
We just learned how BPTT works, and we saw how the gradient of loss can be computed with respect to all the weights in RNNs. But here, we will encounter a problem called the vanishing and exploding gradients.
While computing the derivatives of loss with respect to  and
and  , we saw that we have to traverse all the way back to the first hidden state, as each hidden state at a time
, we saw that we have to traverse all the way back to the first hidden state, as each hidden state at a time  is dependent on its previous hidden state at a time
is dependent on its previous hidden state at a time  .
.
For instance, the gradient of loss  with respect to
with respect to  is given as:
is given as:

If you look at the term  from the preceding equation, we can't calculate the derivative
from the preceding equation, we can't calculate the derivative
of  with respect to
with respect to  directly. As we know,
directly. As we know,  is a function that is dependent on
is a function that is dependent on  and . So, we need to calculate the derivative with respect to , as well. Even
and . So, we need to calculate the derivative with respect to , as well. Even 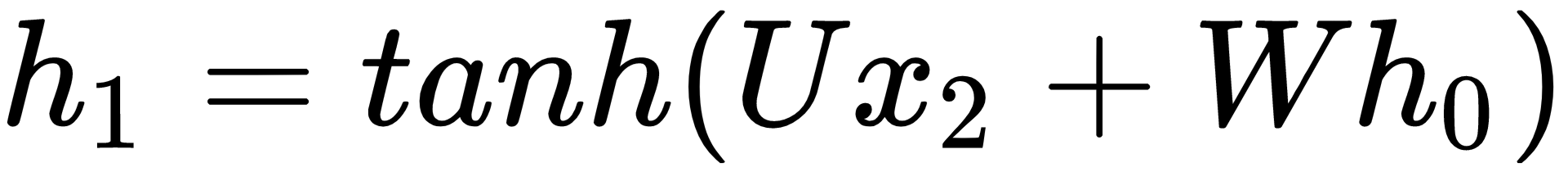 is a function that is dependent on
is a function that is dependent on  and . Thus, we need to calculate the derivative with respect to
and . Thus, we need to calculate the derivative with respect to  , as well.
, as well.
As shown in the following figure, to compute the derivative of  , we need to go all the way back to the initial hidden state
, we need to go all the way back to the initial hidden state  , as each hidden state is dependent on its previous hidden state:
, as each hidden state is dependent on its previous hidden state:

So, to compute any loss  , we need to traverse all the way back to the initial hidden
, we need to traverse all the way back to the initial hidden
state  , as each hidden state is dependent on its previous hidden state. Suppose that we have a deep recurrent network with 50 layers. To compute the loss
, as each hidden state is dependent on its previous hidden state. Suppose that we have a deep recurrent network with 50 layers. To compute the loss  , we need to traverse all the way back to , as shown in the following figure:
, we need to traverse all the way back to , as shown in the following figure:

So, what is the problem here, exactly? While backpropagating towards the initial hidden state, we lose information, and the RNN will not backpropagate perfectly.
Remember  ? Every time we move backward, we compute the derivative of
? Every time we move backward, we compute the derivative of  . A derivative of tanh is bounded to 1. We know that any two values between 0 and 1, when multiplied with each other will give us a smaller number. We usually initialize the weights of the network to a small number. Thus, when we multiply the derivatives and weights while backpropagating, we are essentially multiplying smaller numbers.
. A derivative of tanh is bounded to 1. We know that any two values between 0 and 1, when multiplied with each other will give us a smaller number. We usually initialize the weights of the network to a small number. Thus, when we multiply the derivatives and weights while backpropagating, we are essentially multiplying smaller numbers.
So, when we multiply smaller numbers at every step while moving backward, our gradient becomes infinitesimally small and leads to a number that the computer can't handle; this is called the vanishing gradient problem.
Recall the equation of gradient of the loss with respect to the  that we saw in the Gradients with respect to hidden to hidden layer weights, W section:
that we saw in the Gradients with respect to hidden to hidden layer weights, W section:

As you can observe, we are multiplying the weights and derivative of the tanh function at every time step. Repeated multiplication of these two leads to a small number and causes the vanishing gradients problem.
The vanishing gradients problem occurs not only in RNN but also in other deep networks where we use sigmoid or tanh as the activation function. So, to overcome this, we can use ReLU as an activation function instead of tanh.
However, we have a variant of the RNN called the long short-term memory (LSTM) network, which can solve the vanishing gradient problem effectively. We will look at how it works in Chapter 5, Improvements to the RNN.
Similarly, when we initialize the weights of the network to a very large number, the gradients will become very large at every step. While backpropagating, we multiply a large number together at every time step, and it leads to infinity. This is called the exploding gradient problem.