
The convolutional layer is the first and core layer of the CNN. It is one of the building blocks of a CNN and is used for extracting important features from the image.
We have an image of a horse. What do you think are the features that will help us to understand that this is an image of a horse? We can say body structure, face, legs, tail, and so on. But how does the CNN understand these features? This is where we use a convolution operation that will extract all the important features from the image that characterize the horse. So, the convolution operation helps us to understand what the image is all about.
Okay, what exactly is this convolution operation? How it is performed? How does it extract the important features? Let's look at this in detail.
As we know, every input image is represented by a matrix of pixel values. Apart from the input matrix, we also have another matrix called the filter matrix. The filter matrix is also known as a kernel, or simply a filter, as shown in the following diagram:

We take the filter matrix, slide it over the input matrix by one pixel, perform element-wise multiplication, sum up the results, and produce a single number. That's pretty confusing, isn't it? Let's understand this better with the aid of the following diagram:

As you can see in the previous diagram, we took the filter matrix and placed it on top of the input matrix, performed element-wise multiplication, summed their results, and produced the single number. This is demonstrated as follows:

Now, we slide the filter over the input matrix by one pixel and perform the same steps, as shown in the following diagram:

This is demonstrated as follows:

Again, we slide the filter matrix by one pixel and perform the same operation, as shown in the following diagram:

This is demonstrated as follows:
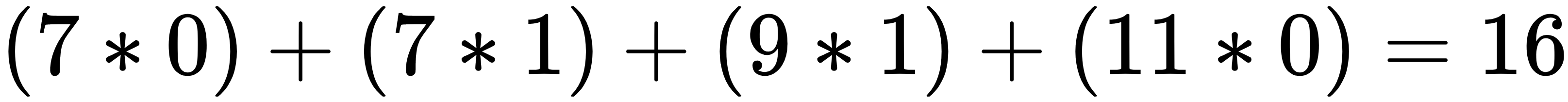
Now, again, we slide the filter matrix over the input matrix by one pixel and perform the same operation, as shown in the following diagram:

That is:

Okay. What are we doing here? We are basically sliding the filter matrix over the entire input matrix by one pixel, performing element-wise multiplication and summing their results, which creates a new matrix called a feature map or activation map. This is called the convolution operation.
As we've learned, the convolution operation is used to extract features, and the new matrix, that is, the feature maps, represents the extracted features. If we plot the feature maps, then we can see the features extracted by the convolution operation.
The following diagram shows the actual image (the input image) and the convolved image (the feature map). We can see that our filter has detected the edges from the actual image as a feature:

Various filters are used for extracting different features from the image. For instance, if we use a sharpen filter,  , then it will sharpen our image, as shown in the following figure:
, then it will sharpen our image, as shown in the following figure:

Thus, we have learned that with filters, we can extract important features from the image using the convolution operation. So, instead of using one filter, we can use multiple filters for extracting different features from the image, and produce multiple feature maps. So, the depth of the feature map will be the number of filters. If we use seven filters to extract different features from the image, then the depth of our feature map will be seven:

Okay, we have learned that different filters extract different features from the image. But the question is, how can we set the correct values for the filter matrix so that we can extract the important features from the image? Worry not! We just initialize the filter matrix randomly, and the optimal values of the filter matrix, with which we can extract the important features from the images, will be learned through backpropagation. However, we just need to specify the size of the filter and the number of filters we want to use.