
We started off the chapter by understanding word embeddings and we looked at two different types of Word2Vec model, called CBOW, where we try to predict the target word given the context word, and skip-gram, where we try to predict the context word given the target word.
Then, we learned about various training strategies in Word2Vec. We looked at hierarchical softmax, where we replace the output layer of the network with a Huffman binary tree and reduce the complexity to 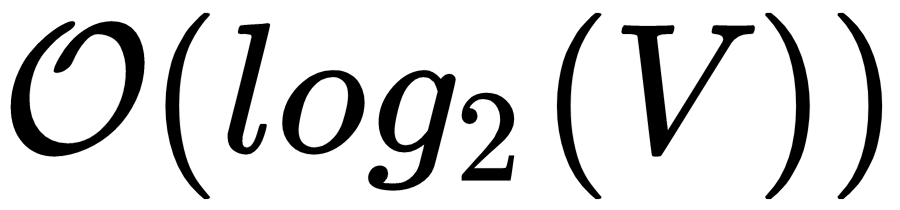 . We also learned about negative sampling and subsampling frequent word methods. Then we understood how to build the Word2Vec model using a gensim library and how to project the high-dimensional word embeddings to visualize them in TensorBoard. Going forward, we studied how the doc2vec model works with two types of doc2vec models—PV-DM and PV-DBOW. Following this, we learned about the skip-thoughts model, where we learn the embedding of a sentence by predicting the previous and next sentences of the given sentence and we also explored the quick-thoughts model at the end of the chapter.
. We also learned about negative sampling and subsampling frequent word methods. Then we understood how to build the Word2Vec model using a gensim library and how to project the high-dimensional word embeddings to visualize them in TensorBoard. Going forward, we studied how the doc2vec model works with two types of doc2vec models—PV-DM and PV-DBOW. Following this, we learned about the skip-thoughts model, where we learn the embedding of a sentence by predicting the previous and next sentences of the given sentence and we also explored the quick-thoughts model at the end of the chapter.
In the next chapter, we will learn about generative models and how generative models are used to generate images.