
We minimize the loss function using the gradient descent algorithm. So, we backpropagate the network, calculate the gradient of the loss function with respect to weights, and update the weights. We have two sets of weights, input to hidden layer weight  and hidden to output layer weights
and hidden to output layer weights  . We calculate gradients of loss with respect to both of these weights and update them according to the weight update rule:
. We calculate gradients of loss with respect to both of these weights and update them according to the weight update rule:


In order to better understand the backpropagation, let's recollect the steps involved in the forward propagation:



First, we compute the gradients of loss with respect to the hidden to output layer  . We cannot calculate the gradient of loss
. We cannot calculate the gradient of loss  with respect to directly from
with respect to directly from  , as there is no term in the loss function , so we apply the chain rule as follows:
, as there is no term in the loss function , so we apply the chain rule as follows:

The derivative of the first term is as follows:

Here,  is the error term, which is the difference between the actual word and predicted word.
is the error term, which is the difference between the actual word and predicted word.
Now, we will calculate the derivative of the second term.
Since we know :

Thus, the gradient of loss with respect to is given as:
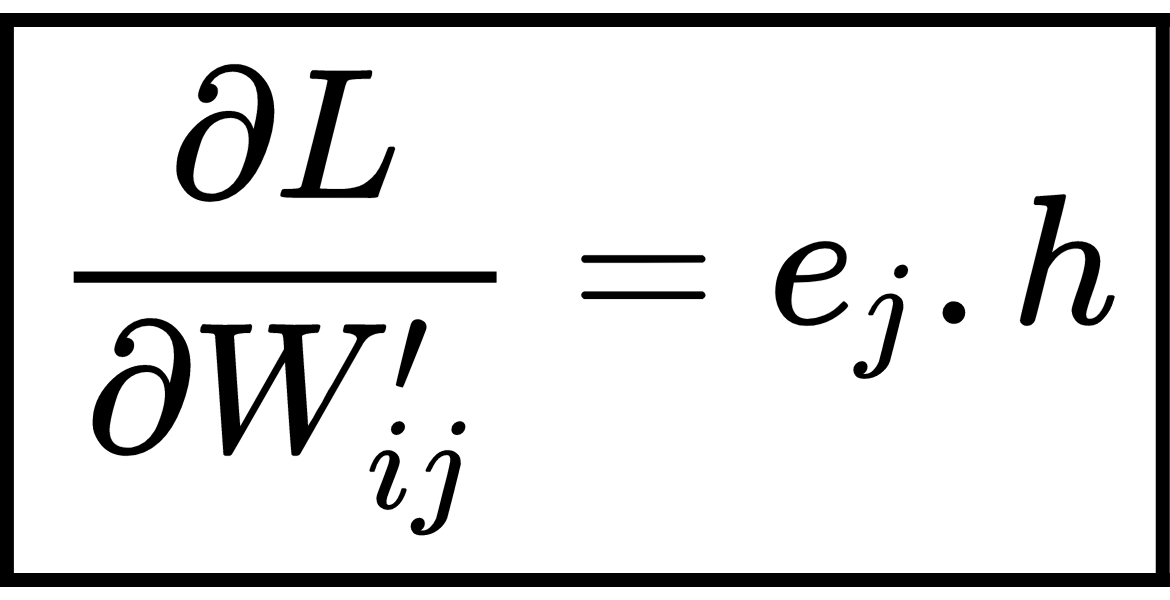
Now, we compute the gradient with respect to the input to hidden layer weight  . We cannot calculate the derivative directly from
. We cannot calculate the derivative directly from  , as there is no
, as there is no  term in , so we apply the chain rule as follows:
term in , so we apply the chain rule as follows:

In order to compute the derivative of the first term in the preceding equation, we again apply the chain rule, as we cannot compute the derivative of  with respect to
with respect to  directly from
directly from  :
:

From equation (5), we can write:

Since we know :

Instead of having the sum, we can write:

 denotes the sum of the output vector of all words in the vocabulary, weighted by their prediction error.
denotes the sum of the output vector of all words in the vocabulary, weighted by their prediction error.
Let's now calculate the derivative of the second term.
Since we know, :

Thus, the gradient of loss with respect to is given as:

So, our weight update equation becomes the following:


We update the weights of our network using the preceding equation and obtain an optimal weights during training. The optimal input to hidden layer weight,  , becomes the vector representation for the words in our vocabulary.
, becomes the vector representation for the words in our vocabulary.
The Python code for Single_context_CBOW is as follows:
def Single_context_CBOW(x, label, W1, W2, loss):
#forward propagation
h = np.dot(W1.T, x)
u = np.dot(W2.T, h)
y_pred = softmax(u)
#error
e = -label + y_pred
#backward propagation
dW2 = np.outer(h, e)
dW1 = np.outer(x, np.dot(W2.T, e))
#update weights
W1 = W1 - lr * dW1
W2 = W2 - lr * dW2
#loss function
loss += -float(u[label == 1]) + np.log(np.sum(np.exp(u)))
return W1, W2, loss