
Computing the gradients of the loss function with respect to  is the same as
is the same as  , since here also we take the sequential derivative of
, since here also we take the sequential derivative of  . Similar to , to compute the derivative of any loss
. Similar to , to compute the derivative of any loss  with respect to , we need to traverse all the way back to
with respect to , we need to traverse all the way back to  .
.
The final equation for computing the gradient of the loss with respect to is given as follows. As you may notice, it is basically the same as the equation (15), except that we have the term instead of
instead of 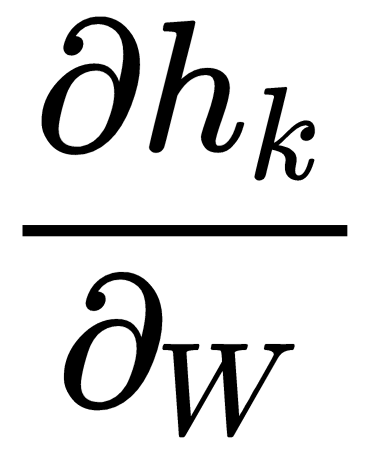 shown as follows:
shown as follows:

We have already seen how to compute to the first two terms in the previous section.
Let's look at the final term  . We know that the hidden state
. We know that the hidden state  is computed as,
is computed as,  . Thus, the derivation of
. Thus, the derivation of  with respect to
with respect to  becomes:
becomes:

So, our final equation for a gradient of the loss  , with respect to , can be written as follows:
, with respect to , can be written as follows:
