
Calculating gradients of loss with respect to all the weights used in the LSTM cell requires the gradients of all the gates and the candidate state. So, in this section, we will learn how to compute the gradient of the loss function with respect to all of the gates and the candidate state.
Before we begin, let's recollect the following two things:
- The derivative of a sigmoid function is expressed as follows:

- The derivative of a tanh function is expressed as follows:

In the upcoming calculations, we will be using gradients of loss with respect to hidden state 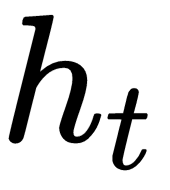 and cell state
and cell state  at multiple places. Thus, first, we will see how to compute gradients of loss with respect to hidden state
at multiple places. Thus, first, we will see how to compute gradients of loss with respect to hidden state  and cell state
and cell state  .
.
First, let's see how to calculate the gradients of loss with respect to a hidden state,  .
.
We know that output  is computed as follows:
is computed as follows:

Let's say  . We have the
. We have the  term in
term in  , so by the chain rule, we can write the following:
, so by the chain rule, we can write the following:


We have already seen how to compute  in Chapter 4, Generating Song Lyrics Using RNN, so directly from the equation (9) of Chapter 4, Generating Song Lyrics Using RNN, we can write the following:
in Chapter 4, Generating Song Lyrics Using RNN, so directly from the equation (9) of Chapter 4, Generating Song Lyrics Using RNN, we can write the following:

Now, let's see how to calculate the gradient of the loss with respect to cell state,  .
.
To calculate the gradients of loss with respect to the cell state, look at the equations of forward propagation and find out which equation has the  term. On the equation of the hidden state, we have the
term. On the equation of the hidden state, we have the  term as follows:
term as follows:

So, by the chain rule, we can write the following:

We know that the derivative of tanh is  , thus we can write the following:
, thus we can write the following:

Now that we have calculated the gradients of loss with respect to the hidden state and the cell state, let's see how to calculate the gradient of loss with respect to all the gates one by one.
First, we will see how to calculate the gradient of loss with respect to the output gate,  .
.
To calculate the gradients of loss with respect to the output gate, look at the equations of forward propagation and find out in which equation we have the  term. In the equation of the hidden state we have the
term. In the equation of the hidden state we have the  term as follows:
term as follows:

So, by the chain rule, we can write the following:
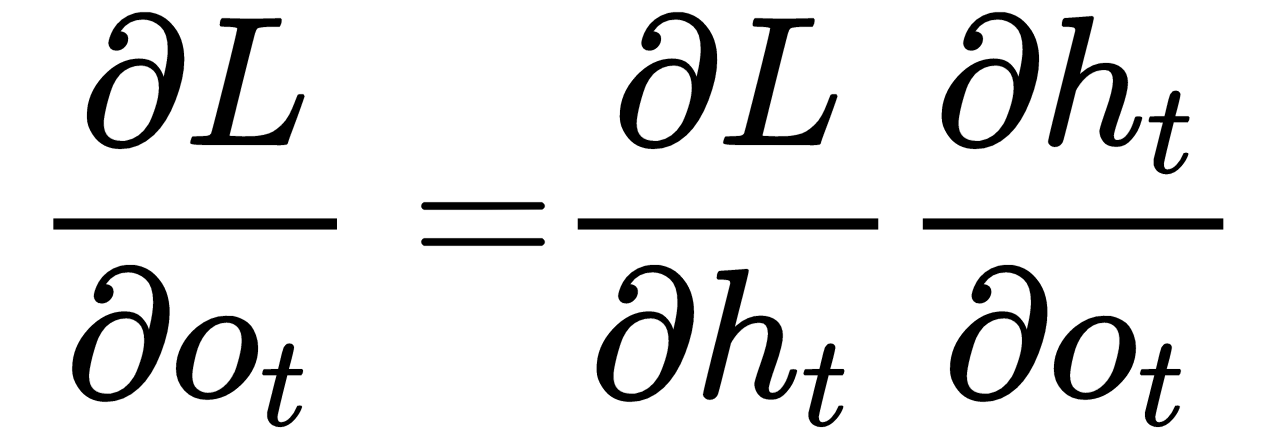

Now we will see how to calculate the gradient of loss with respect to the input gate,  .
.
We have the  term in the cell state equation for
term in the cell state equation for  :
:

By the chain rule, we can write the following:


And now we learn how to calculate the gradient of loss with respect to the forget gate,  .
.
We also have the  term in the cell state equation for
term in the cell state equation for  :
:

By the chain rule, we can write the following:


Finally, we learn how to calculate the gradient of loss with respect to the candidate state,  .
.
We also have the  term in the cell state equation for
term in the cell state equation for  :
:
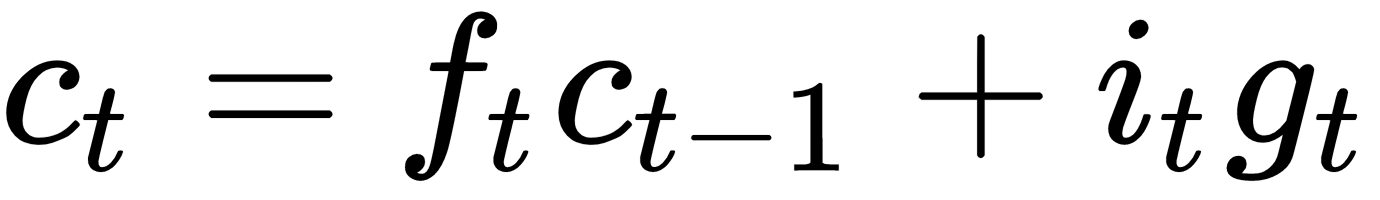
Thus, by the chain rule, we can write the following:


Thus, we have calculated the gradients of loss with respect to all the gates and the candidate state. In the next section, we'll see how to calculate the gradients of loss with respect to all of the weights used in the LSTM cell.