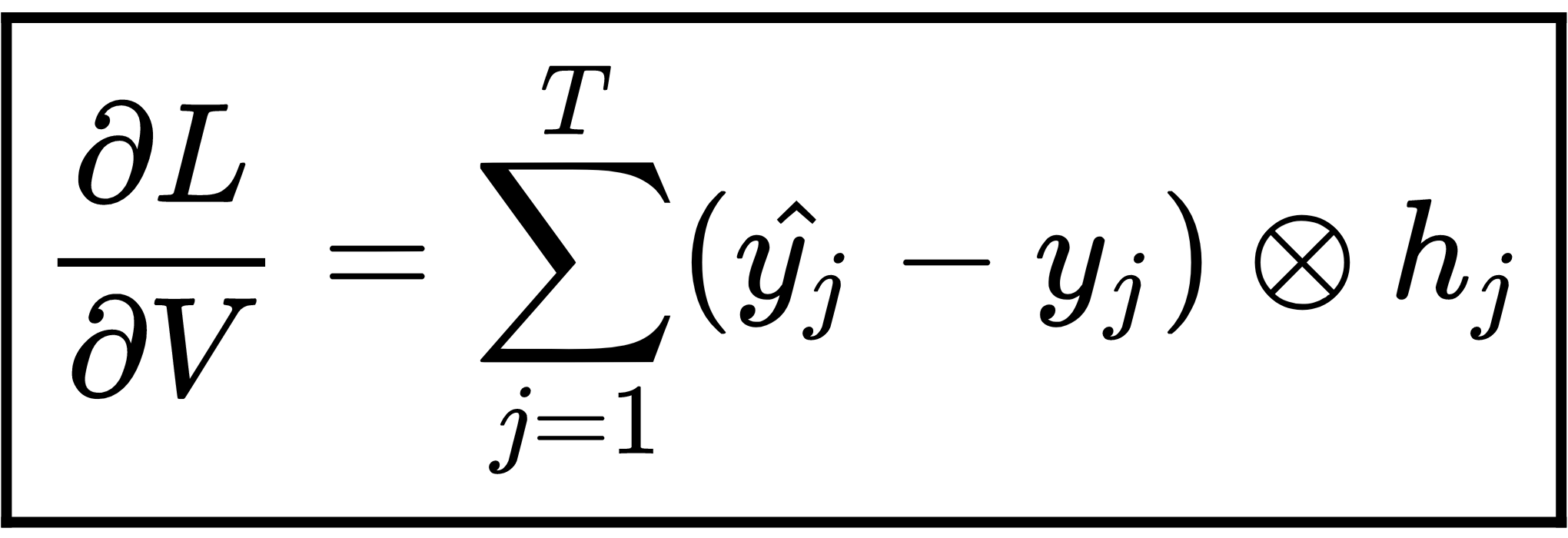Since the final equation of GRU, that is,  , is the same as with the RNN, calculating the gradients of loss with respect to hidden-to-output layer weight
, is the same as with the RNN, calculating the gradients of loss with respect to hidden-to-output layer weight  is exactly the same as what we computed in the RNN. Thus, we can directly write the following:
is exactly the same as what we computed in the RNN. Thus, we can directly write the following: