
So far in this chapter, you have identified and executed simple duplicate detection rules. Simple rules might not solve all of your duplicate detection needs, however. In this section, you will learn how to implement more complex duplicate detection rules.
In this exercise, you will create a single duplicate detection rule that will include the following scenarios:
The rule will include partial match criteria. For example, you could match on the first three letters of the first name plus the last name.
The rule will identify a duplicate record based on a different record type. For example, you could identify active leads that have a corresponding active contact.
Note
USE your own Microsoft Dynamics CRM installation in place of the Adventure Works Cycle site shown in this exercise.
BE SURE TO use the Internet Explorer Web browser to navigate to your Microsoft Dynamics CRM Web site, if necessary, before beginning this exercise.
In the Settings area, click Data Management.
Click Duplicate Detection Rules, and then click the New button.
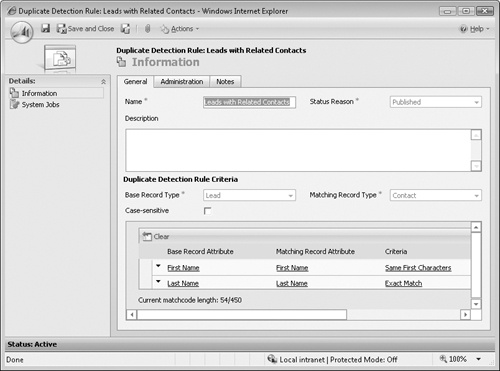
Complete the New Duplicate Detection Rule form with the following values:
Name
Leads with related contacts
Base Record Type
Lead
Matching Record Type
Contact
Base Record Attribute
First Name
Matching Record Attribute
First Name
Criteria
Same First Characters
No. of Characters
3
Base Record Attribute (second row)
Last Name
Matching Record Attribute (second row)
Last Name
Criteria (second row)
Exact Match
In the form toolbar, click Save and Close.
You have now created a duplicate detection rule that uses a partial match and compares one type of record (leads) against another (contacts). The process of resolving the duplicates is largely the same as checking a single entity, but be aware of the following:
You cannot merge records of two different types (for example, a lead and a contact). However, you can delete or deactivate the potential duplicate record.
In the potential duplicate records list, you might have to toggle between record types to see all potential duplicates.