
We just learned how forward propagation works in RNNs and how it predicts the output. Now, we compute the loss,  , at each time step,
, at each time step,  , to determine how well the RNN has predicted the output. We use the cross-entropy loss as our loss function. The loss
, to determine how well the RNN has predicted the output. We use the cross-entropy loss as our loss function. The loss  at a time step can be given as follows:
at a time step can be given as follows:

Here,  is the actual output, and
is the actual output, and  is the predicted output at a time step
is the predicted output at a time step  .
.
The final loss is a sum of the loss at all the time steps. Suppose that we have  layers; then, the final loss can be given as follows:
layers; then, the final loss can be given as follows:
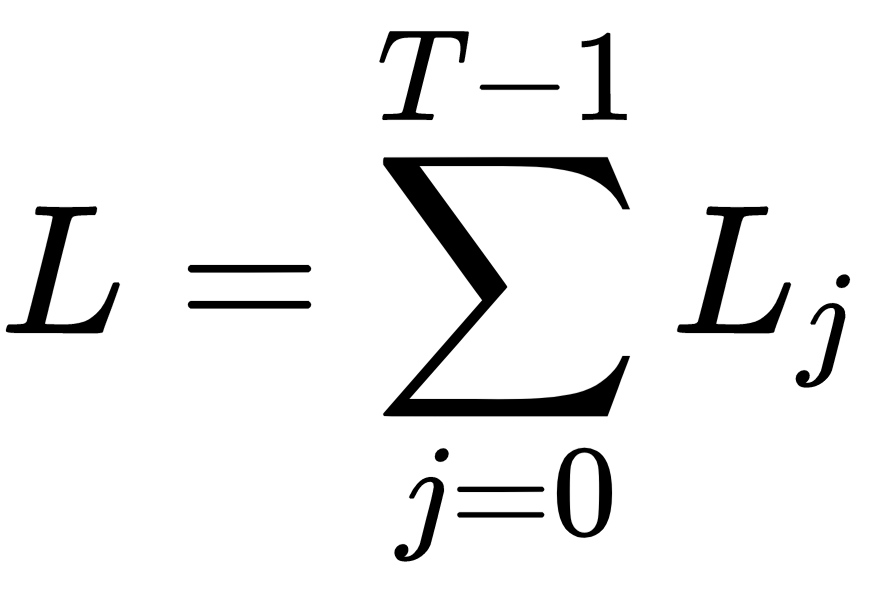
As shown in the following figure, the final loss is obtained by the sum of loss at all the time steps:

We computed the loss, now our goal is to minimize the loss. How can we minimize the loss? We can minimize the loss by finding the optimal weights of the RNN. As we learned, we have three weights in RNNs: input to hidden,  , hidden to hidden,
, hidden to hidden,  , and hidden to output,
, and hidden to output,  .
.
We need to find optimal values for all of these three weights to minimize the loss. We can use our favorite gradient descent algorithm to find the optimal weights. We begin by calculating the gradients of the loss function with respect to all the weights; then, we update the weights according to the weight update rule as follows:



First, we calculate the gradients of loss with respect to the final layer  , that is
, that is  , so that we can use it in the upcoming steps.
, so that we can use it in the upcoming steps.
As we have learned, the loss at a time step can be given as follows:

Since we know:

We can write:

Thus, the gradient of the loss with respect to becomes:

Now, we will learn how to calculate the gradient of the loss with respect to all the weights one by one.