bit, for 1 < i ≤ k, is defined recursively by the least-squares regression
, where b1t = a1t, and bit, for 1 < i ≤ k, is defined recursively by the least-squares regression
where qij, t is the (i, j)th element of the lower triangular matrix ![]() for 1 ≤ j < i. We can write this transformation as
for 1 ≤ j < i. We can write this transformation as
10.17 ![]()
where, as mentioned before, ![]() is also a lower triangular matrix with unit diagonal elements. The covariance matrix of
is also a lower triangular matrix with unit diagonal elements. The covariance matrix of ![]() is the diagonal matrix
is the diagonal matrix ![]() of the Cholesky decomposition because
of the Cholesky decomposition because
![]()
The parameter vector relevant to volatility modeling under such a transformation becomes
which is also a k(k + 1)/2-dimensional vector.
The previous orthogonal transformation also dramatically simplifies the likelihood function of the data. Using the fact that ![]() , we have
, we have
If the conditional distribution of ![]() given the past information is multivariate normal
given the past information is multivariate normal ![]() , then the conditional distribution of the transformed series bt is multivariate normal N(0Gt, and the log-likelihood function of the data becomes extremely simple. Indeed, we have the log probability density of
, then the conditional distribution of the transformed series bt is multivariate normal N(0Gt, and the log-likelihood function of the data becomes extremely simple. Indeed, we have the log probability density of ![]() as
as
where for simplicity the constant term is omitted and gii, t is the variance of bit.
Using the Cholesky decomposition to reparameterize ![]() has several advantages. First, from Eq. (10.19),
has several advantages. First, from Eq. (10.19), ![]() is positive definite if gii, t > 0 for all i. Consequently, the positive-definite constraint of
is positive definite if gii, t > 0 for all i. Consequently, the positive-definite constraint of ![]() can easily be achieved by modeling ln(gii, t) instead of gii, t. Second, elements of the parameter vector
can easily be achieved by modeling ln(gii, t) instead of gii, t. Second, elements of the parameter vector ![]() in Eq. (10.18) have nice interpretations. They are the coefficients and residual variances of multiple linear regressions that orthogonalize the shocks to the returns. Third, the correlation coefficient between a1t and a2t is
in Eq. (10.18) have nice interpretations. They are the coefficients and residual variances of multiple linear regressions that orthogonalize the shocks to the returns. Third, the correlation coefficient between a1t and a2t is
![]()
which is time varying if q21, t ≠ 0. In particular, if q21, t = c ≠ 0, then ![]() , which continues to be time-varying provided that the variance ratio σ11, t/σ22, t is not a constant. This time-varying property applies to other correlation coefficients when the dimension of
, which continues to be time-varying provided that the variance ratio σ11, t/σ22, t is not a constant. This time-varying property applies to other correlation coefficients when the dimension of ![]() is greater than 2 and is a major difference between the two approaches for reparameterizing
is greater than 2 and is a major difference between the two approaches for reparameterizing ![]() .
.
Using Eq. (10.16) and the orthogonality among the transformed shocks bit, we obtain
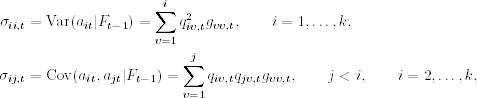
where qvv, t = 1 for v = 1, … , k. These equations show the parameterization of ![]() under the Cholesky decomposition.
under the Cholesky decomposition.