
The gradients of the loss function,  , with respect to the parameter
, with respect to the parameter  , are given as follows:
, are given as follows:

The gradients of the loss function,  , with respect to the parameter
, with respect to the parameter  , are given as follows:
, are given as follows:

We define a function called compute_gradients, which takes the parameters, data and theta as input and returns the computed gradients:
def compute_gradients(data, theta):
Now, we need to initialize the gradients:
gradients = np.zeros(2)
Then, we need to save the total number of data points in N:
N = float(len(data))
Now, we can get the value of  and
and  :
:
m = theta[0]
b = theta[1]
We do the same for each iteration:
for i in range(0, len(data)):
Then, we get the value of  and
and  :
:
x = data[i, 0]
y = data[i, 1]
Now, we compute the gradient of the loss with respect to  , as given in equation (4):
, as given in equation (4):
gradients[0] += - (2 / N) * x * (y - (( m* x) + b))
Then, we compute the gradient of the loss with respect to  , as given in equation (5):
, as given in equation (5):
gradients[1] += - (2 / N) * (y - ((theta[0] * x) + b))
We need to add epsilon to avoid division by zero error:
epsilon = 1e-6
gradients = np.divide(gradients, N + epsilon)
return gradients
When we feed our randomly initialized data and theta model parameter, the compute_gradients function returns the gradients with respect to 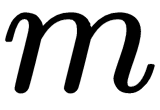 , that is,
, that is,  , and gradients with respect to
, and gradients with respect to  , that is,
, that is,  , as follows:
, as follows:
compute_gradients(data,theta)
array([-9.08423989e-05, 1.05174511e-04])