
We know that autoencoders learn to reconstruct the input. But when we set the number of nodes in the hidden layer greater than the number of nodes in the input layer, then it will learn an identity function which is not favorable, because it just completely copies the input.
Having more nodes in the hidden layer helps us to learn robust latent representation. But when there are more nodes in the hidden layer, the autoencoder tries to completely mimic the input and thus it overfits the training data. To resolve the problem of overfitting, we introduce a new constraint to our loss function called the sparsity constraint or sparsity penalty. The loss function with sparsity penalty can be represented as follows:

The first term  represents the reconstruction error between the original input
represents the reconstruction error between the original input  and reconstructed input,
and reconstructed input,  . The second term implies the sparsity constraint. Now we will explore how this sparse constraint mitigates the problem of overfitting.
. The second term implies the sparsity constraint. Now we will explore how this sparse constraint mitigates the problem of overfitting.
Using the sparsity constraint, we activate only specific neurons on the hidden layer instead of activating all the neurons. Based on the input, we activate and deactivate specific neurons so the neurons, when they are activated, will learn to extract important features from the input. By having the sparse penalty, autoencoders will not copy the input exactly to the output and it can also learn the robust latent representation.
As shown in the following diagram, sparse autoencoders have more units in the hidden layer than the input layer; however, only a few neurons in the hidden layer are activated. The unshaded neurons represent the neurons that are currently activated:

A neuron returns 1 if it's active and 0 if it is inactive. In sparse autoencoders, we set most of the neurons in the hidden layer to inactive. We know that the sigmoid activation function squashes the value to between 0 and 1. So, when we use the sigmoid activation function, we try to keep the values of neurons close to 0.
We typically try to keep the average activation value of each neuron in the hidden layer close to zero, say 0.05, but not equal to zero, and this value is called  , which is our sparsity parameter. We typically set the value of to 0.05.
, which is our sparsity parameter. We typically set the value of to 0.05.
First, we calculate the average activation of a neuron.
The average activation of the  neuron in the hidden layer
neuron in the hidden layer  over the whole training set can be calculated as follows:
over the whole training set can be calculated as follows:

Here, the following holds true:
 denotes the average activation of the
denotes the average activation of the  neuron in the hidden layer
neuron in the hidden layer  is the number of the training sample
is the number of the training sample is the activation of
is the activation of  neuron in the hidden layer
neuron in the hidden layer  is the
is the  training sample
training sample implies the activation of the
implies the activation of the  neuron in the hidden layer for the
neuron in the hidden layer for the  th training sample
th training sample
We try to keep the average activation value,  , of the neurons close to . That is, we try to keep the average activation values of the neurons to 0.05:
, of the neurons close to . That is, we try to keep the average activation values of the neurons to 0.05:

So, we penalize the value of  , which is varying from . We know that the Kullback–Leibler (KL) divergence is widely used for measuring the difference between the two probability distributions. So, here, we use the KL divergence to measure the difference between two Bernoulli distributions, that is, mean and mean and it can be given as follows:
, which is varying from . We know that the Kullback–Leibler (KL) divergence is widely used for measuring the difference between the two probability distributions. So, here, we use the KL divergence to measure the difference between two Bernoulli distributions, that is, mean and mean and it can be given as follows:
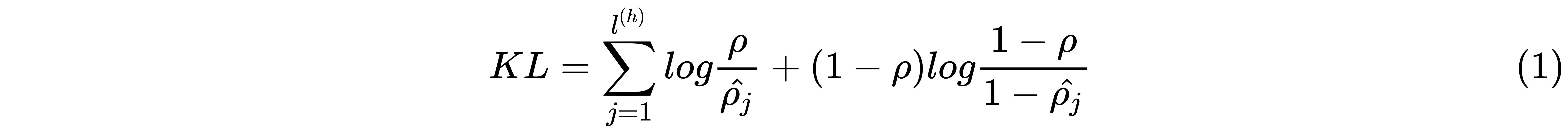
In the earlier equation,  denotes the hidden layer
denotes the hidden layer  , and
, and  denotes the
denotes the  neurons in the hidden layer . The earlier equation is basically the sparse penalty or sparsity constraint. Thus, with the sparsity constraint, all the neurons will never be active at the same time, and on average, they are set to 0.05.
neurons in the hidden layer . The earlier equation is basically the sparse penalty or sparsity constraint. Thus, with the sparsity constraint, all the neurons will never be active at the same time, and on average, they are set to 0.05.
Now we can rewrite the loss function with a sparse penalty as follows:

Thus, sparse autoencoders allow us to have a greater number of nodes in the hidden layer than the input layer, yet reduce the problem of overfitting with the help of the sparsity constraint in the loss function.