
As we saw when we discussed LSTM cells, calculating gradients of loss with respect to all the weights requires the gradients of all the gates and content state. So, first, we will see how to calculate them.
In the upcoming calculations, we will be using the gradients of loss with respect to the hidden state,  , which is
, which is  at multiple places, so we will see how to calculate that. Computing the gradients of loss with respect to the hidden state,
at multiple places, so we will see how to calculate that. Computing the gradients of loss with respect to the hidden state,  , is exactly the same as we saw in the LSTM cell, and can be given as follows:
, is exactly the same as we saw in the LSTM cell, and can be given as follows:

First, let's see how to calculate the gradients of loss with respect to the content state,  .
.
To calculate the gradients of loss with respect to content state, look at the equations of forward propagation and find out which equation has the  term. In the hidden state equation, that is, equation (8), we have the
term. In the hidden state equation, that is, equation (8), we have the  term, which is given as follows:
term, which is given as follows:

So, by the chain rule, we can write the following:


Let's see how to calculate the gradient of loss with respect to the reset gate  .
.
We have the term in the content state equation and it can be given as shown:

Thus, by the chain rule, we can write the following:
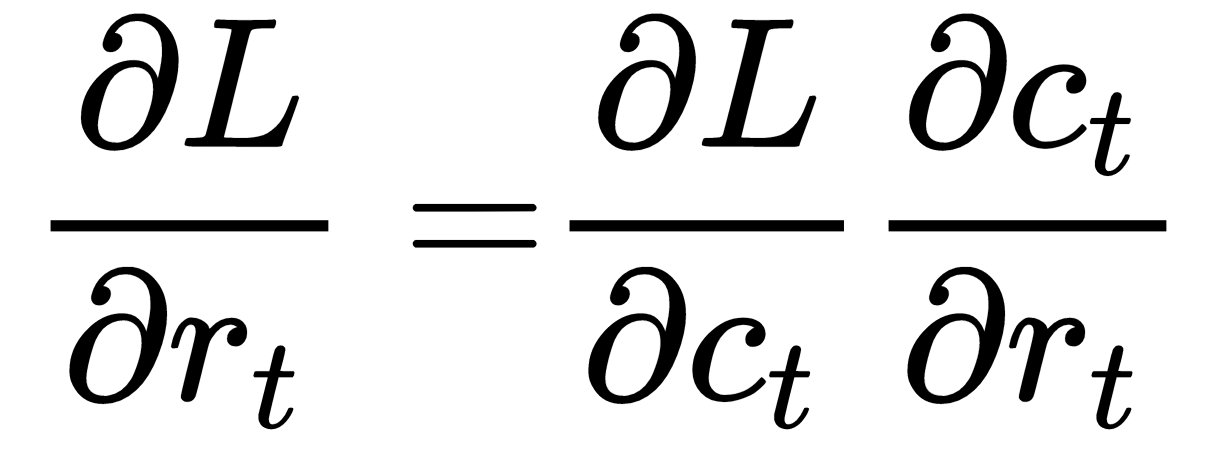

Finally, we see the gradient of loss with respect to the update gate,  .
.
We have the  term in the hidden state,
term in the hidden state,  , equation, which can be given as follows:
, equation, which can be given as follows:

Thus, by the chain rule, we can write the following:


Now that we have calculated the gradients of loss with respect to all the gates and the content state, we will see how to calculate gradients of loss with respect to all the weights in our GRU cell.