
Let's calculate the gradients of loss with respect to hidden-to-input layer weights  for all the gates and the candidate state. Computing gradients of loss with respect to is exactly the same as the gradients we computed with respect to
for all the gates and the candidate state. Computing gradients of loss with respect to is exactly the same as the gradients we computed with respect to  , except that the last term will be
, except that the last term will be  instead of
instead of 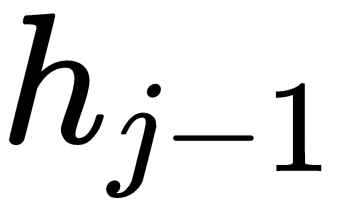 . Let's examine what we mean by that.
. Let's examine what we mean by that.
Let's find out the gradients of loss with respect to  .
.
The input gate equation is as follows:

Thus, using the chain rule, we can write the following:

Let's calculate each of the terms in the preceding equation. We already know the first term from equation (2). So, the second term can be computed as follows:

Thus, our final equation for calculating the gradient of loss with respect to  becomes the following:
becomes the following:

As you can see, the preceding equation is exactly the same as  , except that the last term is
, except that the last term is  instead of
instead of 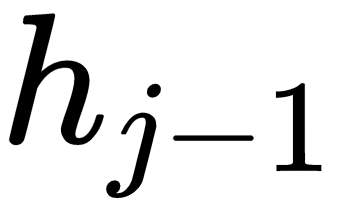 . This applies for all other weights, so we can directly write the equations as follows:
. This applies for all other weights, so we can directly write the equations as follows:
- Gradients of loss with respect to
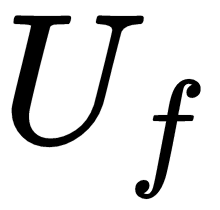 :
:

- Gradients of loss with respect to
 :
:

- Gradients of loss with respect to
 :
:

After the computing gradients, with respect to all of these weights, we update them using the weight update rule and minimize the loss.