
So far, we just studied the role of the generator and discriminator, but how do they learn exactly? How does the generator learn to generate new realistic images and how does the discriminator learn to discriminate between images correctly?
We know that the goal of the generator is to generate an image in such a way as to fool the discriminator into believing that the generated image is from a real distribution.
In the first iteration, the generator generates a noisy image. When we feed this image to the discriminator, discriminator can easily detect that the image is from a generator distribution. The generator takes this as a loss and tries to improve itself, as its goal is to fool the discriminator. That is, if the generator knows that the discriminator is easily detecting the generated image as a fake image, then it means that it is not generating an image similar to those in the training set. This implies that it has not learned the probability distribution of the training set yet.
So, the generator tunes its parameters in such a way as to learn the correct probability distribution of the training set. As we know that the generator is a neural network, we simply update the parameters of the network through backpropagation. Once it has learned the probability distribution of the real images, then it can generate images similar to the ones in the training set.
Okay, what about the discriminator? How does it learn? As we know, the role of the discriminator is to discriminate between real and fake images.
If the discriminator incorrectly classifies the generated image; that is, if the discriminator classifies the fake image as a real image, then it implies that the discriminator has not learned to differentiate between the real and fake image. So, we update the parameter of the discriminator network through backpropagation to make the discriminator learn to classify between real and fake images.
So, basically, the generator is trying to fool the discriminator by learning the real data distribution,  , and the discriminator is trying to find out whether the image is from a real or fake distribution. Now the question is, when do we stop training the network in light of the fact that both generator and discriminator are competing against each other?
, and the discriminator is trying to find out whether the image is from a real or fake distribution. Now the question is, when do we stop training the network in light of the fact that both generator and discriminator are competing against each other?
Basically, the goal of the GAN is to generate images similar to the one in the training set. Say we want to generate a human face—we learn the distribution of images in the training set and generate new faces. So, for a generator, we need to find the optimal discriminator. What do we mean by that?
We know that a generator distribution is represented by  and the real data distribution is represented by
and the real data distribution is represented by  . If the generator learns the real data distribution perfectly, then
. If the generator learns the real data distribution perfectly, then 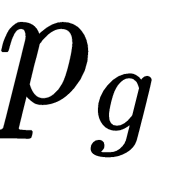 equals
equals  , as shown in the following plot:
, as shown in the following plot:

When  , then the discriminator cannot differentiate between whether the input image is from a real or a fake distribution, so it will just return 0.5 as a probability, as the discriminator will become confused between the two distributions when they are same.
, then the discriminator cannot differentiate between whether the input image is from a real or a fake distribution, so it will just return 0.5 as a probability, as the discriminator will become confused between the two distributions when they are same.
So, for a generator, the optimal discriminator can be given as follows:

So, when the discriminator just returns the probability of 0.5 for any image, then we can say that the generator has learned the distribution of images in our training set and fooled the discriminator successfully.