
One problem with momentum is that it might miss out the minimum value. That is, as we move closer toward convergence (the minimum point), the value for momentum will be high. When the value of momentum is high while we are near to attaining convergence, then the momentum actually pushes the gradient step high and it might miss out on the actual minimum value; that is, it might overshoot the minimum value when the momentum is high when we are near to convergence, as shown in the following diagram:

To overcome this, Nesterov introduced a new method called Nesterov accelerated gradient (NAG).
The fundamental motivation behind Nesterov momentum is that, instead of calculating the gradient at the current position, we calculate gradients at the position where the momentum would take us to, and we call that position the lookahead position.
What does this mean, though? In the Gradient descent with momentum section, we learned about the following equation:

The preceding equation tells us that we are basically pushing the current gradient step,  , to a new position using a fraction of the parameter update from the previous step,
, to a new position using a fraction of the parameter update from the previous step, 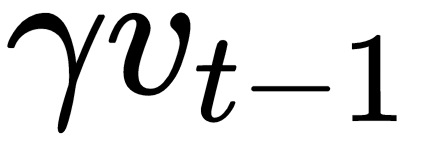 , which will help us to attain convergence. However, when the momentum is high, this new position will actually overshoot the minimum value.
, which will help us to attain convergence. However, when the momentum is high, this new position will actually overshoot the minimum value.
Thus, before making a gradient step with momentum and reaching a new position, if we understand which position the momentum will take us to, then we can avoid overshooting the minimum value. If we find out that momentum will take us to the position that actually misses the minimum value, then we can slow down the momentum and try to reach the minimum value.
But how can we find the position that the momentum will take us to? In equation (2), instead of calculating gradients with respect to the current gradient step, 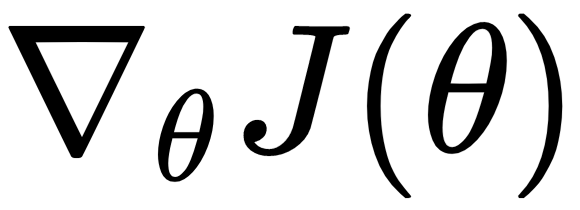 , we calculate gradients with respect to
, we calculate gradients with respect to  . The term,
. The term,  , basically tells us the approximate position of where our next gradient step is going to be. We call this the lookahead position. This gives us an idea of where our next gradient step is going to be.
, basically tells us the approximate position of where our next gradient step is going to be. We call this the lookahead position. This gives us an idea of where our next gradient step is going to be.
So, we can rewrite our  equation according to NAG as follows:
equation according to NAG as follows:

We update our parameter as follows:

Updating the parameters with the preceding equation prevents us from missing the minimum value by slowing down the momentum when the gradient steps are near to convergence. The Nesterov accelerated method is implemented as follows.
First, we define the NAG function:
def NAG(data, theta, lr = 1e-2, gamma = 0.9, num_iterations = 1000):
Then, we initialize the value of vt with zeros:
vt = np.zeros(theta.shape[0])
For every iteration, we perform the following steps:
for t in range(num_iterations):
Now, we need to compute the gradients with respect to  :
:
gradients = compute_gradients(data, theta - gamma * vt)
Then, we update vt as  :
:
vt = gamma * vt + lr * gradients
Now, we update the model parameter, theta, to  :
:
theta = theta - vt
return theta