
We just learned how the seq2seq model works and how it translates a sentence from the source language to the target language. We learned that a context vector is basically a hidden state vector from the final time step of an encoder, which captures the meaning of the input sentence, and it is used by the decoder to generate the target sentence.
But when the input sentence is long, the context vector does not capture the meaning of the whole sentence, since it is just the hidden state from the final time step. So, instead of taking the last hidden state as a context vector and using it for the decoder, we take the sum of all the hidden states from the encoder and use it as a context vector.
Let's say the input sentence has 10 words; then we would have 10 hidden states. We take a sum of all these 10 hidden states and use it for the decoder to generate the target sentence. However, not all of these hidden states might be helpful in generating a target word at time step  . Some hidden states will be more useful than other hidden states. So, we need to know which hidden state is more important than another at time step to predict the target word. To get this importance, we use the attention mechanism, which tells us which hidden state is more important to generate the target word at the time step . Thus, attention mechanisms basically give the importance for each of the hidden states of the encoder to generate the target word at time step .
. Some hidden states will be more useful than other hidden states. So, we need to know which hidden state is more important than another at time step to predict the target word. To get this importance, we use the attention mechanism, which tells us which hidden state is more important to generate the target word at the time step . Thus, attention mechanisms basically give the importance for each of the hidden states of the encoder to generate the target word at time step .
How does an attention mechanism work? Let's say we have three hidden states of an encoder,  ,
,  , and
, and  , and a decoder hidden state,
, and a decoder hidden state,  , as shown in the following diagram:
, as shown in the following diagram:

Now, we need to know the importance of all the hidden states of an encoder to generate a target word at time step , So, we take each encoder hidden state,  , and decoder hidden state,
, and decoder hidden state,  , and feed them to a function,
, and feed them to a function,  , which is called a score function or alignment function, and it returns the score for each of the encoder hidden states indicating their importance. But what is this score function? There are a number of choices for the score function, such as dot product, scaled dot product, cosine similarity, and more.
, which is called a score function or alignment function, and it returns the score for each of the encoder hidden states indicating their importance. But what is this score function? There are a number of choices for the score function, such as dot product, scaled dot product, cosine similarity, and more.
We use a simple dot product as the score function; that is, the dot product between the encoder hidden states and the decoder hidden states. For instance, to know the importance of 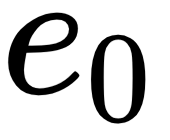 in generating the target word, we simply compute the dot product between and
in generating the target word, we simply compute the dot product between and  , which gives us a score indicating how similar and are.
, which gives us a score indicating how similar and are.
Once we have the score, we convert them into probabilities using the softmax function as follows:

These probabilities,  , are called attention weights.
, are called attention weights.
As you can see in the following diagram, we compute the similarity score between each of the encoder's hidden states with the decoder's hidden state using a function,  . Then, the similarity score is converted into probabilities using the softmax function, which are called attention weights:
. Then, the similarity score is converted into probabilities using the softmax function, which are called attention weights:

Thus, we have attention weights (probabilities) for each of the encoder's hidden states. Now, we multiply the attention weights with their corresponding encoder's hidden state, that is,  . As shown in the following diagram, the encoder's hidden state,
. As shown in the following diagram, the encoder's hidden state,  , is multiplied by 0.106,
, is multiplied by 0.106,  is multiplied by 0.106, and
is multiplied by 0.106, and  is multiplied by 0.786:
is multiplied by 0.786:

But, why do we have to multiply attention weights by the encoder's hidden state?
Multiplying the encoder's hidden states by their attention weights indicates that we are giving more importance to the hidden states that have more attention weights, and less importance to hidden states that have fewer attention weights. As shown in the preceding diagram, multiplying 0.786 with hidden state implies we are giving more importance to than the other two hidden states.
Thus, this is how the attention mechanism decides which hidden state is more important to generate the target word at time step  . After multiplying the encoder's hidden state by their attention weights, we simply sum them up, and this now forms our context/thought vector:
. After multiplying the encoder's hidden state by their attention weights, we simply sum them up, and this now forms our context/thought vector:

As shown in the following diagram, the context vector is obtained by the sum of the encoder's hidden state multiplied by its respective attention weights:

Thus, to generate a target word at time step , the decoder uses context vector  at time step
at time step  . With the attention mechanism, instead of taking the last hidden state as a context vector and using it for the decoder, we take the sum of all the hidden states from the encoder and use it as a context vector.
. With the attention mechanism, instead of taking the last hidden state as a context vector and using it for the decoder, we take the sum of all the hidden states from the encoder and use it as a context vector.