
In both the CBOW and skip-gram models, we used the softmax function for computing the probability of the occurrence of a word. But computing the probability using the softmax function is computationally expensive. Say, we are building a CBOW model; we compute the probability of the  word in our vocabulary to be the target word as:
word in our vocabulary to be the target word as:

If you look at the preceding equation, we are basically driving the exponent of the  with the exponent of all the words
with the exponent of all the words  in the vocabulary. Our complexity would be
in the vocabulary. Our complexity would be  , where
, where  is the vocabulary size. When we train the word2vec model with a vocabulary comprising millions of words, it is definitely going to be computationally expensive. So, to combat this problem, instead of using the softmax function, we use the hierarchical softmax function.
is the vocabulary size. When we train the word2vec model with a vocabulary comprising millions of words, it is definitely going to be computationally expensive. So, to combat this problem, instead of using the softmax function, we use the hierarchical softmax function.
The hierarchical softmax function uses a Huffman binary search tree and significantly reduces the complexity to  . As shown in the following diagram, in hierarchical softmax, we replace the output layer with a binary search tree:
. As shown in the following diagram, in hierarchical softmax, we replace the output layer with a binary search tree:

Each leaf node in the tree represents a word in the vocabulary and all the intermediate nodes represent the relative probability of their child node.
How do we compute the probability of a target word given a context word? We simply traverse the tree by making a decision whether to turn left or right. As shown in the following figure, the probability of the word flew to be the target word, given some context word  , is computed as a product of the probabilities along the path:
, is computed as a product of the probabilities along the path:


The probability of the target word is shown as follows:

But how do we compute these probabilities? Each node  has an embedding associated with it (say,
has an embedding associated with it (say,  ). To compute the probability for a node, we multiply the node's embedding with hidden layer value
). To compute the probability for a node, we multiply the node's embedding with hidden layer value  and apply a sigmoid function. For instance, the probability of a node
and apply a sigmoid function. For instance, the probability of a node  to take a right, given a context word
to take a right, given a context word  , is computed as:
, is computed as:

Once we computed the probability of taking right, we can easily compute the probability of taking left by simply subtracting the probability of taking right from 1:
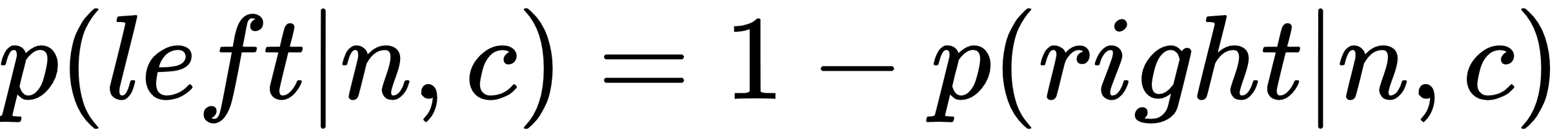
If we sum the probability of all the leaf nodes, then it equals to 1, meaning that our tree is already normalized, and to find a probability of a word, we need to evaluate only  nodes.
nodes.