
Matching networks are yet another simple and efficient one-shot learning algorithm published by Google's DeepMind. It can even produce labels for the unobserved class in the dataset. Let's say we have a support set,  ,containing
,containing  examples as
examples as  . When given a query point (new unseen example),
. When given a query point (new unseen example),  , the matching network predicts the class of
, the matching network predicts the class of  by comparing it with the support set.
by comparing it with the support set.
We can define this as  , where
, where  is the parameterized neural network,
is the parameterized neural network,  is the predicted class for query point , and is the support set.
is the predicted class for query point , and is the support set.  will return the probability of belonging to each class in the support set. Then we select the class of as the one that has the highest probability. But how does this work, exactly? How is this probability computed? Let's see that now. The class, ,of the query point, ,can be predicted as follows:
will return the probability of belonging to each class in the support set. Then we select the class of as the one that has the highest probability. But how does this work, exactly? How is this probability computed? Let's see that now. The class, ,of the query point, ,can be predicted as follows:
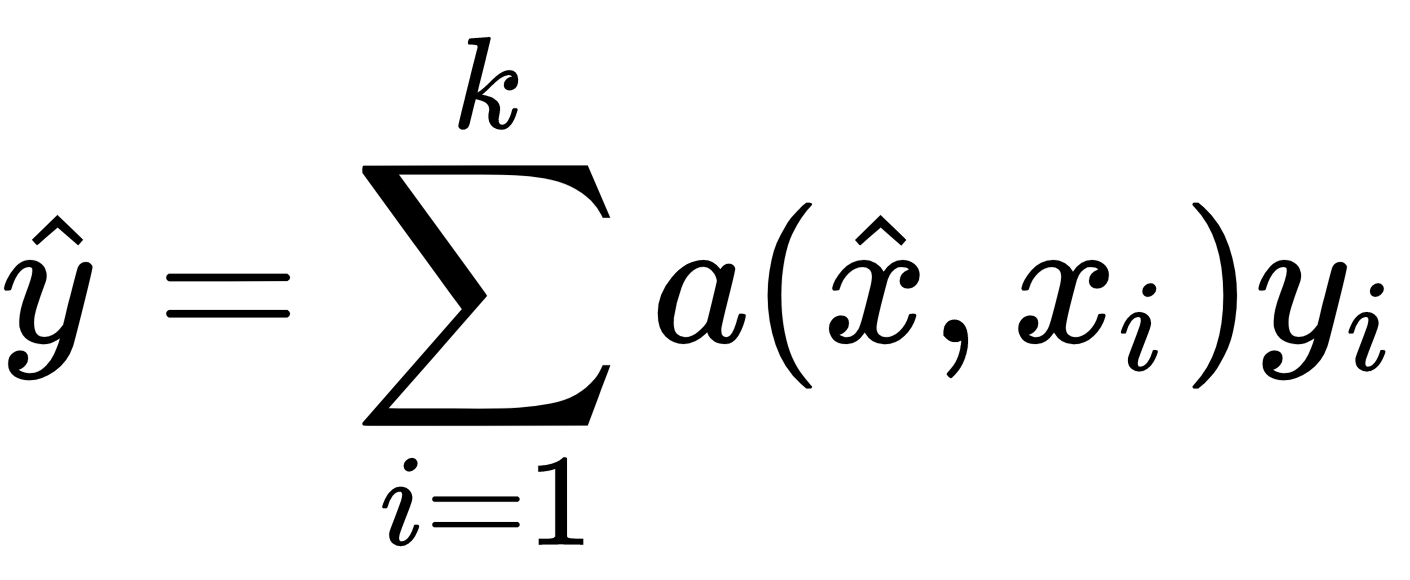
Let's decipher this equation. Here  and
and  are the input and labels of the support set. is the query input, that is, the input to which we want to predict the label. Also
are the input and labels of the support set. is the query input, that is, the input to which we want to predict the label. Also  is the attention mechanism between and
is the attention mechanism between and 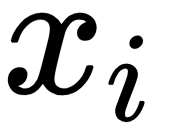 . But how do we perform attention? Here, we use a simple attention mechanism, which is softmax over the cosine distance between and
. But how do we perform attention? Here, we use a simple attention mechanism, which is softmax over the cosine distance between and  :
:

We can't calculate cosine distance between the raw inputs and directly. So, first, we will learn their embeddings and calculate the cosine distance between the embeddings. We use two different embeddings,  and
and  , for learning the embeddings of and respectively. We will learn how exactly these two embedding functions
, for learning the embeddings of and respectively. We will learn how exactly these two embedding functions  and
and  learn the embeddings in the upcoming section. So, we can rewrite our attention equation as follows:
learn the embeddings in the upcoming section. So, we can rewrite our attention equation as follows:

We can rewrite the preceding equation as follows:

After calculating the attention matrix,  , we multiply our attention matrix with support set labels
, we multiply our attention matrix with support set labels  . But how can we multiply support set labels with our attention matrix? First, we convert our support set labels to the one hot encoded values and then multiply them with our attention matrix and, as a result, we get the probability of our query point belonging to each of the classes in the support set. Then we apply argmax and select
. But how can we multiply support set labels with our attention matrix? First, we convert our support set labels to the one hot encoded values and then multiply them with our attention matrix and, as a result, we get the probability of our query point belonging to each of the classes in the support set. Then we apply argmax and select  as the one that has a maximum probability value.
as the one that has a maximum probability value.
Still not clear about matching networks? Look at the following diagram; you can see we have three classes in our support set (lion, elephant, and dog) and we have a new query image .
First, we feed the support set to embedding function  and the query image to the embedding function
and the query image to the embedding function  and learn their embeddings and calculate the cosine distance between them, and then we apply softmax attention over this cosine distance. Then we multiply our attention matrix with the one-hot encoded support set labels and get the probabilities. Next, we select as the one that has the highest probability. As you can see in the following diagram, the query set image is an elephant, and we have a high probability at the index 1, so we predict the class of as 1 (elephant):
and learn their embeddings and calculate the cosine distance between them, and then we apply softmax attention over this cosine distance. Then we multiply our attention matrix with the one-hot encoded support set labels and get the probabilities. Next, we select as the one that has the highest probability. As you can see in the following diagram, the query set image is an elephant, and we have a high probability at the index 1, so we predict the class of as 1 (elephant):

We have learned that we use two embedding functions, and , for learning the embeddings of and respectively. Now we will see exactly how these two functions learn the embeddings.