
As we have just learned, autoencoders consist of two important components: an encoder 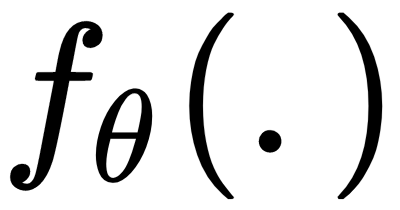 and a decoder
and a decoder  . Let's look at each one of them closely:
. Let's look at each one of them closely:
- Encoder: The encoder
 learns the input and returns the latent representation of the input. Let's assume we have an input,
learns the input and returns the latent representation of the input. Let's assume we have an input,  . When we feed the input to the encoder, it returns a low-dimensional latent representation of the input called code or a bottleneck,
. When we feed the input to the encoder, it returns a low-dimensional latent representation of the input called code or a bottleneck,  . We represent the parameter of the encoder by
. We represent the parameter of the encoder by  :
:


- Decoder: The decoder
 tries to reconstruct the original input
tries to reconstruct the original input  using the output of the encoder that is code
using the output of the encoder that is code  as an input. The reconstructed image is represented by
as an input. The reconstructed image is represented by  . We represent the parameters of the decoder by
. We represent the parameters of the decoder by  :
:
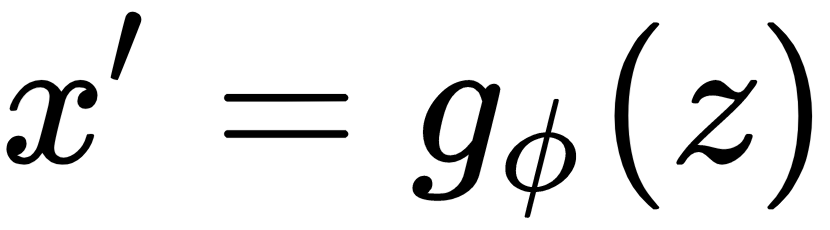

We need to learn the optimal parameters,  and
and  , of our encoder and decoder respectively so that we can minimize the reconstruction loss. We can define our loss function as the mean squared error between the actual input and reconstructed input:
, of our encoder and decoder respectively so that we can minimize the reconstruction loss. We can define our loss function as the mean squared error between the actual input and reconstructed input:

Here,  is the number of training samples.
is the number of training samples.
When the latent representation has a lesser dimension than the input, then it is called an undercomplete autoencoder. Since the dimensions are less, undercomplete autoencoders try to learn and retain the only useful distinguishing and important features of the input and remove the rest. When the latent representation has a dimension greater than or the same as the input, the autoencoders will just copy the input without learning any useful features, and such a type of autoencoder is called overcomplete autoencoders.
Undercomplete and overcomplete autoencoders are shown in the following diagram. Undercomplete autoencoders have fewer neurons in the hidden layer (code) than the number of neurons in the input layer; while in the overcomplete autoencoders, the number of neurons in the hidden layer (code) is greater than the number of units in the input layer:

Thus, by limiting the neurons in the hidden layer (code), we can learn the useful representations of the input. Autoencoders can also have any number of hidden layers. Autoencoders with multiple hidden layers are called multilayer autoencoders or deep autoencoders. What we have learned so far is just the vanilla or the shallow autoencoder.